由于最近项目要用到数据库连接池,所以今天简单的聊聊~,
这个话题的引起是因为我在写mysql数据库部分时产生了一个疑问,一般后台处理数据部分,服务端是创建一个connection连接到数据库,然后所有的请求通过这一个connection来访问数据库,还是每个连接创建一个connction?这个连接需要维持多久?…接下来一起看看
首先目录1,2是为了引出下面的连接池,因为一般我们仅仅是使用数据库,而忽略了一些内在的东西,这就可能会出现一些效率方面的问题。4,5连接池的使用和最优连接池配置选择我在下一篇博客介绍。
总目录:
-1.数据库连接过程是怎样的?
-2.连接所占用的资源有哪些?
-3.连接池简介
-4.连接池的使用
-5.最优连接池配置选择
1.数据库的连接过程是怎样的?
数据库本身也是有一个server端程序在跑的,可以这么说它也是一个后台服务端的程序,我使用的是mysql,在/etc/init.d下面有个mysql.server,开机即启动mysql服务器。
我们一般使用mysql -uroot -p只不过是使用了管理员的身份来创建一个connection,从而登录mysql。
下面仔细说说mysql连接过程
mysql连接分为两种,一种为unix domain socket,另外一种为基于tcp/ip协议,一般我们如果远程访问数据库肯定是基于tcp/ip的,但是如果我们在本机登录就会分为使用socket还是tcp/ip。
socket:mysql -h localhost -uroot -p或者mysql -uroot -p
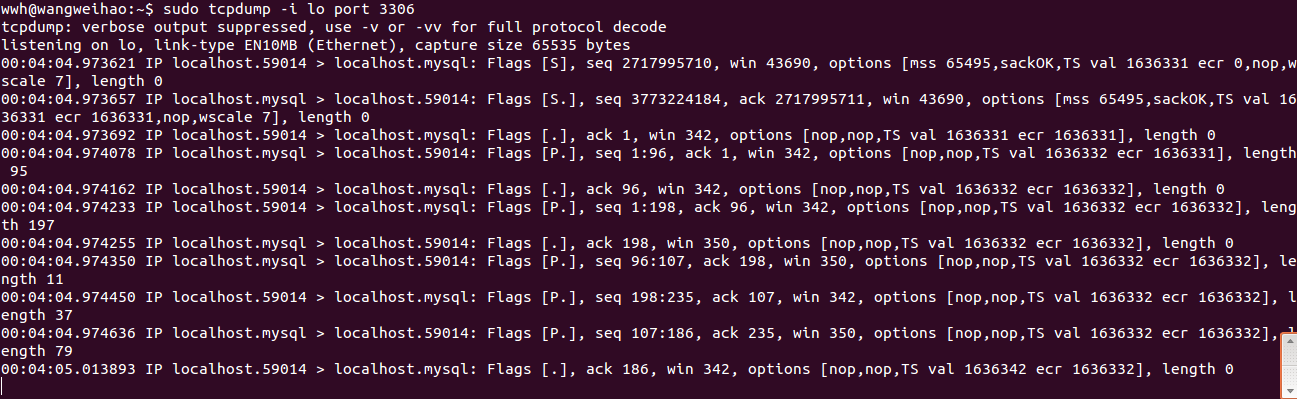
tcp/ip :mysql -h 127.0.0.1 -uroot -p为了证明,我用tcpdump抓个包看看^_^
socket:

可以看到unix domain socket并没有被抓到,因为它是不经过网卡的,本地的。
tcp/ip:
tcp/ip就抓到数据了,由此我们可以看出mysql的连接过程,内部实际上是经过tcp/ip协议的,当然mysql封装了tcp/ip有自己的一套协议。
下面我每执行一条sql语句都会有对应的数据包,那么很明显了mysql的连接方式和通信方式,在退出mysql时抓到了4条数据,4次挥手呗。
据官网说unix domain socket连接快于tcp/ip连接
A MySQL client on Unix can connect to the mysqld server in two different ways: By using a Unix socket file to connect through a file in the file system (default /tmp/mysql.sock), or by using TCP/IP, which connects through a port number. A Unix socket file connection is faster than TCP/IP, but can be used only when connecting to a server on the same computer. A Unix socket file is used if you don’t specify a host name or if you specify the special host name loc -alhost.`
所以同一台电脑上我们就使用unix domain socket吧~其次,mysql是会创建一个线程来处理到来的连接的,我们可以在mysql中show status;然后在连接mysql,再次show status就可以看到Thread_connected的数量会增加1,说明创建了一个线程来处理这个连接。
看上图,我们可以看到Threads_connected连接数是1,因为此时只有我一个在连接mysql,Threads_created为3,说明曾经有3个connection连接过数据库,Threads_cached这个是mysql为了提高性能而在内部提供了一个线程的连接池,将空闲的连接不是立即销毁而是放到线程连接池中,如果新加进来连接不是立刻创建线程而是先从线程连接池中找到空闲的连接线程,然后分配,如果没有才创建新的线程。可见mysql内部已经为我们做优化了。
Threads_catched值不是无限大的,一般为32左右。
顺便说一句,mysql是可以调整单线程和多线程模式的,单线程只允许一个线程连接mysql,其他连接将会被拒绝。
| thread_handling | one-thread-per-connection |

