既然都叫最简单的数据库“范式”教程,我觉得它一定要满足这个要求:看完这篇博客,你一定会明白数据库的“范式”和那些诸如“完全函数依赖”,“部分函数依赖”,“传递函数依赖”等烦人的概念,前提是你得跟着我的思路认真的读完它,好,准备好你的半个小时了吗?我们开始。
目录
- 什么是范式?
- 贯穿全文的一个例子。
- 第一范式(1NF)
- 几个重要的概念。
- 第二范式(2NF)
- 第三范式(3NF)
- BC范式(BCNF)
- 第四范式(4NF)
1. 什么是范式?
范式其实就是关系数据库规范程度的级别,举个我们生活中的例子,老师让打扫卫生,最低标准是扫地,二级标准是扫地+擦桌子,三级标准是扫地+擦桌子+擦玻璃,实际上在标准不断上升的过程中,首先高一级的标准是满足低一级标准的,范式也是如此,只不过它的标准描述的是数据库规范化的程度罢了。数据库中的范式有1NF , 2NF , 3NF , BCNF , 4NF,5NF(本文不讨论)。它们之间的关系1NF < 2NF < 3NF < BCNF < 4NF(默认越大 级别越高)。
2.贯穿全文的一个例子。
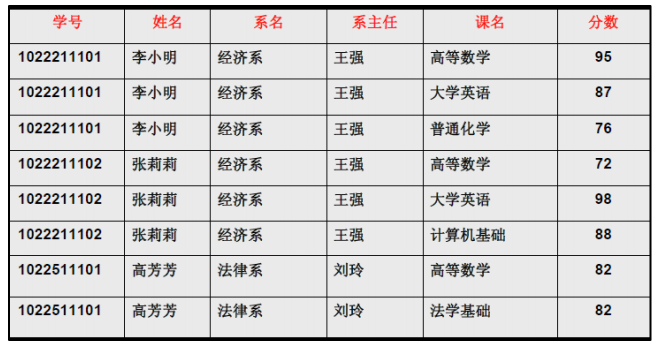
这个例子有下面的关系
(学号,课名)->分数
学号->姓名
学号->系名
系名->系主任
注:A->B:理解为A属性可以唯一确定B属性。
这个例子会在说第二范式和第三范式的时候被逐步优化。
3.第一范式(1NF)
数据库表的每一列都是不可再分的原子数据项,它是一个关系型数据库的最低标准,如果不满足第一范式,那么这个数据库就不是关系型数据库。如下所示:
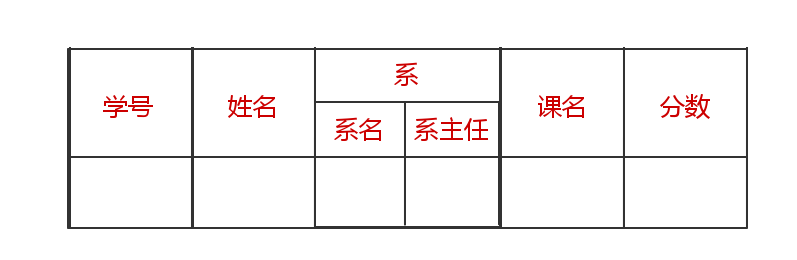
这个表我们无法在数据库中直接创建,因为它的系这一列,既有系名又有系主任,产生了冲突,如果作出调整,使它符合第一范式,那么应该是这样的:

但是即使这样,数据库中还是会存在诸如插入、删除、数据冗余等异常。比如针对下面的表:
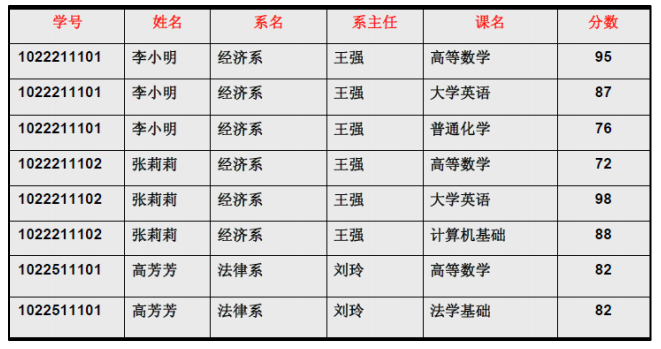
- 数据冗余:可以看到姓名、系名和系主任这三列冗余非常大。
- 插入异常:如果目前开设了计算机系,但是尚未招生,那么计算机系是无法插入到表的系名中的,(学号,课名)是主属性,不能为空。
- 删除异常:如果经济系的学生全部毕业了,在删除所有学生的时候,会将经济系一并删除
因此这个数据库的设计是有缺陷的,为了优化它,我们继续到第二范式。在说第二范式之前,我们先来说几个重要的概念。
4.几个重要的概念。
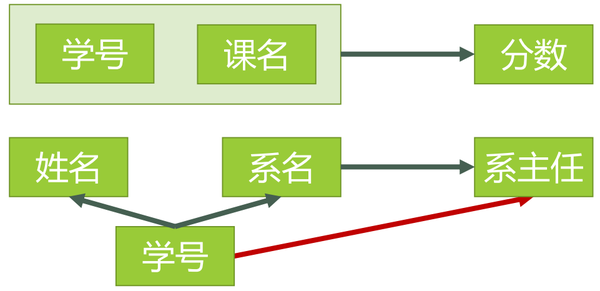
函数依赖:在一张表中,如果给定A属性(或属性组)的值,一定能唯一确定B属性的值,那么就说B依赖于A属性(或属性组),记作A->B,比如给定学号,就能确定姓名,一个学号一定能确定一个姓名,就这么简单,是不是似曾相识?对,我们在第二部分中说那个贯穿全文的例子的时候其实已经用到这个概念了。
