基本使用
1 简单的yaml文件
在K8s集群上可使用Kubectl命令以指定文件方式创建一个kind=Deployment的资源对象
$ kubectl create -f nginx.yaml
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.9.1
下图分别为 在终端查看生成的DeployMent, ReplicaSet, pod资源,以及他们之前的拓扑关系图(可以先忽略oldReplicaSet)
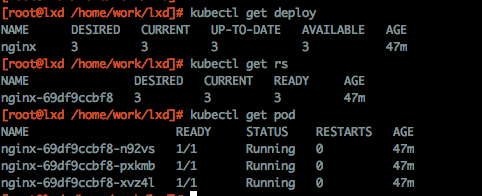
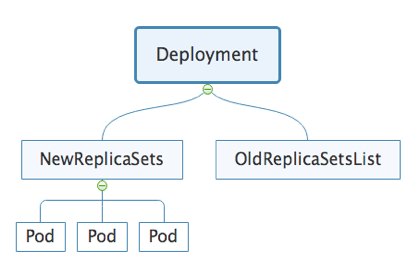
如图,k8s根据yaml中指定的spec.replicas值为我们创建3个pod,并在deployment整个运行周期中维护这个数量,然后根据spec.template.spec中的container数组配置,将容器组启动在每个pod中。
这是一个简单创建deployment任务过程。
2 更新及回滚
Deployment作为一个大数据结构(yaml文件)控制维护我们的业务,我们通过更新这个yaml文件来更新业务部署。
上节提到spec.template下是具体pod要启动的业务及配置,只有对spec.template进行更新才会触发pod重新部署(横向扩缩容不触发重新部署)
命令行支持两种更新方式,更新后自动触发deployment更新
更新结果是根据deployment中配置的replicas数和spec.template中定义的模板,生成pod。然后清理上版本的旧pod。
//直接使用 kubectl set 更新对象
$ kubectl set image deployment/nginx nginx=nginx:1.9.1
//直接更新nginx yaml文件
$ kubectl edit deployment/nginx
此时观察到系统中存在两个replicaSet,如果正常发布,Dp拥有两个Rs,新版Rs下维护3个pod,旧版下0个,k8s默认为我们保留更新过的版本,方便我们回滚版本使用。
以下是一个更新及回滚过程中Rs的状态
(初次发布后Rs状态 -> set修改镜像触发更新 -> 新pod生成旧版本下pod被清理 -> 回滚 -> "旧"版本pod被重建,"新"版本pod被清理)
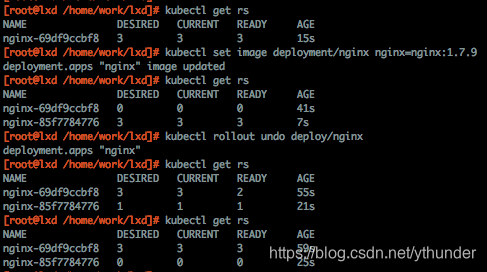
以上为基本的更新/回滚流程。两个问题:
- 过程描述中,回滚后的新旧版本被我加了双引号
- 倒数第2次get Rs信息,发现版本之间数量的变化并非单独的清理旧版,发起新版。
(后面读源码将讲到)
暂停与恢复
暂停态时,对spec.template资源的更新都不会生效。恢复状态后,再执行更新操作。官方现在给的解释为:暂停态为支持多次更新配置而不用触发更新。
命令:
$ kubectl rollout pause deployment/nginx //暂停
$ kubectl rollout resume deployment/nginx //恢复
因为不会触发更新,所以理论上也不支持回滚。在暂停态时,发起回滚属于非法操作。
STATUS
Dp结构体主要包含3个部分:
* ObjectMeta 元数据
* DeploymentSpec Dp任务期望状态
* Status 处理状态
其中Meta由用户指定一部分,另一部分系统维护。DpSpec基本由用户指定,Status完全基本由系统控制,在同步过程中对此状态进行参考修改。
我目前根据Dp配置中的condition判断k8s在处理过程中的状态:
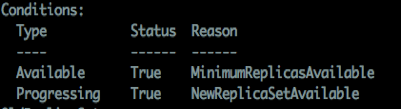
以上表示两项结果:
- Available 服务是否达到可用状态(可自定义livenessProbe、readinessProbe等来指定服务可用标志,默认pod内容器正常启动即为可用),图中此项status为True,原因为满足用户期望的最小可用实例数
- Progressing 指Dp收到的最近一个更新请求是否完成。例如回滚操作,指定时间内达到用户预期结果status将置为true,否则为False并设置错误原因。指定时间由spec.progressDeadlineSecond参数指定,Pause状态时此值不定义超时。 (此处更新指所有对Dp的更新,包括水平扩容操作)
概念
Label、Seletor and OwnerReference
