首先说一下背景:
小组内的群博本来是有的,但是由于成员博客种类的不同,不同的博客平台提供的rss订阅的标签不相同,因而使用统一的抓取会因为标签的不同而终止。关于rss订阅的规范可以查看RSS2.0规范简易说明。
群博的页面链接是:西邮linux兴趣小组群博
一个简单的群博分为两个部分,一个是抓取的部分,一个是展示的部分,首先说一下抓取的部分。
博文的抓取
本身rss订阅会提供很多的信息供用户阅读,但是这里实现的是一个简单的群博系统,至于有多简单,要多简单有多简单,标准就是能看就行~~
首先是数据库的设计,当然了,吐槽一下,可能这里的数据库都算不上是在设计,没有考虑到范式的要求,只是为了单纯的完成博客系统的需求而已!好,那么博客系统的需求是什么呢?
如同前面所说的,写这个就是为了解决不同博客平台上的rss订阅标签不相同的问题,那么就必须有一个T_tags表,用来保存不同的标签(实际上是相同位置的标签的不同命名而已)。如下是T_tags表的结构:
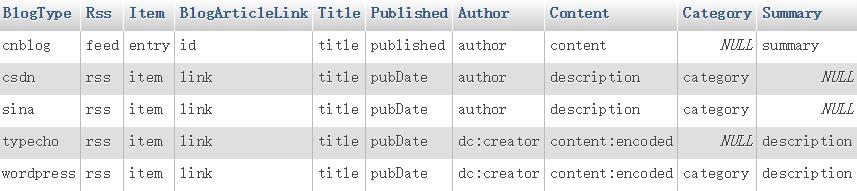
首先看一下这个表当中的字段是什么意思:
必须吐槽一下,关于数据库表以及字段的命名规范这里不是很标准,虽然这些没有硬性规定,但是可以参考一下数据库定义规范(可以借鉴,不是硬性标准准)
| 字段 | 作用 |
|---|---|
| BlogType | 博客类型 |
| Rss | 最外层rss的标签 |
| Item | 每篇博文的入口地址 |
| BlogAritcleLink | 博文的链接地址 |
| Title | 博文标题 |
| Published | 发布的日期 |
| Author | 作者 |
| Content | 博文内容 |
| Category | 标签,分类 |
| Summary | 摘要 |
这个表的作用就是在进行抓取时根据不同的博客类型选出rss订阅中实际使用的标签名称。
T_user表的结构如下:
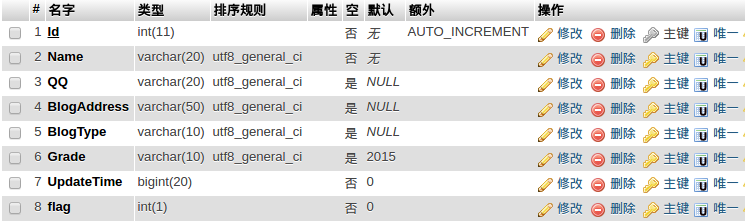
其中的UpdateTime字段用来表示更新的日期,由于rss订阅的显示顺序也是按照日期从近到远排列的,所以当抓取到某篇的更新时间早与上次抓取的更新时间时,默认再往后的内容已经抓取过了,不再进行抓取。
这里就又有一个Bug,若博文的内容进行更新了……到现在为止,还没有解决。。。。。
flag表示是否对该用户的博文进行抓取,T_user表是由管理员手动添加记录的,当某人的博客未开通时,或者博客rss订阅无法产生…总之无法进行抓取的时候就置flag为0,不进行抓取。
接下来是T_bloig表:
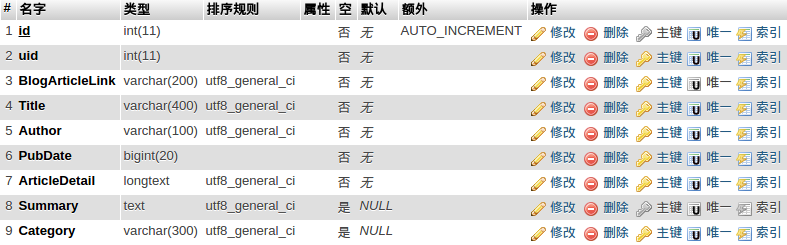
这个表中保存博文信息,Category字段是抓取到的博文的自定义分类,关于分类还有T_category表:

这个表比较简单,里面定义了一些常用的分类,本来是想用一些通用标签的,但是rss订阅不提供标签,所以就行不通了,只能自己自定义一些通用的标签,在查找时通过博文中的用户自定义的分类和标题是否含有该关键字来大致判断是否属于该标签。
数据库就是这四个表了:
然后简单看一下抓取工作的代码实现,具体的代码可以访问这里
说起来脑子其实挺乱的,大致就是下面这么一个流程:
数据库中取得所有用户的列表==>遍历这些用户==>判断用户的博客类型取得对应的rss订阅使用的标签==>根据用户的博客rss链接抓取博文==>保存
如下,是开始运行的文件,过程看注释就可以了:
public class Main {
public static void main(String[] args) {
doWork();
}
public static void doWork(){
//要执行的任务
TimerTask task = new TimerTask() {
@Override
public void run() {
try {
//为了将程序运行的输出保存成日志文件新建一个文件,并设置标准输出和错误输出
SimpleDateFormat dateFormat = new SimpleDateFormat("yy-MM-dd");
FileOutputStream fos = new FileOutputStream("./blog-log/blog.log-" + dateFormat.format(new Date()), true);
BufferedOutputStream bos = new BufferedOutputStream(fos, 1024);
PrintStream ps = new PrintStream(bos, true);
System.setOut(ps);
System.setErr(ps);
System.out.println(new Date());
//取得所有的成员列表
Collection<User> users = GetGroupUsers.getGroupusers();
//取得所有博客类型使用的标签,Tag类定义了所有要使用到的标签
Collection<Tag> tags = Tag.getAllTags();
//用来暂时保存抓取返回的博文集合
List blogContentInfos = new LinkedList<BlogContentInfo>();
GetContentInfo getContentInfo = null;
//遍历成员
for (User u: users) {
//判断要不要进行抓取
if(u.getFlag() == 0){
continue;
}
//遍历Tag集合,找到对应博客类型的Tag
for(Tag t : tags){
if(t.getBlogType().equals(u.getBlogType())){
//实例化一个获取博文信息的类,传入成员信息类和标签
getContentInfo = new GetContentInfo(u, t);
//使用刚才实例化的类获取博文的集合并将返回的集合保存
blogContentInfos.addAll(getContentInfo.getContentInfo());
break;
}
}
System.out.println(u.getId() + "/" + users.size());
//存储该用户的博文集合
BlogContentCrud.storeBlogContentCollection(blogContentInfos, u);
//清空博文集合
blogContentInfos.clear();
}
ps.close();
bos.close();
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
};
Calendar calendar = Calendar.getInstance();
int year = calendar.get(Calendar.YEAR);