完全函数依赖:在函数依赖的基础上,我们的A属性是一个属性组,只有这个属性组中的全部属性才能确定唯一的B属性,A的任何一个子集都不可以。比如(学号,课名)->成绩,而单独的学号或者课名都不能确定成绩,这就叫完全函数依赖。
部分函数依赖:和完全函数依赖相比,A属性组中的部分属性就能确定B属性,其它属性可有可无,比如(学号,课名)->姓名,其实只要学号就可以了,这样的依赖就叫部分函数依赖。
传递函数依赖:如果A->B,B->C,并且B不能->A(防止直接A->C),那么我们可以得出结论A->C,叫做C传递函数依赖A。比如学号->系名,系名->系主任,并且(系名不能决定学号),所以系主任传递函数依赖学号。
码:一个属性或者属性组,使得整个关系中除过此属性或者属性组之外的其余属性都
完全函数依赖于它,那它就是码。例如(学号,成绩),它们两个的组合可以将其他所有的属性都决定了,(学号,课名)->分数,学号->姓名,学号->系名,学号->系名->系主任,所以(学号,课名)就是这个关系中的一个码,那这个关系中还有别的码吗? 谁知道呢,但我们的分析过程应该是这样的:从一个属性一直到n个属性全部来一遍。
- 一个属性:学号,姓名,系名,系主任,课名,分数。找反例即可:学号不能决定分数,(必须要课名),姓名什么也决定不了,系名只能决定系主任,课名也决定不了什么,分数一样。所以一个属性中肯定是没有码的。
- 两个属性:(学号,姓名),(学号,系名),(学号,系主任),(学号,课名),(学号,分数),(姓名,系名),(姓名,系主任),(姓名,课名),(姓名,分数),(系名,系主任),(系名,课名),(系名,分数),(系主任,课名),(系主任,分数),(课名,分数)。呼~终于完了,我们再进行分析,发现只有(学号,课名),这个组合与其他的关系来说是完全函数依赖。也就是它们是一个码。
- 三个属性:……
- 四个属性:……
- 五个属性:……
- 六个属性:……
好吧,只能这样吗?对,只能这样
,其实有一些能减少工作量的方法,比如如果我们在分析两个属性时已经确定(学号,课名)是
码,那么在以后的分析中,如果包含(学号,课名)的那就一定不是码,因为要完全函数依赖。比如(学号,课名,系名)就不用分析了。其他的方法大家自己总结吧。
- 主属性:所有的码中包含的属性都是主属性。
- 非主属性:除过码中包含属性之外的属性。
呼呼~,返过头再看一遍,我们要向第二范式出发了。
5. 第二范式(2NF)
在第一范式基础上,消除非主属性对主属性的部分函数依赖,针对我们的例子,分析如下:
主属性:学号,课名
非主属性:姓名,系名,系主任,分数
目前只有一张表:
(学号,姓名,系名,系主任,课名,分数)
