关联容器支持高效的查找和访问,它和其他容器类型不同,是通过键值来访问元素的,
两个主要的关联容器是map和set,map中的元素是键->值对应, set中的元素光是键。
按关键字有序保存元素
map 关联数组:保存关键字-值对应 头文件map
set 关键字既值,既只保存关键字的容器 头文件set
multimap 关键字可重复出现的map 头文件map
multiset 关键字可重复出现的set 头文件set
无序集合
unordered_map 用hash函数组织的map 头文件unordered_map
unordered_set 用hash函数组织的set 头文件unordered_set
unordered_multimap hash组织的map:关键字可重复出现 头文件unordered_map
unordered_multiset hash组织的set:关键字可重复出现 头文件unordered_set
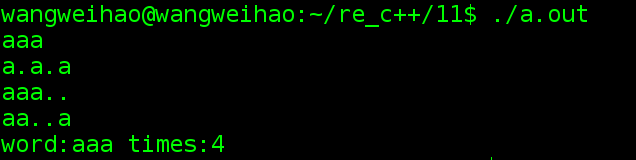
查看输入单词中每个单词出现的次数,忽略大小写和标点。
#include <iostream>
#include <map>
#include <string>
#include <algorithm>
using namespace std;
bool isshorter(char a, char b)
{
return a > b;
}
int main()
{
map<string, size_t>word_count;
string word;
string s(",.");
string::size_type pos;
while(cin >> word)
{
//转换成小写
transform(word.begin(), word.end(), word.begin(), ::tolower);
//auto cnt = count_if(word.begin(), word.end(), ::isalpha); //第一种去除标点,但是标点只能像题上给的在末尾
//word.erase(cnt, word.size()-cnt);
while((pos = word.find_first_of(s)) != string::npos) //第二种去除标点,位置都可以。在string操作里有。
{
word.erase(pos, 1);
}
++word_count[word];
}
for(const pair<string, size_t> &p : word_count)
{
cout << "word:" << p.first << " times:" << p.second << endl;
}
}
find_first_of在string操作里,温故!
关联容器不支持顺序容器的操作,原因我们通过键值来访问,这些操作对关联容器没有意义。
关联容器的迭代器都是双向的。
1.定义关联容器。
<1.当定义一个map时,必须指定键值和值,定义一个set时,指定键值即可。
每个关联容器定义了构造函数,创建一个指定类型的空类型。也可以初始化为一个容器的拷贝。或者一个范围的元素拷贝。
map<string, int>mp = {"aa", 1, "aaa", 2, "22", 33 }; error:map容器必须用{key, value}包含起来
map<string, int>mp = {{"aa", 1}, {"aaa", 2}, {"22", 33}}; 正确
初始化multimap和multiset
一个map和set中的关键字是唯一的,既对于一个给定的关键字,只能有一个元素关键字等于它。
容器multimap和multiset没有限制,可以一个关键字对应多个值
set容器可以作为简单的去重作用。
<2.使用关键字类型的比较函数
对于有序容器map,multimap, set, multiset,关键字类型必须定义元素的比较方法。默认情况下,标准库使用关键字类型<运算符来比较两个关键字。
#include <iostream>
#include <map>
using namespace std;
int main()
{
map<int, int>mp;
pair<int, int>pr;
mp.insert(make_pair(3,1));
mp.insert(make_pair(2,1));
mp.insert(make_pair(4,1));
for(const pair<int,int>&p:mp)
cout << p.first << " " << p.second << endl;
}
插入时是无序的,但是结果输出是有序的。
现在我们要自己定义比较操作符
顺便复习了下函数指针的几种表示
注意!所定义的比较操作符函数需要通过函数指针来调用,而函数指针定义在容器的键值和值之后,包括set,map,multiset,multimap等,
然后要在定义好的容器后面初始化函数指针。
#include <map>
#include <iostream>
using namespace std;
using ff = bool(*)(int a, int b);
bool compareIsbn(int a, int b)
{
return a > b;
}
int main()
{
//定义加初始化。
//map<int, int, decltype(compareIsbn)*>mp(compareIsbn);
//map<int, int, ff>mp(compareIsbn);
map<int, int, bool(*)(int a, int b)>mp(compareIsbn);
mp.insert(make_pair(3,1));
mp.insert(make_pair(2,1));
mp.insert(make_pair(4,1));
for(const pair<int,int>&p : mp)
{
cout <<p.first << " " << p.second << endl;
}
}
<3.pair类型:定义在标准库#include <utility>里
pair是map容器的单独元素类型。
一个pair保存两个数据成员,一个是first,一个是second.