观察本文图1,发现资源名的特点:
创建Dp时,我们定义nginx为name;Dp生成的Rs名均为nginx-hashstr;Rs又创建多个pod,pod名为rs-hashstr
假定Dp->Rs->Pod是一个从上到下的关系,那k8s通过上层selector和下层labels来确认下属于上,同时下层会保存上层的metaUid信息,用于所属确认和垃圾回收。
我通过–show-labels 来查看三项资源的lebels信息:
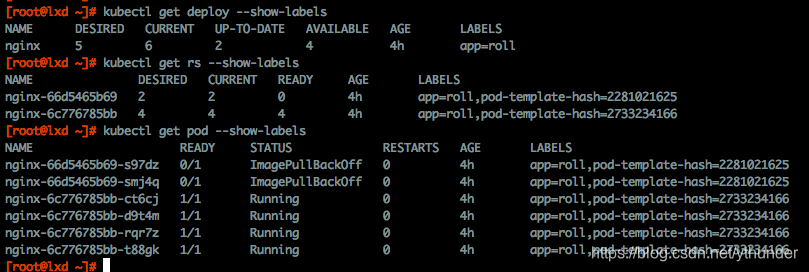
如上,Dp通过 app=roll 来确定Rs,但是不同版本Rs之间必须有差别,所以创建Rs时引入pod-template-hash作为selector 和 labels,并将其复制给pod.labels,这样在dp下同时存在两个版本时,多个Rs可以接管各自的pod
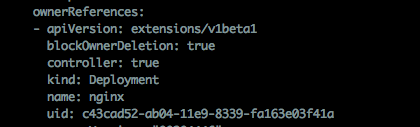
Rs和Pod中,都保存了ownerReferences信息。uid为所属Dp.uid。有两项用处(以获取dp下拥有的rs为例):
- 遍历检查rs.labels,首先检查并确认dp.selector需要是它的子集。然后检查rs.ownerReferences,确认为Dp信息时,表示此Rs属于Dp
- 删除Deployment时,仅操作Dp资源。检查Rs时,通过确认其uid标识的owner已被删除,确认是不是清理当前Rs资源
ControllerManager源码阅读
简单介绍一下事件处理前的如何获取事件集:
为了减轻对apiserver的压力,客户端存在一个Informer,它负责从apiserver端同步发生变更的数据到store,然后从store中读取需要处理的事件调用相应的Handler。
deploymentController会启动多个worker去接收store中的deployment-key,Handler处理函数为syncDeployment
syncDeployment
func (dc *DeploymentController) syncDeployment(key string) error {
//由key值获取Dp的namespaces和name
namespace, name, err := cache.SplitMetaNamespaceKey(key)
//根据ns、name从系统中获取deployment当前信息(此时有可能已被delete,在处理同步中会不断检查删除状态)
deployment, err := dc.dLister.Deployments(namespace).Get(name)
//deepcopy信息,更新状态时更新拷贝信息然后将副本更新到server
d := deployment.DeepCopy()
//行为:获取属于当前Dp的所有Rs,同时进行一些adopt和release操作
rsList, err := dc.getReplicaSetsForDeployment(d)
//获取rs列表下的所有pod,返回Map(key为Rs.UID value为PodList)
podMap, err := dc.getPodMapForDeployment(d, rsList)
//如果Pod已经被delete,调用getAllReplicaSetsAndSyncRevision更新版本信息,并同步状态信息。不明白这里,为什么已删除还要同步状态
if d.DeletionTimestamp != nil {
return dc.syncStatusOnly(d, rsList)
}
//检查是否为暂停或恢复事件。
//暂停时将condition中Progressing中 status=Unknown reason=DpPaused,此时不对其进行处理超时等检查
//检查为恢复请求并且当前为暂停时,更新Progressing为 status=Unknown reason=DpResume
if err = dc.checkPausedConditions(d)
//暂停态时,执行sync同步状态(本节会单独分析函数)
if d.Spec.Paused {
return dc.sync(d, rsList)
}
//检查有回滚事件时,回滚版本(下节会分析此函数)
if getRollbackTo(d) != nil {
return dc.rollback(d, rsList)
}