明显,姓名和系名都是对(学号,课名)存在部分函数依赖的。因为其实只需要学号就可以决定姓名和系名。所以这个表目前是不符合第二范式的,我们只好对表作出分解,当然分解的模式不是唯一的,下面只是一种情况,如下所示:
选课(学号,课名,分数)
学生(学号,姓名,系名,系主任)
我们此时再来看两张表是否满足第二范式:
选课表:主属性:(学号,课名)。非主属性:分数。 不存在非主属性对主属性的部分函数依赖,满足第二范式。
学生表:主属性:学号。非主属性:系名,系主任,姓名。因为主属性只有一个,所以一定不存在非主属性对主属性的部分函数依赖。满足第二范式。
至于怎么找主属性,不用我强调了吧,要是忘了的话回头看看上面。此时数据变成了这样:
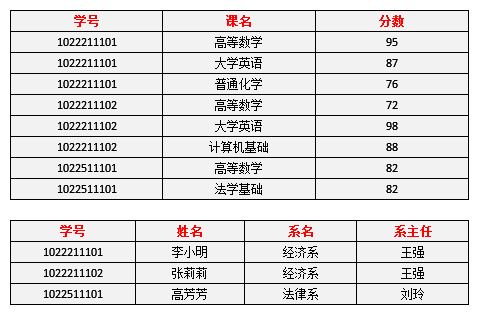
我们回头看看前面的问题有没有得到改善:
- 数据冗余问题:姓名、系名、系主任的数据冗余得到了明显改善。
- 插入异常问题:现在新开设一个系,尚未招生还是无法将系名插入到学生表中,因为学号是主属性,不能为空。没有改善。
- 删除异常问题:一个系毕业,删除这个系的所有学生信息,那还是会连带删除掉系的信息。没有改善。
因此,只满足第二范式也还是不够。还是存在好多问题。
6. 第三范式(3NF)
在第二范式基础上,消除非主属性对主属性的传递函数依赖,同样,我们继续分析我们的例子:
主属性:学号,课名
非主属性:姓名,系名,系主任,分数
目前我们的表如下:
选课(学号,课名,分数)
学生(学号,姓名,系名,系主任)
我们发现在学生表中:存在非主属性系主任对主属性学号的传递函数依赖。因为学号->系名,系名->系主任,所以才会出现前面那么多的问题。那我们试着再次分解学生表,消除这种传递函数依赖。分解后如下:
选课(学号,课名,分数)
学生(学号,姓名,系名)
系(系名,系主任)
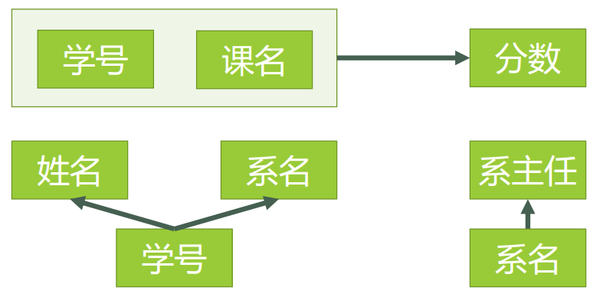
我们继续分析:
选课表中码为(学号,课名),非主属性为分数,它们是完全函数依赖的关系,不存在非主属性对主属性的传递函数依赖。符合第三范式。
对于学生表,码为学号,主属性为学号,非主属性为系名,不可能存在非主属性对于码的传递函数依赖,符合第三范式,
对于系表,码为系名,主属性为系名,非主属性为系主任,不可能存在非主属性对于码的传递函数依赖(至少要有三个属性才可能存在传递函数依赖关系),也符合第三范式。
此时数据成了现在这样:
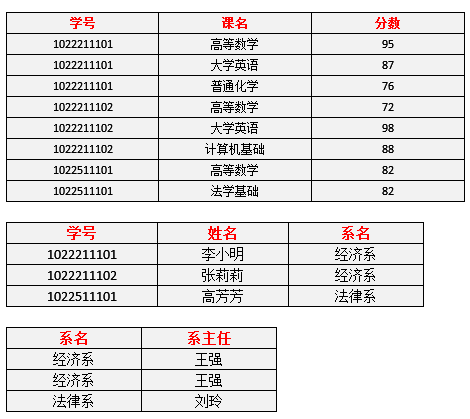
我们再回头看看前面的问题有没有得到改善:
- 插入异常问题:现在新开设一个系,尚未招生我们却可以保存系的信息,因为我们有系这个表。问题得到改善。
- 删除异常问题:一个系毕业,删除这个系的所有学生信息,现在不会连带删除掉系的信息,因为我们有系这个表。问题得到改善。