pair的默认构造函数对数据成员进行值初始化。
也可以显示提供初始化,初始值列表等等。
和其他标准库不同,pair的数据成员是public,为first和second,我们用普通的成员访问符来访问他们。
<<1.pair上的操作
#include <map>
#include <iostream>
#include <string>
using namespace std;
int main()
{
map<string, int>mp;
pair<string, int>p; //默认初始化 pair<T1,T2>p; 根据T1,T2的类型来初始化
pair<string, int>p2("1",1); //值初始化 pair<T1,T2>p(v1,v2);
pair<string, int>p3{"2",2}; //列表初始化 pair<T1,T2>p = {v1,v2};
pair<string, int>p4 = {"3",3};
mp.insert(p);
mp.insert(p2);
mp.insert(p3);
mp.insert(p4);
mp.insert(make_pair("4",4)); //make_pair(v1,v2)返回一个用v1,v2来初始化的pair。类型从参数推断出来。 make_pair(v1,v2);
for(const pair<string,int>&p : mp)
{
cout << p.first << " " << p.second << endl;//pair的public的first和second成员
}
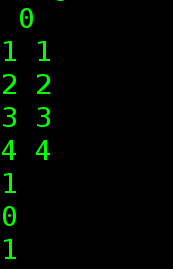
cout << (p2 < p3 ) << endl;//支持比较运算符,是依次比较first和second成员。记得带括号。
cout << (p2 == p3) << endl;
cout << (p2 != p3) << endl;
}
!注意 map没有first和second成员!
!访问map里的pair可通过下标访问。键值作为索引
!map<类型>mp 那么他的pair是pair<类型>p,中间的类型一样。
!最好使用make_pair来构建pair。
!普通map里面的pair的key值不能修改是const类型的。
2.关联容器的操作。
<1.
key_type 此容器的关键字类型
mapped_type 每个关键字关联的类型,只适用于map
value_type 对于set,和key_type相同
对于map,为pair<const key_type, mapped_type>
看看STL里的map定义

set

只有map(unorder_map, unorder_multimap, multimap)才定义了mapped_type
<2.map容器中的一个元素pair<T1,T2>,类型是map::value_type,切可以修改pair的值,不能修改关键字,关键字是const类型
cout << ++mp.begin()->first << endl; //读取begin()下一个元素的first,会提示error,->的优先级高,而且first是const不能修改,需要添加括号
set容器的迭代器是const的,虽然set同时定义了iterator和const_iterator但是两种类型都是只允许只读访问set中的元素。一个set
中的关键字也是const的。可以用迭代器来读取,不能修改。
<3.关联容器和算法
通常不能对关联容器使用算法,关键字是const这一特性意味着不能将关联容器传递给修改或重排容器元素的算法,这类算法要向容器中写入值。
set类型的键值是const,map中的元素是pair,第一个成员是const。
关联容器可用于只读算法,但是要注意效率问题。使用关联容器自带的算法如find会比algorithm库里的find算法效率高。
实际编程中,如果要对一个关联容器使用算法,要么是当作一个源序列,要么当作一个目标序列。
可以通过copy算法加inserter来执行
看下面那个是错误的。
copy(ivec.begin(), ivec.end(), inserter(mst, mst.end()));
copy(ivec.begin(), ivec.end(), back_inserter(mst)); //error
copy(mst.begin(), mst.end(), inserter(ivec, ivec.begin()));
copy(mst.begin(), mst.end(), back_inserter(ivec));在对容器使用算法的时候,想清除是否支持,从内部考虑。就像back_inserter需要有push_back操作。
<4.添加元素
insert对set,map添加元素,添加重复的元素对这两个容器没有其他影响。
insert有两个版本,分别接受一对迭代器和一对参数列表
insert(ivec.begin(), ivec.end());
insert({1,2,3,4,5,6,7});map的元素类型是pair
四种方法
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main()
{
map<string,int>mp;
string s1 = "a",s2 = "b",s3 = "c",s4 = "d";
int a = 1,b = 2,c = 3,d = 4;
mp.insert(make_pair(s1,a)); //1.make_pair创建一个pair
mp.insert({s2,b}); //2.c++11 创建一个pair最简单的方法是在参数列表中使用花括号初始化。
mp.insert(pair<string,int>(s3,c)); //3.构建一个pair类型
