前天看到了别人写的抓取斗鱼弹幕的程序,抓取斗鱼弹幕是我很早以前的一个想法,但是无奈不会写,不懂得tcp传过来的那些字节的含义,所以没写出来,当我看到别人写好的代码,我就参照人家的博客自己实现了一遍,今天我就想熊猫tv应该也是差不多的,所以自己写了一个抓熊猫TV弹幕的代码。
有想抓斗鱼弹幕的建议去看这个博客,有详细步骤
http://brucezz.github.io/articles/2016/01/11/douyu-crawler/
下面说抓取熊猫tv弹幕
(一)抓包分析

这个比斗鱼的简单多了,最开始只有两个要发送的包,只要把这两个发过去,就可以接收到弹幕了。
现在的问题是第一次发送的那些数据从哪来。
分两步:
(1)h ttp://www.panda.tv/ajax_chatroom?roomid=10255&_=1454038739756
得到
{
“errno”: 0,
“data”: {
“sign”: “e629e9eca8b561e0dbc2fbf2681e79f7”,
“roomid”: 10255,
“rid”: -35304032,
“ts”: 1454038744994
},
“errmsg”: “”
}
(2)h ttp://api.homer.panda.tv/chatroom/getinfo?rid=-35304032&roomid=10255&retry=0&sign=e629e9eca8b561e0dbc2fbf2681e79f7&ts=1454038744994&_=1454038740461
得到:
{
“errno”: 0,
“errmsg”: “”,
“data”: {
“rid”: -35304032,
“appid”: “18421055”,
“chat_addr_list”: [
“180.163.220.15:80”,
“180.163.220.15:80”
],
“ts”: 1454038745481,
“sign”: “fb4039b64439298bd6869cbec1bb1d0c”,
“authType”: “3”
}
}
这就是所有需要的数据了。其中还有弹幕服务器的地址,每次返回两个,有时候两个一样,有时候不一样,都可以用。
(二)发送数据的格式是什么?
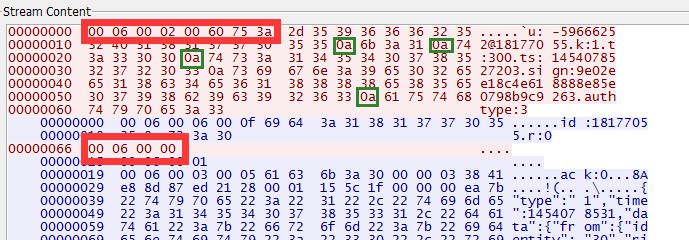
前面4个字节00 06 00 02是固定的,00 60代表后面参数的长度。注意的是后面参数之间都由回车符隔开。
第二个包其实是呼吸包,格式固定式00 06 00 00
(三)接收到的数据格式是什么?

每一条弹幕数据都是由 00 06 00 03这四个字节开头的,然后后面第8个字节开始4个字节是此次接收到的数据长度,计算方法如下:
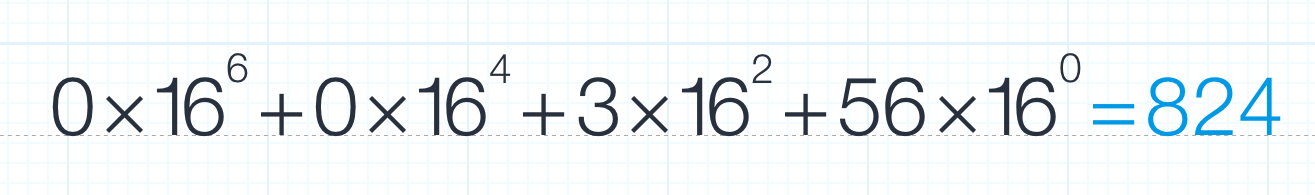
然后从41开始接收824个字节,就是这次的所有数据,这一次的数据里面可能有好几条弹幕信息,必须依次取出,每条弹幕开头的4个字节在单次数据中都是一样的,例如本次是01 15 5c 1f,这4个字节第一次出现位置是固定的,可以每次取出,然后比照着识别出每条弹幕信息的开头,这四个字节后面4个字节就是弹幕信息的长度了,计算方法同上,然后就可以得到一条弹幕信息了,类似下面这样的json串:
{
“type”: “1”,
“time”: 1454078535,
“data”: {
“from”: {
“identity”: “30”,
“rid”: “3604228”,
“__plat”: “pc_web”,
“nickName”: “翌江别鹤”,
“level”: “4”,
“userName”: “PandaTv3604228”
},
“to”: {
“toqid”: 1,
“toroom”: “10015”
},
“content”: “这图作者心理太阴暗了”
}
}
这就很明了了。
(四)呼吸包
维持socket连接用的,我抓包发现熊猫tv的呼吸包间隔时间很长,好像有5分钟,没精确计算过,我程序中用的是1分钟发一次呼吸包。
呼吸包就4个字节:00 06 00 00
这是今天一天的研究成果,分享之。
代码在:https://github.com/gaopu/Java/tree/master/CrawlPandaDanmu
包含idea的工程文件,可在idea中直接打开