//发现desire与dp.replicas不符时,确定为正在进行扩缩容事件,调用sync同步
scalingEvent, err := dc.isScalingEvent(d, rsList)
if scalingEvent {
return dc.sync(d, rsList)
}
//根据两种发布策略检查并更新deployment到最新状态(下节会分析处理函数)
switch d.Spec.Strategy.Type {
case apps.RecreateDeploymentStrategyType:
return dc.rolloutRecreate(d, rsList, podMap)
case apps.RollingUpdateDeploymentStrategyType:
return dc.rolloutRolling(d, rsList)
}
}
getReplicaSetForDeployment行为: 轮询检查Dp所在ns下所有Rs并返回Dp控制的RsList。
- Dp.Selector与Rs.labels匹配(前者必须为后者的子集),并且rs.ownerRefrence必须为Dp的信息,则认为此Rs属于Dp,加入RsList
- 如果Rs.owner为空,并且Dp.Selector匹配Rs.labels, controller将为Rs.owner添加此Dp的信息,称为adopt,并加入RsList
- 如果Rs.Owner为此Dp信息, 但是selector不匹配,controller将删除此Rs的Owner信息,称为release,此时Rs将称为孤儿直到有匹配labels的Dp出现收养它
- 返回RsList
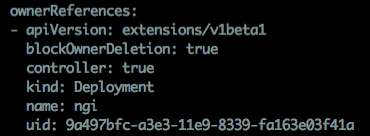
上图为Rs.Owner信息。uid为所属Dp的元数据,此值全局唯一。
sync函数 在Dp暂停时协调Dp状态以及扩缩容状态
- 更新Dp下Rs revision信息 遍历所有Rs获取当前最大revision号maxId,检查maxId的Rs.spec是否等于Dp.spec.template.spec(检查是否为newRs的唯一方法),如果存在newRs将其revision更新为maxId+1,如果不存在,将根据Dp.spec.template.spec创建newRs并设置revision号为maxid+1(注意:暂停态时不会创建newRs)。更新后将revision和history-revision信息都加入Annotations
- 如果正在进行scale,对activeRs进行scale up/down;如果activeRs不止一个,比如当前正在进行滚动升级,按比例进行扩缩容,计算公式如下:
newRs.replicas / (newRs.replicas+oldRs.replicas) * needScaleNumber
检查isScale标志:滚动升级时,rs.replicas可能随着滚动过程逐次上升,但annotion中有一项" deployment.kubernetes.io/desired-replicas=10"会指定最终的期望状态,如果此值!=Dp.replicas,则判断为isScale状态 - 如果newRs已经完成更新,将Dp下所有oldRs.replicas调整为0
- 根据d.spec.RevisionHistoryLimit参数保留最新n个Rs版本,清理其他
- 根据allRs信息计算Dp当前状态,并更新到server,信息包括:
status := apps.DeploymentStatus{
Replicas: //Dp下所有Rs的期望实例数
UpdatedReplicas: //新版本Rs期望实例数(不论running与否)
ReadyReplicas: //Dp下所有Rs拥有的ReadyPod数
AvailableReplicas: ///Dp下所有Rs拥有的AvaliblePod数
UnavailableReplicas: //Dp下所有Rs拥有的unavailablePod数
}
//更新condition中type=AvaliblePod状态,下面是avaliblePod个数是否达标时设置的conditon
deploymentutil.NewDeploymentCondition("Available", "True", "MinimumReplicasAvailable", "Deployment has minimum availability.")