mp.insert(map<string,int>::value_type(s4,d)); //4.构建一个pair类型
for(const pair<string,int>&p : mp) //范围for引用必须要加const,因为pair的键值是const的。
{
cout << p.first << " " << p.second << endl;
}
}<5.关联容器的添加操作和返回值。
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main()
{
map<string,int>mp;
map<string,int>mp2 = {{"c",3}, {"d",4}}; //列表初始化
mp.insert({"a", 1}); //c.insert(v);
mp.emplace("b", 2); //c.emplace(args); args是参数列表,返回一个pair,包含一个迭代器,指向关键字的元素,以及一个bool表示是否成功
mp.insert(mp2.begin(), mp2.end()); //c.insert(b,e); b,e是迭代器,表示一个c::value_type类型值的范围。
mp.insert({{"e",5},{"f",6}}); //c.insert(il); il是初始值列表
auto ret = mp.insert(mp.end(), {"g",7});
auto ret2 = mp.insert({"a", 1});
auto ret3 = mp.insert({"i", 9});
mp.emplace_hint(mp.end(), "h",8); //c.hint_emplace(p,v); p是迭代器表示位置。
for(const pair<string,int>&p : mp)
cout << p.first << " " << p.second << endl;
cout << "return:" << ret->first << " bool:" << ret->second << endl;
cout << "return:" << ret2.first->first << " " << ret2.first->second << " bool:" << ret2.second << endl;
cout << "return:" << ret3.first->first << " " << ret3.first->second << " bool:" << ret3.second << endl;
} 
插入返回值只针对insert单一参数版本。代码中指定迭代器的版本返回的是插入的pair
对于不包含重复关键字的容器,添加单一元素的insert和emplace版本返回一个pair。
告诉我们插入是否成功,pair的first成员是一个迭代器,指向具有给定关键字的元素(pair),
second成员是一个bool值,指出元素是插入成功还是失败已存在容器中。如果关键字已经
在容器中,那么insert什么事情也不做,返回值中的bool部分为false。
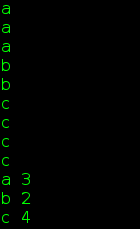
例子:统计单词出现次数
#include <map>
#include <iostream>
#include <string>
using namespace std;
int main()
{
map<string,size_t>mp;
string word;
while(cin >> word)
{
pair<map<string,size_t>::iterator, bool> ret = mp.insert({word,1}); //<span style="color:#FF0000;">ret前面是真正的insert返回类型。且pair第一个元素是map类型的迭代器</span>
//auto ret = mp.insert({word,1}); //使用auto方便了不少。但也要知道真正的返回类型。
if(!ret.second)
++ret.first->second; //对返回的进行修改结果也修改了说明返回的是引用。
++mp.insert({word,0}).first->second; //等价于while()循环里面的所有操作。
}
for(const pair<string,int>&p : mp)
cout << p.first << " " << p.second << endl;
}
!注意对pair元素用“.”,对迭代器用“->”。
对允许重复关键字的容器,接受单个元素的insert总是成功的并返回一个指向新元素的迭代器,这里无须返回一个bool。
<6.删除元素
三种操作
c.erase(k); //删除一个元素,返回删除的数量
c.erase(p); //删除指定迭代器的元素,返回p之后元素的迭代器
c.erase(b,e);//删除(b,e)范围内的所有元素,返回e
#include <map>
#include <iostream>
using namespace std;
int main()
{
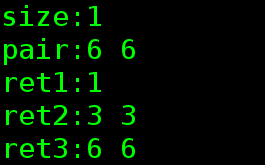
map<int,int>mp = {{1,1},{2,2},{3,3},{4,4},{5,5},{6,6}};
size_t ret1 = mp.erase(2);
auto ret2 = mp.erase(mp.begin());
auto ret3 = mp.erase(mp.begin(), --mp.end());
cout << "size:" << mp.size() << endl;