int month = calendar.get(Calendar.MONTH);
int day = calendar.get(Calendar.DAY_OF_MONTH);
calendar.set(year,month,day, 6, 0, 0);
Date date = calendar.getTime();
Timer timer = new Timer();
//新建一个定时任务,每隔6小时执行一次task
timer.schedule(task, date, 1000 * 60 * 60 * 6);
}
}在这里可以注意到,使用的是定时任务的做法,博文的抓取肯定不能依靠用户自己手动执行抓取,所以这里使用了定时任务,每隔6小时自动抓取一次!
下面具体看一下给定一个链接和标签类如何实现博文的抓取,这里就使用到了dom解析了,为了完成文档的解析,我使用了如下的3个方法,看起来挺乱的~~~可以从第二个方法开始看!!
/**
* 给定一个输入流进行文档解析
* @param inputStream
* @return
*/
public List<BlogContentInfo> doDocumentBuild(InputStream inputStream){
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = null;
try {
builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException e) {
e.printStackTrace();
}
org.w3c.dom.Document document = null;
try {
document = builder.parse(inputStream);
} catch (SAXException e) {
e.printStackTrace();
return blogContentInfos;
} catch (IOException e) {
e.printStackTrace();
return blogContentInfos;
}
Element element = document.getDocumentElement();
NodeList items = element.getElementsByTagName(tag.getItem());
int flag = 1;
//对每篇博文进行解析得到博文的内容
for (int i = 0; i < items.getLength(); i++) {
//实例化一个新的博文实例
blogContentInfo = new BlogContentInfo();
blogContentInfo.setUid(u.getId());
Element item = (Element) items.item(i);
NodeList itemChildNode = item.getChildNodes();
for(int j = 0; j < itemChildNode.getLength(); j++){
//这一块已经具体化到一篇文章,根据不同的标签取得不同的信息,代码太过繁琐,可以在git上查看: https://github.com/zhuxinquan/JAVA/blob/master/GroupBlog/BlogGroup1.1.2/src/main/java/com/get_blog_content/GetContentInfo.java
}
blogContentInfos.add(blogContentInfo);
}
// DBUtils.close(rs, ps, conn);
return blogContentInfos;
}
public List<BlogContentInfo> getContentInfo() {
//使用HttpClient取得响应内容
System.out.println(u.getName());
HttpClient httpclient = new DefaultHttpClient();
HttpGet httpgets = new HttpGet(url);
httpgets.setHeader("User-Agent", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.0.3) Gecko/2008092417 Firefox/3.0.3");
HttpResponse response = null;
try {
response = httpclient.execute(httpgets);
} catch (IOException e) {
e.printStackTrace();
}
HttpEntity entity = response.getEntity();
Header hearder = entity.getContentType();
String charsetName = "UTF-8";
if(hearder != null){
String s = hearder.getValue();
if(s.matches("charset\\s?=\\s?(utf-?8)") || s.matches("charset\\s?=\\s?(UTF-?8)")){
charsetName = "UTF-8";
}else if(s.matches("(charset)\\s?=\\s?(gbk)") || s.matches("(charset)\\s?=\\s?(GBK)")){
charsetName = "GBK";
}else if(s.matches("(charset)\\s?=\\s?(gb2312)") || s.matches("(charset)\\s?=\\s?(GB2312)")){
charsetName = "GB2312";
}
}
String html = null;
if (entity != null) {
InputStream instreams = null;
try {
instreams = entity.getContent();
} catch (IOException e) {
e.printStackTrace();
}
html = convertStreamToString(instreams);
httpgets.abort();
}
// System.out.println(html);
//创建字节输入流
Reader reader = new StringReader(html);
InputStream inputStream = null;
// System.out.println(html);
try {
