% (1).编写一些导出单个函数的小模块,以及被导出函数的类型规范。
% 在函数里制造一些类型错误,然后对这些程序运行 dialyzer 并试着理解错误消息。
% 有时候你制造的错误无法被 dialyzer 发现,请仔细观察程序,找出没有得到预期错误的原因。
-module(minmodule).
-export([func1/3]).
-spec func1(number(), number(), number()) -> number().
func1(X, Y, Z) when is_list(X) ->
X+Y+Z.这里我列出了一个很简单的例子,如果不添加 -spec ,typer推断出类型是这样的:

明确指定后:

所以,我们一开始就应该使用类型注解明确指明类型。
dialyzer 分析:
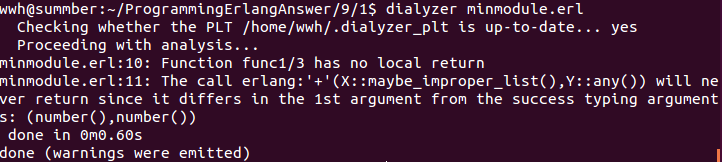
分析结果表示,X是一个list,Y是any,X,Y相加将不会返回。
使用dialyzer
用dialyzer来检查程序里的类型错误需要按照一种特定的工作流进行。不要不加任何类型注
解就编写完整个程序,然后当你感觉一切就绪后再回过头来到处添加类型注解并运行dialyzer。
这么做,很可能会见到大量让人困惑的错误,从而不知道该从哪里着手修复错误。
使用dialyzer的最佳方式是将它用于每一个开发阶段。开始编写一个新模块时,应该首先考
虑类型并声明它们,然后再编写代码。要为模块里所有的导出函数编写类型规范。先完成这一步
再开始写代码。可以先注释掉未完成函数的类型规范,然后在实现函数的过程中取消注释。
现在可以开始编写函数了,一次写一个,每写完一个新函数就要用dialyzer检查一下,看看
能否发现程序错误。如果函数是导出的,就加上类型规范;如果不是,就要考虑添加类型规范是
否有助于类型分析或者能帮助我们理解程序(请记住,类型注解是很好的程序文档)。如果dialyzer
发现了任何错误,就应该停下来思考并找出错误的准确含义。
% (2).观察标准库代码里的类型注解。找到lists.erl模块的源代码,
% 阅读里面所有的类型注解
% 随便贴几个注解
% keyfind,类型注解限定Key是`Term`, N是`pos_integer`,TupleList是`Tuple`,返回类型是 Tuple或者false
% when 是关卡,用来增强模式匹配的威力。
-spec keyfind(Key, N, TupleList) -> Tuple | false when
Key :: term(),
N :: pos_integer(),
TupleList :: [Tuple],
Tuple :: tuple().
-spec reverse(List1, Tail) -> List2 when
List1 :: [T],
Tail :: term(),
List2 :: [T],
T :: term().
-spec append(List1, List2) -> List3 when
List1 :: [T],
List2 :: [T],
List3 :: [T],
T :: term().
lists.erl代码路径是otp/lib/stdlib/src/lists.erl,我们可以git clone下来,Linux下 find . -name “lists.erl” 也可以找到该文件。
git地址
% (3).为什么在编写模块前需要先思考里面函数的类型?它是否在任何情况下都是一个好注意
% 因为 erlang 是解释型,动态的语言,它不像c/c++这种提前编译好,运行不会出错,
% 动态语言运行时没有类型检查,所以如果参数等错误会导致整个系统错误。
% 类型注解并非在任何情况下都是好注意,个人理解类型注解在运行时会进行检查,
% 这可能会导致性能速度下降。a.erl
% (4).对不同名类型做些试验。创建两个模块,第一个模块导出一个不同名类型,
% 第二个模块以能导致抽象违规的方式使用该不透明类型的内部数据结构。
% 在这两个模块上运行 dialyzer 并确保理解了错误消息。
-module(a).
-export_type([mylist/0]).
-type mylist()::list().
%-opaque mylist() :: list().
b.erl
-module(b).
-export([func/1]).
-spec func(tuple()) -> a:mylist().
func(Tuple) ->
L = tuple_to_list(Tuple),
[X*2 || X <- L].

这块暂时有些问题,我用type和opaque出来的结果一样。