deploymentutil.NewDeploymentCondition("Available", "False", "MinimumReplicasAvailable", "Deployment does not have minimum availability")
如上,是被加入queue中的每个deployment被处理的过程,deployment通过更新Rs-yaml信息来同步状态。
stracy 更新策略
deployment目前支持两种更新策略:
- Recreate 删除所有旧pod,然后创建新Pod。一般用于开发环境
- RollingUpdate 滚动更新,删除一部分oldPod,创建一部分newPod,重复此步骤直到达到Dp预期
RollingUpdate
滚动更新涉及两个重要参数,配置在deployment.yaml文件中如下:
replicas: 5 #deployment期望实例数
strategy: #升级策略提示符 位于yaml中 .spec下
rollingUpdate:
maxSurge: 1 #更新中允许存在的最大pod数
maxUnavailable: 1 #更新中允许存在的最大不可用pod数, dp.replicas-maxUnava为最小可用数
type: RollingUpdate #升级策略
更新版本时触发rollingUpdate,5b69为新版,85bb为旧版本。这次更新设置了错误的镜像,所以更新停止在以下状态:
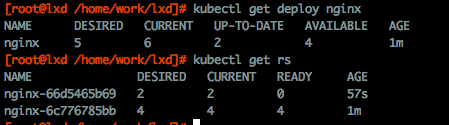
更新过程:
对5b69版本scaleUp 1个pod
对85bb版本scaleDown 1个pod
对5b69版本scaleUp 1个pod
!对85bb版本scaleDown 1个pod 此时因为maxUnavaluble限制,此版本不能再缩容,又因为maxSurge限制,新版本pod不能再发起,由此stuck在上图状态
//升级过程中发生的scale up/down,实际上是操作Rs.replicas
func (dc *DeploymentController) rolloutRolling(d *apps.Deployment, rsList []*apps.ReplicaSet) error {
//从rslist中获取newRs、oldRs,并更新revision信息。参数为true时,如果不存在newRs就创建它,检查存在newRs与否的标准是:rs.template = dp.spec.template
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, true)
allRSs := append(oldRSs, newRS)
//调整newRs-yaml信息,通常为扩容事件。如果操作了rs.replicas, scaledUp=true.
scaledUp, err := dc.reconcileNewReplicaSet(allRSs, newRS, d)
if scaledUp {
return dc.syncRolloutStatus(allRSs, newRS, d)
}
//调整oldRs-yaml信息,通常为缩容事件。如果操作了rs.replicas,scaledDown=false
scaledDown, err := dc.reconcileOldReplicaSets(allRSs, controller.FilterActiveReplicaSets(oldRSs), newRS, d)
if scaledDown {
return dc.syncRolloutStatus(allRSs, newRS, d)
}
//清理deployment下Rs版本信息
if deploymentutil.DeploymentComplete(d, &d.Status) {
if err := dc.cleanupDeployment(oldRSs, d); err != nil {
return err
}
}
//同步rs状态
return dc.syncRolloutStatus(allRSs, newRS, d)
}
reconcileNewReplicaSet 检查newRs.replicas,确定本次滚动新版本需要新建的数目并更新rs-yaml
- 检查 new.replicas = dp.replicas,等于时返回false,无需更新
- newRs.replicas > dp.replicas时,new版本实例过多,直接scale down至dp.replicas。如果没达到dp.replicas, 则根据公式计算本次需要scale up的数量,公式如下:
Min ( (maxSurge + dp.replicas - dp.currentPod), dp.replicas - newRs.replicas ) - 检查同步dpStatus,为Rs设置Annotations, 添加Event
reconcileOldReplicaSets 检查oldRs.replicas,确定本次滚动旧版本需要清理的数目并更新rs-yaml
- 获取所有activeRs下pod总数量,为0时,返回false,无需更新
- 清理oldRs列表中 UnAvalible状态的pod,代码如下:
//最大可清理旧版本pod数量,缩容时,RS下列表pod是经过排序的,保证优先清理Unhealthy Pod
maxCleanCount = allPodsCount - minAvailable - newRSUnavailablePodCount
//遍历每个ActiveoldRs
totalScaledDown=0 //记录已清理副本数,不能超过maxCleanCount值
for _, targetRs := range oldRsList {
scaledDownCount := Min(maxCleanCount - totalScaledDown, targetRS.Spec.Replicas-targetRS.Status.AvailableReplicas) //当前Rs缩容数
//向server发送缩容请求
totalScaledDown+=scaledDownCount
}
- 根据配置最小可用数计算本次需要scaleDown的pod,代码如下:
totalScaleDownCount := availablePodCount - minAvailable
totalScaledDown := int32(0) //记录本次总scaleDown数目,不能超过totalScaleDownCount值
for _, targetRs := range oldRsList {