当数据库到达第三范式的时候,基本上有关数据冗余,数据插入、删除、更新的异常问题得到了解决,这也是一个”合法的”数据库最基本的要求,但是效率问题就另当别论了,因为表越多,连接操作就越多,但是连接是一个比较耗资源的操作。对于我们前面的例子,已经优化到最好了,也没有再次优化的地方。下面我们说到BC范式的时候会说另一个例子。
7. BC范式(BCNF)
在第三范式基础上,消除主属性对主属性的部分函数依赖与传递函数依赖,什么?没搞错吧?对,没搞错。我们看下面的例子。
若:
1:某公司有若干个仓库;
2:每个仓库只能有一名管理员,一名管理员只能在一个仓库中工作;
3:一个仓库中可以存放多种物品,一种物品也可以存放在不同的仓库中。每种物品在每个仓库中都有对应的数量。
如下所示:
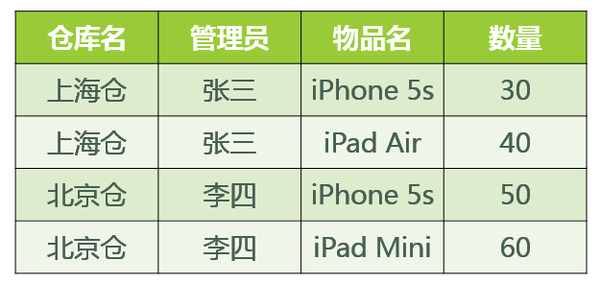
属性有:仓库,管理员,物品,数量。
我们先来找码:
- 一个属性:没有
- 二个属性:(管理员,物品),(仓库,物品)
- 三个属性:包含两个属性中的了,pass
- 四个属性:包含两个属性中的了,pass
我们得到主属性:管理员,物品,仓库
非主属性:数量
不存在数量对主属性的部分函数依赖和传递函数依赖,有的人可能有疑问?明明(仓库,物品)->数量,为什么不是部分函数依赖,是因为我们这里说的主属性是码,此时的三个主属性是由两个码(管理员,物品),(仓库,物品)合起来组成的,它们之间任何一个和数量都不能部分函数依赖。因此这个表是满子第三范式的,但是它还是存在下面的问题:
- 删除问题:对于最后一条记录,(北京仓,李四,iPad Mini,60),我们以后再也不会往这个仓库中存iPad Mini 了,那删除的时候只能连同仓库一起删除。
- 插入问题:如果新建仓库,尚未存入物品,那么也不能为仓库分配管理员。
- 修改异常:如果某个仓库更换了管理员,修改的时候需要逐条记录一起修改。
既然都满足第三范式了,那为什么还是会出现这么多的问题呢?因为存在主属性对主属性的部分函数依赖,此例子中存在(管理员,物品名)->仓库,但是实际上管理员->仓库。因此就存在了主属性对主属性(码)的部分函数依赖。
我们将其模式分解:
仓库(仓库名,管理员)
库存(仓库名,物品名,数量)
再次回头看与原来的问题有没有得到解决
- 删除问题:因为仓库现在有专门的表,所以删除物品的时候不会影响仓库。问题得到改善。
- 插入问题:现在直接再仓库表中新建仓库,与管理员没有关系。得到改善。
- 修改异常:修改了某个仓库的管理员,直接修改仓库表就可以了。得到改善。
符合BCNF的数据库已经非常严格了。但是这种严格只是在函数依赖层面的。啥?上升层面?不是吧,对!接下来要说的第四范式研究的领域是多值依赖层面的。
8. 第四范式(4NF)
那我们还是开门见山的来看一个例子:
Teaching(C,T,B),C表示课程,T表示老师,B表示参考书。
有下面未规范化的关系:
