这篇博客我想解决两个问题:
1:linux下皆文件,为什么?怎么解释这个问题?
2:touch file 命令执行过程究竟发生了什么。到具体的磁盘上它是怎样运作的?带着这两个问题,我们继续往下走。相信我解释清楚文件系统之后,大家对这两个问题都会有自己的理解。
什么是文件系统
文件系统是对物理存储介质上数据和元数据的组织方式。
物理存储介质:磁盘,U盘等。
数据:文件本身的数据。
元数据:文件的权限,创建者,创建组等文件的信息数据。
组织方式:文件,目录,有了这两个抽象,我们就能组织出层次的结构。为什么需要文件系统
就和我们设计操作系统的目的是为了帮助我们更加方便的使用计算机,避免自己实现操纵硬件的麻烦一样。有了文件系统,我们读写文件的时候只关心文件的内容和权限这些对我们有用的信息,我们并不用管文件在磁盘上是怎么存储的,甚至我们都不需要了解磁盘的结构。它完美的屏蔽了我们对底层磁盘的操作。
都有什么样的文件系统?
Windows:
FAT FAT32 NTFS
Linux:
Ext族 btrfsFAT和Ext的区别
不同的文件系统对于数据的组织方式和索引方式都是不同的。接下来用FAT文件系统和Ext做比较。
一:FAT文件系统索引数据的方式
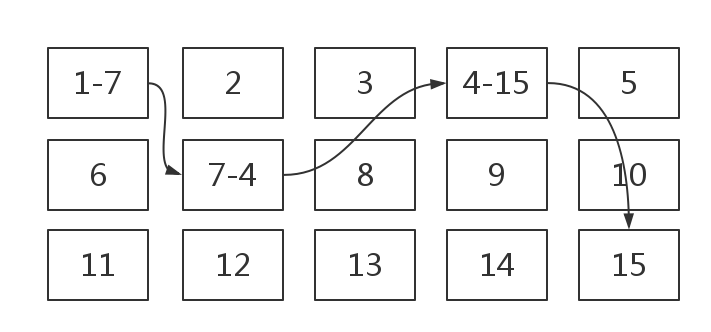
它的索引方式就像链表一样,在前一个结点总会记录下一个结点的位置,因此如果一个文件数据量较大,那么它依次索引的速度是非常慢的。下面的ext文件系统组织数据的方式和FAT就是不一样的。
二:Ext文件系统索引数据的方式
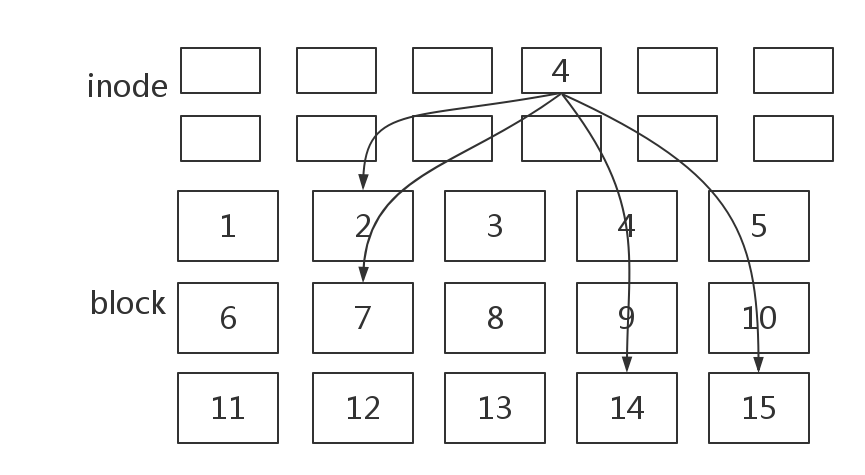
Ext是将文件的block号码记录在inode中,每一个文件都对应一个inode。查找文件数据的时候只需要在inode中读出相应的block号码就可以索引到数据,但是inode本身需要多余的空间来保存,当一个文件的block较多时,inode本身所展的空间就会很多,浪费空间。
磁盘整体结构
刚才在对比FAT和Ext文件系统组织数据方式异同的时候,我提到了这样两个概念inode,block,它们其实是ext4文件系统组织磁盘的重要概念,而且由于我后面会分析内核实现它们的数据结构,所以在此之前我觉得有必要从宏观上也就是在磁盘的层面上让大家对磁盘整体有一个认识。下面是我画的一个简易磁盘:
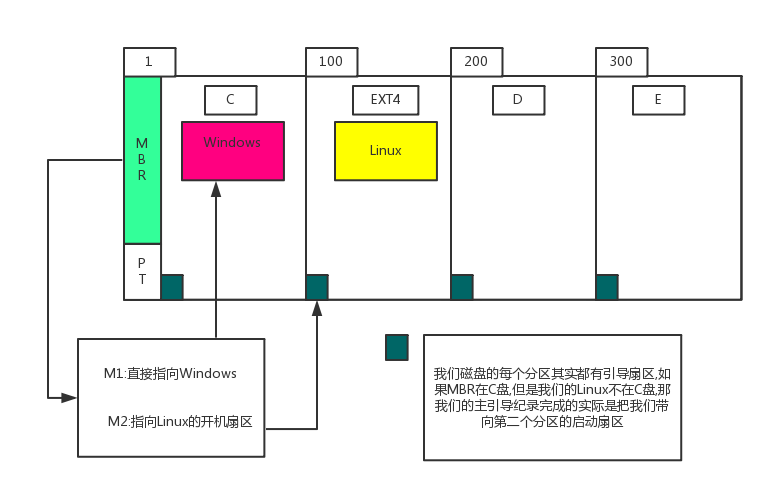
实际上也能解释开机启动过程,厚颜无耻的推荐:按下电源键的一刻,计算机内部发生了什么?
