前言:无论什么项目肯定都少不了日志系统,所以一个高性能的日志系统是不可避免的。
本文介绍的是自己用c++11实现的一个简单的多缓冲区日志系统,比较水,仅供参考^_^
主题:
- 日志系统及重要性
- 单缓冲日志系统模型及缺陷
- 多缓冲buffer介绍及优势
- 多缓冲区缺陷
- Buffer类设计及分析
- Logger类设计及分析
日志系统及重要性:
日志信息对于一个优秀项目来说是非常重要的,因为无论再优秀的软件都有可能产生崩溃或异常,此时,日志系统就能发挥它的作用。
快速定位到错误地点以及错误内容,或者查看最近信息等。
一般来说一个日志系统会分级写日志,比如INFO信息日志(用户的一些操作等),ERROR错误日志(系统崩溃或异常),FAIL失败日志(某项操作失败)等等。
由于日志系统非常重要,它会出现在我们程序的每个角落,所以一个好的日志系统就非常重要了,现存的有许多好的实现比如c++的log4,下面介绍是按自己的思路实现的一个非常简单的日志系统。
单缓冲日志系统模型及缺陷
最简单的日志系统就是单缓冲或者无缓冲的。
无缓冲:
无缓冲最简单,在个需要输出日志信息的地点都输出信息到文件并写入磁盘即可,但是注意现在程序一般都是并发执行,多进程或多线程写文件我们要加锁。
这样效率就比较低了,比如你有20个线程在运行,每次输出日志都要先抢到锁然后在输出,并且输出到磁盘本身就很慢,这样不仅输出日志效率低,更可能会影响到程序的运行(会阻塞程序,因为日志输出是无处不在的)。
单缓冲:
单缓冲就是我们开辟一块固定大小的空间,每次日志输出都先输出到缓冲中,等到缓冲区满在一次刷新到磁盘上,这样相比较无缓冲效率提高了一些,不用每次都输出到磁盘文件上,待到一定数量再刷新到磁盘上。但是每次输出到日志文件上的线程或进程都要加锁,还是存在一个抢锁的过程,效率也不高。
模型如下
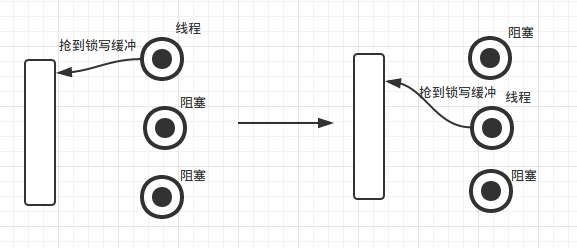
从上图能看出来,每次写缓冲还是存在抢锁和阻塞的过程,这样效率还是比较低的,相对无缓冲来说,仅仅减少了磁盘IO的次数。但在磁盘IO时,程序依旧会阻塞
磁盘IO依旧是瓶颈
多缓冲 buffer介绍
既然单块缓冲满足不了我们的要求,效率依然比较低,那么我们可以尝试选择多块缓冲来实现。程序只关注当前缓冲,其余多块缓冲交给后台线程来处理。
模型如下
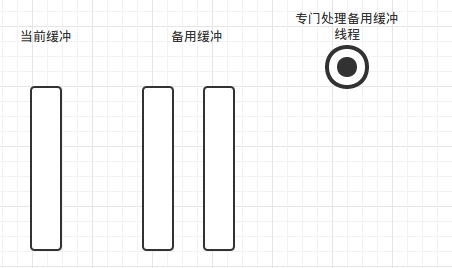
当前缓冲为我们程序写缓冲Buffer,备用缓冲Buffer为我们提前开辟缓冲,当当前curBuf缓冲满时交换Buffer。如下图
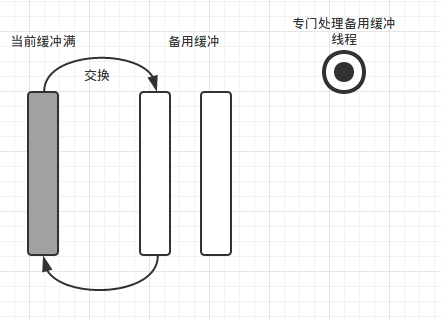
在实际中我们用指针来操控(代码中我使用的std::shared_ptr,只用交换指针即可),交换完毕后如下图
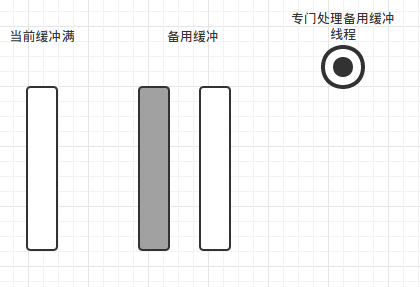
此时,我们可以唤醒后台线程处理已满缓冲,当前缓冲交换后为空,程序可以继续写当前缓冲而不会因为磁盘IO而阻塞。
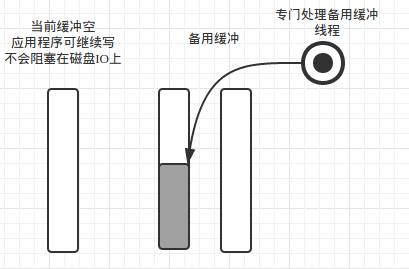
如果程序写日志速度非常快,我们可以开大缓冲,或者将当前缓冲设置为两块,备用缓冲可设置为多块,在实际编写程序时,因为我用的是
list<std::shared_ptr>这种结构来保存,当备用缓冲不够时,会创建一块,然后list会自动push_back,这样慢慢程序会达到最适应自己的缓冲大小。
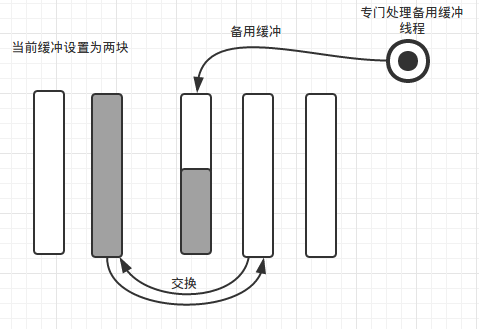
优势很明显了,我们程序只管写,一切由后台线程来完成,不会阻塞在磁盘IO上。
多缓冲区缺陷
多缓冲区设计是有缺陷的,相比较单缓冲是避免了磁盘IO这一耗时的操作,但如果程序写日志量非常大时,每次写curBuf当前缓冲都要先抢锁,可见效率之低,等待锁的时间耗费非常大。多个线程或进程操作一块或两块缓冲,锁的颗粒度非常大。我们可以尝试减小锁的颗粒度
解决方案可以参考Java的ConcurrentHashMap原理,ConcurrentHashMap是内部建立多个桶,每次hash到不同的桶中,锁只锁相应的桶,那么等于减少了锁的颗粒度,阻塞在锁上的频率也就大大降低。
如下图
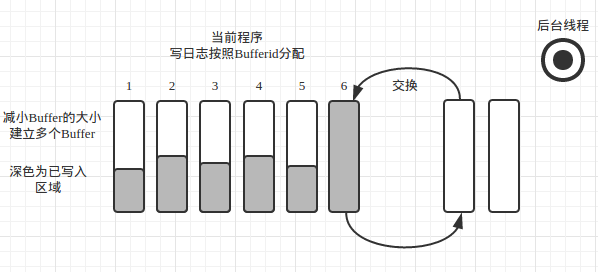
当前程序Buffer开辟多个,类似多个桶,锁只锁相应的桶即可,减小了锁的颗粒度
这么做算已时间换空间了,然后如果没有这么大需求上面方案即可解决。
Buffer类设计及分析
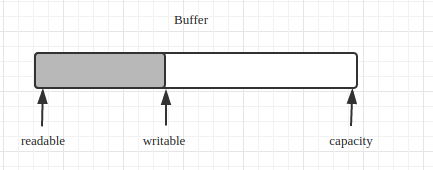