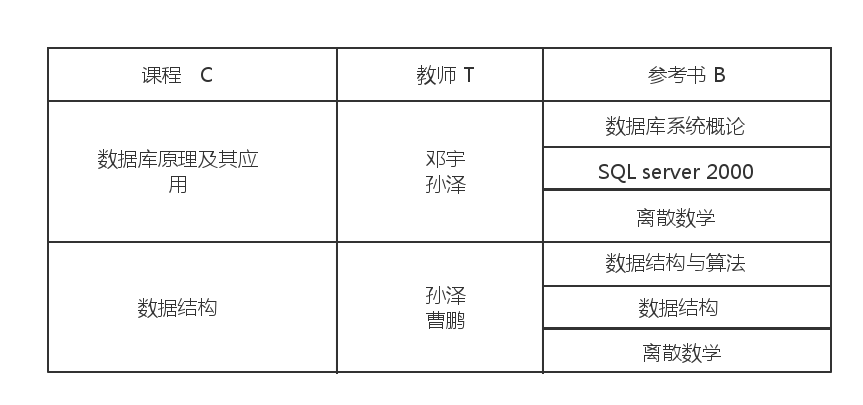
我们先让它满足1NF如下所示:
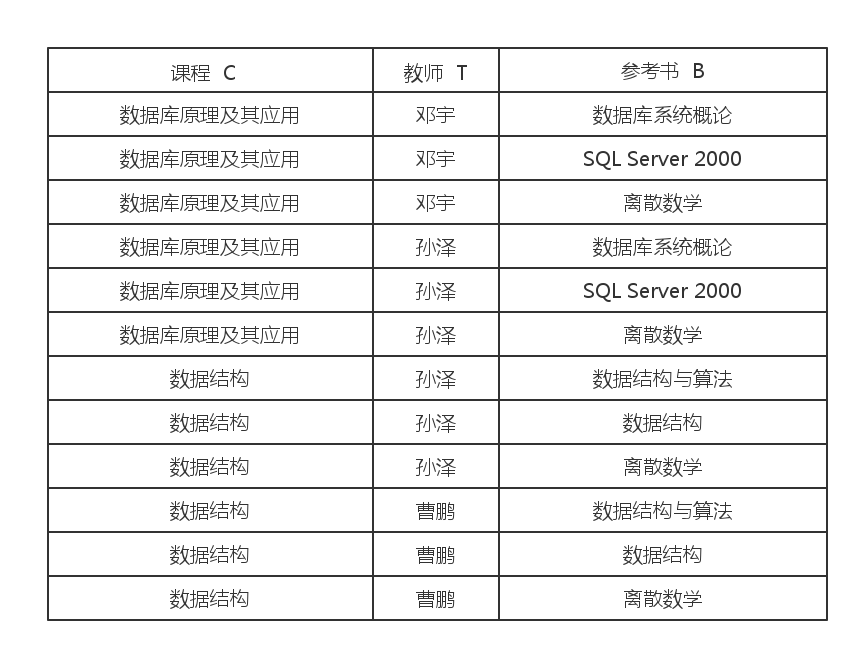
发现存在许多问题:
- 信息冗余:课程和教师存在大量的数据冗余。
- 插入问题:当某个课程增加了一个任课老师,那么需要插入多个元组。
- 删除问题:如果删除一本书,需要删除很多条记录,非常麻烦。
我们再来看它到底属于第几范式。发现这个关系中C、T、B都是唯一的,也就是全键。不存在非主属性,也不存在主属性对主属性的的部分函数依赖和传递函数依赖(因为那样码中至少要两个主属性),它只有一个码(C、T、B)。也就是这个关系是属于BCNF的。那它又为什么会出现这么多问题呢?就是因为它存在多值依赖。
多值依赖:在关系模式R(U)中,X、Y、Z是U的子集,Z=U-X-Y。如果多值依赖X->->Z成立,那么给定(x,y),能确定z的一组值,而且这个值仅由x决定,与y没有关系。
比如:在Teaching中,C、B、T是Teaching的子集,T=Teaching-C-B。给定(C,B),比如(数据库原理与应用,SQL Server 2000),能确定一组T值(邓宇,孙泽)。但是这组T值只与C(数据库原理与应用)有关,与B(SQL Server 2000)没有关系,我们就说C->->T。叫做T多值依赖于C。
平凡多值依赖:如果y为空集。X->->Z就是平凡多值依赖
非平凡多值依赖:y不为空。
其实已经分析完了,就是因为Teaching关系中存在多值依赖,所以才会由我们说的问题,我们进行模式分解,分解得到的表如下所示:
TC表(课程,教师)
BC表(课程,参考书)
看看我们的问题有没有得到解决:
- 信息冗余:得到改善。
- 插入问题:某个课程增加老师,只要在TC表中添加一条记录就好了。改善
- 删除问题:删除一本书,也只要在BC表中删除一条记录即可。改善
现在的表是满足第四范式的,说了这么多,我们最后给出第四范式的定义:关系模式R满足1NF的前提下,如果R中每一个非平凡多值依赖X->->Y,X中都含有键,则R属于4NF,前面讨论的关系中。键是(T、C、B),是全键。C->->B,C->->T,这种多值依赖是非平凡的,但是单独的C不是键,所以就无法满足第四范式。
总结 :函数依赖和多值依赖是两种重要的数据依赖。如果只考虑函数依赖,BCNF已经是非常高的级别了,而且再往上考虑除了多值依赖还有连接依赖,连接依赖属于5NF的范畴了。通过本文中的三个不同例子也能看出来,数据库优化针对不同的数据库到达相应的级别就好,简单的数据库到达第三范式就已经非常完美了。而且增加范式就意味着分解,分解意味着以后可能会连接查询,那样又会影响效率。最后给出著名的数据库优化十六字经:由低到高,逐步规范,权衡利弊,适可而止
如果认真的看到这里,我想你一定有所收获,那么赞一个吧。
参考资料:刘慰老师