scaleDownCount := Min(targetRS.Spec.Replicas, totalScaleDownCount-totalScaledDown)
totalScaledDown += scaleDownCount
}
- 检查同步dpStatus,为Rs设置Annotations, 添加Event
以上为rollingUpdate过程中,deployment-controller通过控制其下rs.replicas值来控制pod更新的过程,简单流程为:根据deployment.spec确定newRs和oldRs,通过maxSurge和maxUnavalible限制来不断添加新版本Pod并删除旧版本pod,最终达到newRs.replicas=dp.replicas 并且oldRs.replicas=0,标志progressing正常结束。
Recreate
func (dc *DeploymentController) rolloutRecreate(d *apps.Deployment, rsList []*apps.ReplicaSet, podMap map[types.UID]*v1.PodList) error {
//getRs并更新版本信息,false参数表示如果没有新版本则不创建
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, false)
if err != nil {
return err
}
allRSs := append(oldRSs, newRS)
activeOldRSs := controller.FilterActiveReplicaSets(oldRSs)
//缩容所有active的旧实例(其下有pod即为active),如果有缩容操作,则更新状态
scaledDown, err := dc.scaleDownOldReplicaSetsForRecreate(activeOldRSs, d)
if scaledDown {
return dc.syncRolloutStatus(allRSs, newRS, d)
}
//确认Rs下已经没有 running/pending/unknown 状态的pod
if oldPodsRunning(newRS, oldRSs, podMap) {
return dc.syncRolloutStatus(allRSs, newRS, d)
}
//创建newRs并扩容
if newRS == nil {
newRS, oldRSs, err = dc.getAllReplicaSetsAndSyncRevision(d, rsList, true)
allRSs = append(oldRSs, newRS)
}
dc.scaleUpNewReplicaSetForRecreate(newRS, d)
if util.DeploymentComplete(d, &d.Status) {
if err := dc.cleanupDeployment(oldRSs, d); err != nil {
return err
}
}
return dc.syncRolloutStatus(allRSs, newRS, d)
Rollback
func (dc *DeploymentController) rollback(d *apps.Deployment, rsList []*apps.ReplicaSet) error {
//getRs并更新版本号
newRS, allOldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, true)
allRSs := append(allOldRSs, newRS)
rollbackTo := getRollbackTo(d)
if rollbackTo.Revision == 0 {
//如果未指定Revision,遍历rs找到第二max的revision
rollbackTo.Revision = deploymentutil.LastRevision(allRSs)}
//根据revision遍历RsList找到对应rs,将rs.spec.template复制给dp.spec.template,并更新此版本为最新版,deployment-controller将在下次调用getAllReplicaSetsAndSyncRevision时创建newRs
for _, rs := range allRSs {
v, err := deploymentutil.Revision(rs)
if v == rollbackTo.Revision {
performedRollback, err := dc.rollbackToTemplate(d, rs)
return err
}
}
//清理一些anntition相关的信息
return dc.updateDeploymentAndClearRollbackTo(d)
}
如上,回滚相当于一次更新操作,更新dp.spec.template,在同步时,根据此内容生成新的Rs版本,继而控制产生期望Pod。
syncReplicaSet
func (rsc *ReplicaSetController) syncReplicaSet(key string) error {
startTime := time.Now()
namespace, name, err := cache.SplitMetaNamespaceKey(key)
rs, err := rsc.rsLister.ReplicaSets(namespace).Get(name)
//rs是否需要同步
rsNeedsSync := rsc.expectations.SatisfiedExpectations(key)
//获取Rs所在ns下所有Pod
//过滤非success和已删除pod
//获取ns下所有pod,获取过程参考Dp获取Rs
selector, err := metav1.LabelSelectorAsSelector(rs.Spec.Selector)
allPods, err := rsc.podLister.Pods(rs.Namespace).List(labels.Everything())
filteredPods := controller.FilterActivePods(allPods)
filteredPods, err = rsc.claimPods(rs, selector, filteredPods)
var manageReplicasErr error
//管理此rs下pod, 增删pod(具体实现下面讲?)