Buffer类的设计参考了netty中的buffer,一块缓冲,三个标记分别为可读位置readable,可写位置writable,容量capacity。
其实readable和writable位置都为0,capacity为容量大小。
写缓冲时writable移动,读缓冲时readable移动,writable <= capacity。
缓冲区我使用了vector<char>,参考了陈硕前辈的muduo,使用vector<char>一方面它内部和数组是一样的,其次我们还可以借助vector特性来管理它。Buffer类比较简单
class Buffer
{
/* 初始化默认大小 */
static size_t initializeSize;
public:
/* 构造函数,初始化buffer,并且设置可读可写的位置 */
explicit Buffer(size_t BufferSize = initializeSize):
readable(0), writable(0)
{
/* 提前开辟好大小 */
buffer.resize(BufferSize);
}
/* 返回缓冲区的容量 */
size_t Capacity()
{
return buffer.capacity();
}
/* 返回缓冲区的大小 */
size_t Size()
{
return writable;
}
/* set Size */
void setSize(void)
{
readable = 0;
writable = 0;
}
/* 向buffer中添加数据 */
void append(const char* mesg, int len)
{
strncpy(WritePoint(), mesg, len);
writable += len;
}
/* 返回buffer可用大小 */
size_t avail()
{
return Capacity()-writable;
}
private:
/* 返回可读位置的指针 */
char* ReadPoint()
{
return &buffer[readable];
}
/* 返回可写位置的指针 */
char* WritePoint()
{
return &buffer[writable];
}
/* 返回可读位置 */
size_t ReadAddr()
{
return readable;
}
/* 返回可写位置 */
size_t WriteAddr()
{
return writable;
}
private:
std::vector<char> buffer;
size_t readable;
size_t writable;
};Logger类设计及分析
Logger类我的实现遵从与刚才说的多缓冲模型。
curBuf为一块,备用Buffer为两块,并且可自适应改变。
class Logger
{
public:
/* 创建日志类实例 */
static std::shared_ptr<Logger> setLogger();
static std::shared_ptr<Logger> setLogger(size_t bufSize);
/* 得到日志类实例 */
static std::shared_ptr<Logger> getLogger();
/* 按格式输出日志信息到指定文件 */
static void logStream(const char* mesg, int len);
private:
/* shared_ptr智能指针管理log类 */
static std::shared_ptr<Logger> myLogger;
/* 当前缓冲 */
static std::shared_ptr<Buffer> curBuf;
/* list管理备用缓冲 */
static std::list<std::shared_ptr<Buffer>> bufList;
/* 备用缓冲中返回一块可用的缓冲 */
static std::shared_ptr<Buffer> useFul();
/* 条件变量 */
static std::condition_variable readableBuf;
/* 后台线程需要处理的Buffer数目 */
static int readableNum;
/* 互斥锁 */
static std::mutex mutex;
/* 后台线程 */
static std::thread readThread;
/* 线程执行函数 */
static void Threadfunc();
static void func();
