记录一些python中数据结构的使用技巧。
主要是set,list,dictionary
问题1:
获取一段可迭代序列中的部分。
比如计算一个班的平均成绩,条件去除第一个和最后一个人
student_grades = [66,77,88,99,100]
计算(77+88+99)/3
问题2:
给定M个数,找到最大或者最小的N个元素
问题3:
在两个字典中寻找相同item(元素,也就是键值对)
问题4:
找出序列中出现次数最多的元素
问题5:
如何筛选序列中的元素
List = [-1, -2, -3, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
找出偶数
问题6:
同时对数据进行转换和换算
比如nums = [1,2,3,4,5,6]
将nums中的偶数求和
问题7:
给序列元素去重
比如List = [1,2,3,1,2,3,1,2,3]
问题1
使用*号表达式
*代表可变参数
单*号代表list
双*号代表字典dict
__author__ = 'wwh'
#一个可迭代的对象,获取其中指定的元素
#求平均值函数
def avg(mid):
sum = 0
for i in range(len(mid)):
print(i,mid[i])
sum += mid[i]
return sum/(i+1)
#去除首尾元素求平均值
def drop_first_last(grades):
# *号是可变参数,表示一个元组
# **号也是可变参数,表示键值对
first, *middle, last = grades
print(type(middle))
return avg(middle)
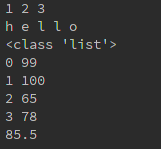
if __name__ == '__main__':
#任意可迭代的元素都可以分解为单独的变量
t = (1,2,3)
x,y,z = t
print(x,y,z)
s = 'hello'
a,b,c,d,e = s
print(a,b,c,d,e)
#给出一组成绩,求其平均值
student_grade = [88,99,100,65,78,66]
print(drop_first_last(student_grade))
问题2
这种题选取前n个最大,或者最小的元素,一般都建一个大顶堆或者小顶堆来解决。建完堆后需要n个数就类似堆排序那样每次选择堆顶元素。然后堆调整n次。如果共有m个数,时间复杂度是nlog(m)
但是注意,用堆只适合n比m小很多的情况下,如果近似的话排序效率会高些
python包含了heapq模块。内部思想就是上面说的。
其中
nlargest(n,args)是从args中找到前n个最大的数
nsmallest(n, args)是从args中找到前n个最小的数
__author__ = 'wwh'
import heapq
nums = [1,2,3,77,23,-12,0,100]
print(heapq.nlargest(3,nums))
print(heapq.nsmallest(3,nums))
#可以看一下heapq模块内部的方法
#print(dir(heapq))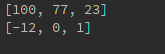
问题3:
利用字典的集合运算,字典也支持常见的集合运算,如
求并集,交集,差集等
注意python键和键-值支持集合运算,而值不支持,因为值不唯一。
__author__ = 'wwh'
a = {
'x':1,
'y':2,
'z':3
}
b = {
'w':10,
'x':11,
'y':2
}
#寻找key值相同的
print(a.keys() & b.keys())
#寻找key-value相同的
print(a.items() & b.items())
#字典推导式(python2.7引入),'-'是去除某item
c = {key:a[key] for key in a.keys() - {'z', 'w'}}
print(c)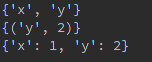
问题4:
使用collections某块中的Counter函数
底层实现中,Counter是一个字典,在元素和出现次数做了一个映射。且可以运算
collections模块基本介绍
我们都知道,Python拥有一些内置的数据类型,比如str, int, list, tuple, dict等, collections模块在这些内置数据类型的基础上,提供了几个额外的数据类型:
1.namedtuple(): 生成可以使用名字来访问元素内容的tuple子类
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
__author__ = 'wwh'
from collections import Counter
words = [
'look', 'into', 'he', 'she', 'is', 'my',
'you', 'into', 'hi', 'into', 'is', 'look',
'eyes', 'the', 'a'
]
#计数
word_count = Counter(words)
print(word_count)
#运算
word_count += word_count
print(word_count)
#获得出现次数最多的前3个值
top_three = word_count.most_common(3)
print(top_three)
问题5:
使用列表解析式,生成器表达式及字典推导式
expr是对过滤后的数据进行转换,cond_expr是过滤数据的条件
列表解析:[expr for iter_var in iterable if cond_expr]
生成器 :(expr for iter_var in iterable if cond_expr)
字典推导式:{expr fom iter_var in iterable if cond_expr}
注意:列表解析一个不足就是必要生成所有的数据,用以创建整个列表。这对大数据可能有负面影响。
生成器表达式并不创建数字列表,而是返回一个生成器,这个生成器在每次计算出一个条目后,把这个条目产生出来,生成器表达式使用了“延迟计算”,所以它在内存上更有效果。
__author__ = 'wwh'
#列表list过滤数据
List = [-1, -2, -3, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print([i for i in List if i > 0 and i%2 == 0])
print([i*2 for i in List if i > 0 and i%2 == 0])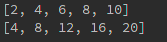
字典例子
__author__ = 'wwh'
fruit = {
'apple':10,
'banana':20,
'orange':5,
'pineapple':15
}
print({key:value for key, value in fruit.items() if 10 <= value <= 20})
问题6:
在sum等函数内部用生成器表达式
基于生成器可以以迭代的方式转换数据,内存使用上比较高效
__author__ = 'wwh'
nums = [1,2,3,4,5,6,7,8,9,10]
print(sum(i for i in nums if i%2 == 0))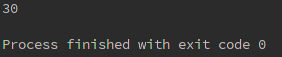
问题7:
__author__ = 'wwh'
List = [1,2,3,1,2,3,1,2,3]
#转换为set去重即可,set中默认不包含重复的元素
print(set(List))参考书籍《Python Cookbook》