if rsNeedsSync && rs.DeletionTimestamp == nil {
manageReplicasErr = rsc.manageReplicas(filteredPods, rs)
}
//返回rs下关于pod的running/avalidble等状态数量汇总和status相关的东西
rs = rs.DeepCopy()
newStatus := calculateStatus(rs, filteredPods, manageReplicasErr)
updatedRS, err := updateReplicaSetStatus(rsc.kubeClient.AppsV1().ReplicaSets(rs.Namespace), rs, newStatus)
//状态还需要同步时,加入队列
if manageReplicasErr == nil && updatedRS.Spec.MinReadySeconds > 0 &&
updatedRS.Status.ReadyReplicas == *(updatedRS.Spec.Replicas) &&
updatedRS.Status.AvailableReplicas != *(updatedRS.Spec.Replicas) {
rsc.enqueueReplicaSetAfter(updatedRS, time.Duration(updatedRS.Spec.MinReadySeconds)*time.Second)
}
return manageReplicasErr
}
ManageReplicas函数 管理rs下pod,使符合预期
func (rsc *ReplicaSetController) manageReplicas(filteredPods []*v1.Pod, rs *apps.ReplicaSet) error {
diff := len(filteredPods) - int(*(rs.Spec.Replicas))
rsKey, err := controller.KeyFunc(rs)
//avaliblePod数未达到期望值,需要扩容。 burstReplicas为单次创建Pod限制
if diff < 0 {
diff *= -1
if diff > rsc.burstReplicas {
diff = rsc.burstReplicas
}
//批量创建Pod,批量数字从1开始double增加,这样可以防止出现相同错误的pod大量失败的情况
//例如,一个尝试创建大量Pod的低quota的任务将在第一个Pod创建失败时被停止,返回成功创建数量
//successfulCreations表示成功调用创建pod函数的次数
successfulCreations, err := slowStartBatch(diff, controller.SlowStartInitialBatchSize, func() error {
err := rsc.podControl.CreatePodsWithControllerRef(rs.Namespace, &rs.Spec.Template, rs, metav1.NewControllerRef(rs, rsc.GroupVersionKind))
//重新调起pod数量未达到diff值,这里应该是一个记录此次调用失败,提醒informer下次继续调用的过程
if skippedPods := diff - successfulCreations; skippedPods > 0 {
for i := 0; i < skippedPods; i++ {
rsc.expectations.CreationObserved(rsKey)
}
}
} else if diff > 0 {
//存在pod超过期望值,getPodsToDelete中对pod按照状态进行排序,根据数量返回需要删除pod数组,优先删除unhealthy等unAvailible态
if diff > rsc.burstReplicas {
diff = rsc.burstReplicas
}
podsToDelete := getPodsToDelete(filteredPods, diff)
for _, pod := range podsToDelete {
go func(targetPod *v1.Pod) {
defer wg.Done()
rsc.podControl.DeletePod(rs.Namespace, targetPod.Name, rs)
}(pod)
}
wg.Wait()
}
}