/* 条件变量条件 */
static bool isHave();
};从上面代码可以看出当前Buffer和备用Buffer都用智能指针来管理,我们不用操心资源释放等问题,因为为指针,当前Buffer和备用Buffer交换起来速度非常快。
初始化函数
std::shared_ptr<Logger>
Logger::
setLogger()
{
if(myLogger == nullptr)
{
/* 创建日志类 */
myLogger = std::move(std::make_shared<Logger>());
/* 创建当前Buffer */
curBuf = std::make_shared<Buffer>();
/* 创建两块备用Buffer */
bufList.resize(2);
(*bufList.begin()) = std::make_shared<Buffer>();
(*(++bufList.begin())) = std::make_shared<Buffer>();
}
return myLogger;
}都是由智能指针来管理
useful类,返回一个可用的备用Buffer
std::shared_ptr<Buffer>
Logger::
useFul()
{
auto iter = bufList.begin();
/* 查询是否存在可用的Buffer */
for(; iter != bufList.end(); ++iter)
{
if((*iter)->Size() == 0)
{
break;
}
}
/* 不存在则创建一块新Buffer并返回 */
if(iter == bufList.end())
{
std::shared_ptr<Buffer> p = std::make_shared<Buffer>();
/* 统一使用右值来提高效率 */
bufList.push_back(std::move(p));
return p;
}
return *iter;
}这算是自适应过程了,随着程序的运行会返回适应的大小。
logStream写日志类
void
Logger::
logStream(const char* mesg, int len)
{
/* 上锁,使用unique_lock为和condition_variable条件变量结合 */
std::unique_lock<std::mutex> locker(mutex);
/* 判断当前缓冲是已满,满了则与备用缓冲交换新的 */
if(curBuf->avail() > len)
{
curBuf->append(mesg, len);
}
else
{
/* 得到一块备用缓冲 */
auto useBuf = useFul();
/* 交换指针即可 */
curBuf.swap(useBuf);
/* 可读缓冲数量增加 */
++readableNum;
/* 唤醒阻塞后台线程 */
readableBuf.notify_one();
}
}线程主要执行函数
void
Logger::func()
{
std::unique_lock<std::mutex> locker(mutex);
auto iter = bufList.begin();
/* 如果备用缓冲并无数据可读,阻塞等待唤醒 */
if(readableNum == 0)
{
readableBuf.wait(locker, Logger::isHave);
}
/* 找数据不为空的Buffer */
for(; iter != bufList.end(); ++iter)
{
if((*iter)->Size() != 0)
break;
}
/* 如果到末尾没找到,没有数据可读 */
if(iter == bufList.end())
{
return;
}
else
{
/* 将满的缓冲写到文件中 */
int fd = open("1.txt", O_RDWR | O_APPEND, 00700);
if(fd < 0)
{
perror("open error\n");
exit(1);
}
write(fd, iter->get(), (*iter)->Capacity());
/* 清空缓冲 */
bzero(iter->get(), (*iter)->Capacity());
/* 归位readable和writable */
(*iter)->setSize();
/* 可读缓冲数量减1 */
--readableNum;
}
}仅仅是一个简单的实现,如有更优方案或错误还望指出,谢谢~
完