for(const pair<int,int>&p : mp)
{
cout << "pair:" << p.first << " " << p.second << endl;
}
cout << "ret1:" << ret1 << endl;
cout << "ret2:" << ret2->first << " " << ret2->second << endl;
cout << "ret3:" << ret3->first << " " << ret3->second << endl;
}
<7.map的下标操作
map和unordered_map容器提供了下标运算符和一个对应的at函数。set不支持下标
我们不能对一个multimap或一个unordered_multimap进行下标操作,因为可能有多个值与一个关键字想对应。
map下标操作:接受一个索引(key值)获取与此索引相关联的值。
但是map和其他容器不同的是,如果索引值不在容器中,它会创建一个元素并插入到map中去,关联值将进行初始化。
因为下标运算符可能插入一个新元素,所以我们只能对非const 的map使用下标操作。
c[key]:返回关键字为key值的元素。如果key不在,则添加
c.at[key]:访问关键字为key的元素,如果不在,抛出一个out_of_range异常。
对map进行下标运算时,会获得一个mapped_type对象,但是当解引用一个map迭代器时,得到一个value_type对象。
if(mp[a] == 123) //可能a不再mp容器里
mp[a] = 234;
!注意!可以用什么类型来对一个map进行下标操作。答:只要定义了比较运算符都可以。
<8.访问元素
#include <iostream>
#include <map>
using namespace std;
int main()
{
map<int,int>mp = {{1,1},{2,2},{3,3},{4,4},{5,5}};
auto ret1 = mp.find(1);//返回一个迭代器
auto ret2 = mp.find(11);//未找到返回迭代器=mp.end();
auto ret3 = mp.count(1);//返回数量
auto ret4 = mp.count(11);
cout << "ret1:" << ret1->first << " " << ret1->second << endl;
cout << "ret2:" << ret2->first << " " << ret2->second << endl;
cout << "ret3:" << ret3 << endl;
cout << "ret4:" << ret4 << endl;
auto ret5 = mp.lower_bound(2);//返回一个迭代器,指向第一个关键字不小于2的元素。大于等于2
auto ret6 = mp.upper_bound(3);//返回一个迭代器,指向第一个关键字大于3的元素。
cout << "ret5:" << ret5->first << " " << ret5->second << endl;
cout << "ret6:" << ret6->first << " " << ret6->second << endl;
multimap<int,int>mmp = {{1,1},{1,1},{2,2},{1,1}};
for(const pair<int,int>&p : mmp)
cout << p.first << " " << p.second << endl;
auto it = mmp.equal_range(1);//返回一个pair,里面存储的是范围。
cout << "equal_bound" << endl;
for(auto i = it.first; i != it.second; ++i)
cout << i->first << " " << i->second << endl;
cout << "lower_bound, upper_bound" << endl;
for(auto beg = mmp.lower_bound(1),end = mmp.upper_bound(1); beg != end; ++beg)
{
cout << beg->first << " " << beg->second << endl;
}
}
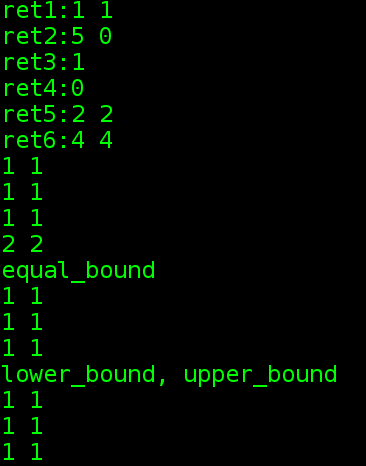
注意!用lower_bound和upper_bound可以代替equal_bound
相同的关键字调用lower_bound和upper_bound会得到一个迭代器范围,表示具有关键字的范围。
如果lower_bound和upper_bound返回相同的迭代器,则给定的关键字不在容器中。
例题:对于一个string到int的vector的map,定义并初始化一个变量来保存。
#include <map>
#include <iostream>
#include <vector>
#include <string>
using namespace std;
int main()
{
map<string, vector<int>>mp = {{"a",{1,2,3}}, {"b", {2,3,4}}, {"b",{3,4,5}}}; //初始值列表记得每个pair带括号
auto it = mp.find("a"); //返回的是指向该pair的迭代器。
for(int i : it->second)
cout << i << " ";
cout << endl;
}3.无序容器
c++11定义了新的4个无序关联容器,这些容器不是使用比较运算符来组织元素的,而是使用一个hash函数和关键字类型==运算符。