inputStream = new ByteArrayInputStream(html.getBytes(charsetName));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return doDocumentBuild(inputStream);
}
//将输入流转换为字符串
public static String convertStreamToString(InputStream is) {
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
StringBuilder sb = new StringBuilder();
String line = null;
try {
while ((line = reader.readLine()) != null) {
sb.append(line + "\n");
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return sb.toString();
}信息的抓取这一块,可以看一些dom解析的文章。
群博的后台处理
上面说的是博文信息的抓取,然后就是具体博文内容的展示了,首先这里使用的是JSP,主要有3个页面:主页,文章详情页,搜索页
主页就是根据不同的条件展现不同的文章列表,如果只是单纯的直接访问主页,则是从数据库中取出前十条最新的博文进行展示,其次就是可以根据成员、时间以及分类来查看主页的内容。
主页内容的实现是通过不同的条件拼接SQL语句形成的。当然SQL的拼接就有可能产生SQL注入,有关预防SQL注入的可以看一下这里:使用过滤器防止简单的页面SQL注入。
如下是index.jsp中根据请求参数的不同进行SQL拼接,然后进行查询的部分:
<%
String queryBlog = "select T_blog.Id, uid, Title, PubDate, ArticleDetail, Summary, Name from T_blog, T_user where T_user.Id = T_blog.uid ";
String pageNum = "1";
String condition = "";
String condition1 = "";
String uid = request.getParameter("uid");
String time = request.getParameter("time");
String category = request.getParameter("category");
if(uid != null){
condition = condition + "uid=" + URLEncoder.encode(uid) + "&";
condition1 = condition1 + " uid = " + uid + " ";
queryBlog = queryBlog + " and uid = " + uid + " ";
}
if(time != null){
//根据时间判断大月还是小月,确定其天数
condition = condition + "time=" + URLEncoder.encode(time) + "&";
Set<Integer> big = new HashSet<>();
big.add(0);
big.add(2);
big.add(4);
big.add(6);
big.add(7);
big.add(9);
big.add(11);
int year = Integer.parseInt(time.substring(0, 4));
int month = Integer.parseInt(time.substring(5, time.length())) - 1;
int days = 0;
if(month == 1){
if(year % 4 == 0 && year % 100 != 0 || year % 400 == 0){
days = 29;
}else{
days = 28;
}
}else if(big.contains(month)){
days = 31;
}else{
days = 30;
}
Long time1 = new Date(year, month, 1, 0, 0, 0).getTime();
Long time2 = new Date(year, month, days, 23, 59, 59).getTime();
condition1 = condition1 + " PubDate between " + time1 + " and " + time2 + " ";
queryBlog = queryBlog + " and PubDate between " + time1 + " and " + time2 + " ";
}
if(category != null){
String s = "'%" + category + "%'";
condition = condition + "category=" + URLEncoder.encode(category) + "&";
condition1 = condition1 + " category like " + s + " or title like " + s + " ";
queryBlog = queryBlog + " and ( category like " + s + " or title like " + s + ") ";
}
if(request.getParameter("page") != null){
pageNum = request.getParameter("page");
}
queryBlog = queryBlog + " order by PubDate desc limit " + String.valueOf((Integer.parseInt(pageNum) - 1) * 10) + ", 10 ";
try{
ps = conn.prepareStatement(queryBlog);
rs = ps.executeQuery();
}catch (Exception e){
rs = null;
}
while(rs != null && (rs.next() != false)){
//展示博文
}
%>这是博文数据库中查询的部分,JSP页面的展示具体的html代码再包含进最下方的while循环就可以了。
其他的后台处理也没有什么技术含量了,就是前端页面的展示了,毕竟博客内容已经保存进数据库了,所以整个群博系统的重点在于抓取,展示的部分套用了好多其他东西,比如csdn的markdown的样式,对于博文详情界面的显示非常有帮助。
具体页面可访问西邮linux群博系统
有点low,不足之处望指正!