上面的图片需要注意:
- MBR 是任何磁盘0磁道1扇区,记录了启动操作系统的引导位置和分区表。每个磁盘都会有MBR,因为实际上每个磁盘都可能被作为安装操作系统的盘。
- 1-100,100-200,200-300实际上是分区的范围,具体是柱面号的范围。不用纠结。
- c 盘明显是windows操作系统的启动盘,EXT4是linux分区,这块分区上的文件系统是ext4格式的。
正是由于分区,实现了一块磁盘上可以有不同的文件系统类型,我们现在拿出那块ext4文件系统的分区,对它再细小化。下面是ext4文件系统盘的具体分析。
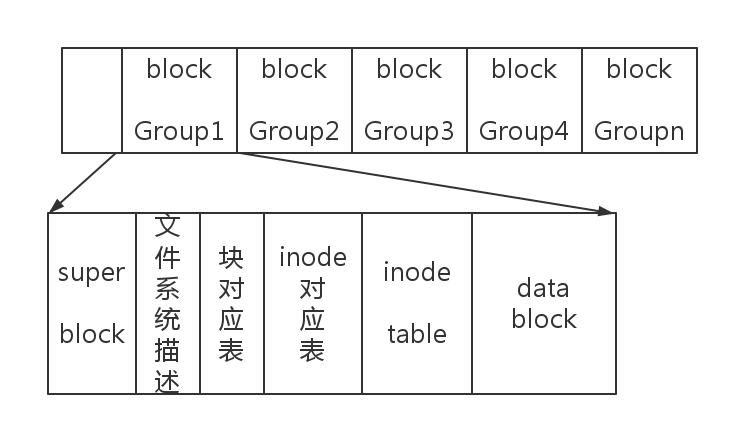
下来我们一一解释它们的含义。
- 前面的空白:实际上每一个分区都会有引导扇区,因为我们多操作系统的PC就是这么实现的。
- block:磁盘最小单位是扇区,一个扇区的大小一般为512个字节(0.5K),但是操作系统读取磁盘的时候并不是按照扇区去读取的,那样的效率太差,而是按照
块,也就是block,一个block大小一般为1K,4K,8K,如果是4K,也就是一个block实际上是8个扇区。 - block Group :还是为了简化管理,将磁盘空间分组,每个组内部的结构是一样的。相当于区域自治。拥有自己的inode,自己的block数,都是自己分配的。
- super block:超级块,它记录的是整个文件系统的信息,文件系统的类型,inode数量,block数量,文件系统各种时间等,是对文件系统整个进行把握,由于每个block group都位于相同的文件系统下,所以它们的super block信息实际上是一样的,而且在内核初始化它内部的数据结构时直接使用block Group0的信息就行了。
- 文件系统描述:描述每个block group 的开始与结束的block号码。
- 块对应表(block bitmap):用bit位记录了每一个block目前的状态,如果有数据就置为1,没有数据置为0。如果需要分配block,那么就找目前状态为0的。
- inode 对应表(inode bitmap):和块对应表相似,记录的是inode的分配和未分配的号码。
- inode table:详细记录了每一个inode的信息。inode中记录的信息有:文件的访问模式,文件权限,文件的ID,文件的时间,文件内容的block号码,12个直接指向,1个间接指向,1个双间接指向,1个三间接指向。如果正在被使用,则将相应的位置为1,要是删除了文件,那就将相应位置置为0。
- data block :详细记录文件数据的地方,每一个block都有block号码。
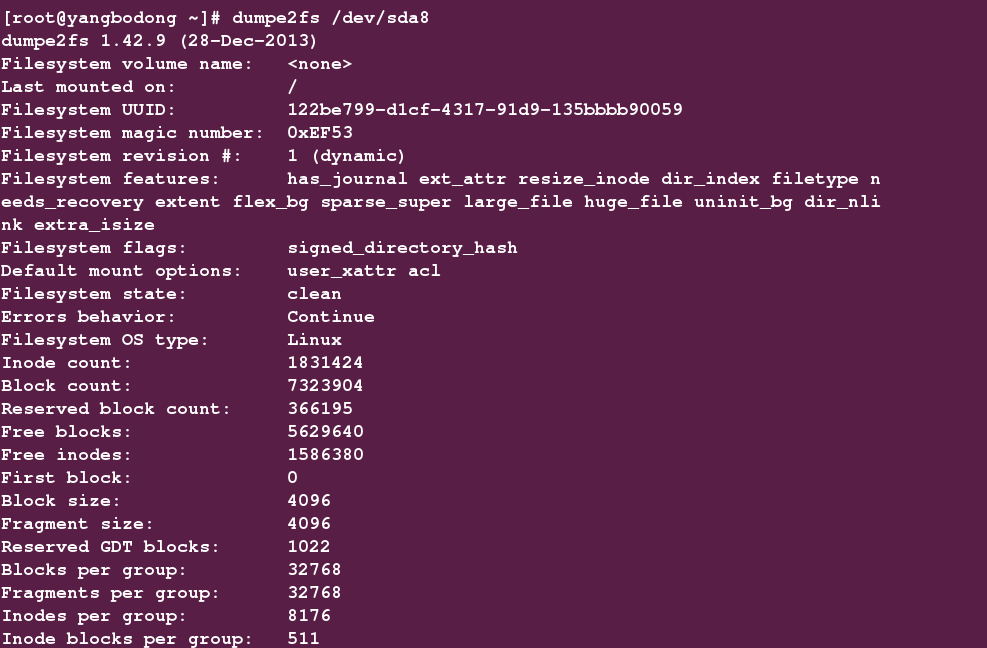