在某些不需要容器有序的情况下,无序容器是非常有用的,因为维护有序容器的有序代价非常高
使用无序容器通常更为简单。
unordered_map 用hash函数组织的map 头文件unordered_map
unordered_set 用hash函数组织的set 头文件unordered_set
unordered_multimap hash组织的map:关键字可重复出现 头文件unordered_map
unordered_multiset hash组织的set:关键字可重复出现 头文件unordered_set但是无序容器的输出和有序容器的输出不同,因为是无序的。
看用无序容器计数单词的例子
#include <unordered_map>
#include <string>
#include <iostream>
using namespace std;
int main()
{
unordered_map<string,size_t>ump;
string word;
while(cin >> word)
{
++ump[word];
}
for(const pair<string,size_t>&p : ump)
{
cout << "word:" << p.first << " times:" << p.second << endl;
}
}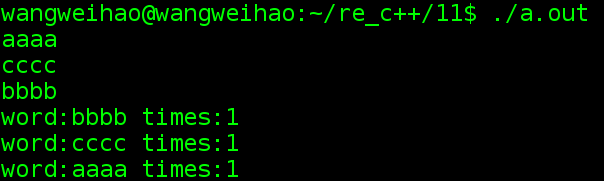
可以看出来输出结果是无序的,因为用的是hash。
<1.管理桶
无序容器在组织形式上为一组桶,每个桶代表哈希key值后的一个值,桶里面放着的是键值相同的元素,
因为hash后他们的值相同。
访问一个元素时,首先hash看是在哪个桶。因此无序容器的质量依赖于hash函数的质量和桶的大小和数量。
#include <unordered_map>
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main()
{
unordered_map<string,size_t>ump;
map<string,size_t>mp = {{"f",6},{"g",7},{"k",8}};
string s;
ump.insert(pair<string,size_t>("a",1)); //插入的几种形式
ump.insert(make_pair("b",2));
ump.insert({"c",3});
ump.insert({{"d",4},{"e",5}});
ump.insert(mp.begin(),mp.end());
for(const auto &p : ump) //遍历容器
{
cout << "(" << p.first << " " << p.second << ")";
cout << " ";
}
cout << endl;
cout << "bucket_interface" << endl; //桶接口
cout << "bucket_count:" << ump.bucket_count() << endl; //桶数量
cout << "max_bucket_count:" << ump.bucket_count() << endl; //容器能容纳的桶的最大数量
cout << "bucket_size(1):" << ump.bucket_size(1) << endl; //桶1的大小,有多少个元素
cout << "belong bucket:" << ump.bucket("a") << endl; //关键字key属于哪个桶
for(unordered_map<string,size_t>::iterator it = ump.begin(); it != ump.end(); ++it) //遍历容器
{
cout << it->first << " " << it->second << " ";
}
cout << endl;
//遍历第一个桶。
for(auto i = ump.begin(1); i != ump.end(1); ++i)
{
cout << i->first << " " << i->second << endl; //容器内部存储也是pair。
}
//哈希策略
cout << "bucket_avg:" << ump.load_factor() << endl; //每个桶的平均元素个数
cout << "maintain_bucket:" << ump.max_load_factor() << endl; //维护平均桶大小,使load_factor <= max_load_factor 需要时添加新的桶。
ump.rehash(20); //c.rehash(n),重组存储,是桶的数量>=n
ump.reserve(10);//c.reserve(),重组存储,使c可以保存n个元素不必rehash
}
分别用g++和clang编译了下,有区别,优化不同。
<2.无序容器对关键字类型的要求
无序容器使用关键字==来比较元素,它们还使用了一个hash<key_type>类型的对象来生成每个元素的hash值。
但是我们不能定义关键字类型为自定义类类型的无序容器。与容器不同,不能直接使用hash模板,而是必须提供我们自己的hash模板
但是有另外一种方法:为了将自己的类当作关键字,我们要自己提供==运算符和hash值计算函数。
然后定义,比如
using SD_multiset = unordered_multiset<Sales_datam decltype(hasher)*, decltype(eqop)*>; //hasher是自己定义的hash函数,eqop是自己定义的==运算符。
SD_multiset bookstroe(43, hasher, eqop);//初始化