总结并补充上面,那么数据库连接的大致为:
1.应用数据层向DataSource请求数据库连接
2.DataSource使用数据库Driver打开数据库连接
3.创建数据库连接,内部可能创建线程,打开TCP socket
4.应用读/写数据库
5.如果该连接不再需要就关闭连接
6.关闭socket连接过程就简单的说到这。
2.连接所占用的资源有哪些?
mysql连接所占资源有哪些?
从上面可以看出来我们一般写的网络程序都是基于tcp/ip连接访问数据库的,先说下mysql是有最大连接数的。输入/usr/bin/mysqladmin -uroot -p variables | grep max_connections
我的mysql最大连接数是151,我们可以更改配置文件来改变最大连接数限制,但是否真的好,有待讨论,因为系统默认设定肯定会根据系统所能承受的连接或者是给予的资源等等来限定。所以我们就假设不改变参数的情况下所能提供的连接是151。
首先mysql每个连接是会创建一个线程的,可以登录mysql输入show status查看Threads_connected和Threads_created的大小,那么我们每连接一次mysql就会创建一个线程,每次断开又会销毁一个线程。
我们都知道创建线程和销毁线程的资源消耗是非常大的,不然也不会有线程池这个东西了,那么!从某个角度来看,连接池避免了频繁的创建连接和销毁连接(前面我们知道mysql已经做了Threads_catched优化,但是还不够),其实内部也避免了频繁的创建线程和销毁线程!是不是很类似线程池?,就像我的一个学长说的,××池名字听起来很高大上,其实就那么回事,原理是相通的,原理很重要。
那么线程创建和销毁,以及消耗的资源我们应该很熟悉了。
首先每个线程会分配栈空间,可以通过ulimis -s来查看,我的ubuntu 14.04默认是8M,那么100个连接就是800M,很吃内存的。其次mysql数据库会为每个连接分配连接缓冲区和结果缓冲区,也是要消耗时间的。接着每次每个连接都会进行tcp3次握手和断开时的4次挥手,分配一些缓存之类的空间,记得曾经看过一点点关于协议栈的东西,里面的数据结构,等待队列之类感觉也蛮复杂的,且虽然tcp连接耗费的资源不多,分配的时间也短,但如果我们能够节省岂不是更好~(关于tcp连接和断开资源消耗我并没有深究,抽空再补充吧~,感兴趣大家可以查下资料)。

3.连接池简介
呼~终于到了主题连接池了,其实前面说了这么多都是为了突出连接池的好……
数据库连接池技术的思想非常简单,将数据库连接作为对象存储在一个Vector对象中,一旦数据库连接建立后,不同的数据库访问请求就可以共享这些连接,这样,通过复用这些已经建立的数据库连接,可以克服上述缺点,极大地节省系统资源和时间。
也就是我们提前创建好这些连接,然后需要用去取连接即可。和线程池的思想是一致的。
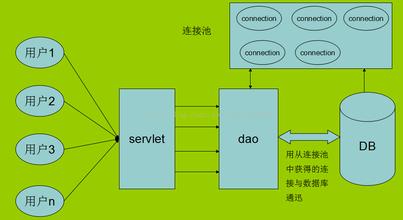
(图片来源网络)
连接池的操作:
(1)建立数据库连接池对象(服务器启动)。
(2)按照事先指定的参数创建初始数量的数据库连接(即:空闲连接数)。
(3)对于一个数据库访问请求,直接从连接池中得到一个连接。如果数据库连接池对象中没有空闲的连接,且连接数没有达到最大(即:最大活跃连接数),创建一个新的数据库连接。
(4)存取数据库。
(5)关闭数据库,释放所有数据库连接(此时的关闭数据库连接,并非真正关闭,而是将其放入空闲队列中。如实际空闲连接数大于初始空闲连接数则释放连接)。
(6)释放数据库连接池对象(服务器停止、维护期间,释放数据库连接池对象,并释放所有连接)。
这篇就简单的介绍到这里,下篇会介绍连接池的使用和它的配置问题。
谢谢观看~