对于上面的这些定义我们可以用dumpe2fs来查看,这个命令实际上是通过查看文件系统super block完成的。
[root@yangbodong ~]# dumpe2fs /dev/sda8
截图参略了后面的block group
下面我想和大家探讨一个问题,我们已经知道。FAT和Ext文件系统组织数据方式是不一样的,那么我们能在不同文件系统间传递数据吗?按道理在不同的文件系统之间数据不能直接传递啊…..因为数据组织方式不一样,但事实上是完全没有问题的,因为我们一直在这么干。谁说Linux系统就不能用U盘了。U盘就是FAT格式的啊。那为什么可以跨文件系统呢?我们看下面的图片。
虚拟文件系统
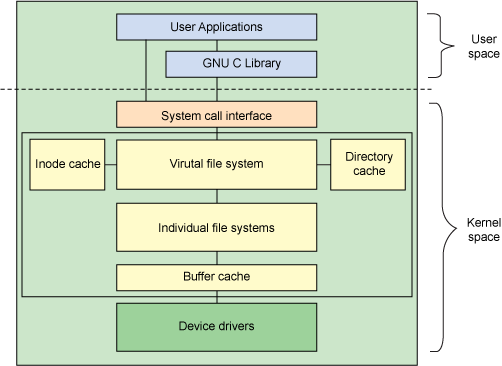
之所以能实现跨文件系统的cp,就是因为虚拟文件系统,它和文件系统的关系是什么?它是Linux文件系统设计最巧妙的地方,也是Linux文件系统最重要的一部分。
我们看这个图,用户层通过系统调用和内核交互,假设用户层的命令就是从FAT文件系统cp文件到ext4文件系统,虚拟文件系统实际干了这样一个事,它提供了统一的数据结构,向上屏蔽,向下兼容。
- 统一的数据结构:超级块用来描述文件系统的信息;inode,每一个文件都是一个inode,inode数据结构描述文件;目录项,比如我们查找/home/file的过程,/,home/,file都是目录项,通过它们才能索引到最终的文件。
- 向下兼容:虽然linux内核支持多达40多种文件系统,但是无论是什么文件系统,都必须支持VFS提供的统一的数据结构,VFS不会关心具体文件系统得到统一的数据结构之后的处理过程,但是任意一个文件系统要想被Linux操作系统支持,那么必须提供VFS要求的统一的数据结构。
- 向上屏蔽:上一层实际上还到不了用户层,我们的向上屏蔽是对于系统调用而言的,比如read和write操作的数据结构就是我们刚才说的那几个数据结构,这些系统调用不用针对不同的文件系统去采取不同的处理方式。
这也是VFS的设计精妙之处。所以跨文件系统的cp实际上是FAT按照它的方式将数据读出来组织成VFS识别的数据结构传递给VFS,然后VFS再将数据结构写入ext4,ext4再按照自己对数据的组织方式将数据保存。正是因为有VFS这一层,Linux才真正实现了支持多种文件系统。下面我想大家肯定好奇VFS到底定义的数据结构是怎样的,怎么就能这么神奇,那么我们接下来去看看这些主要的数据结构。
VFS主要的数据结构
1:Super Block

2:inode

3:dentry

4:file

这是4个主要的数据结构,当然,它们当中也省略了好多方法,要想详细了解,推荐:VFS数据结构
下面我兑现承诺,说我们最初提出来的两个问题:
touch file 的过程
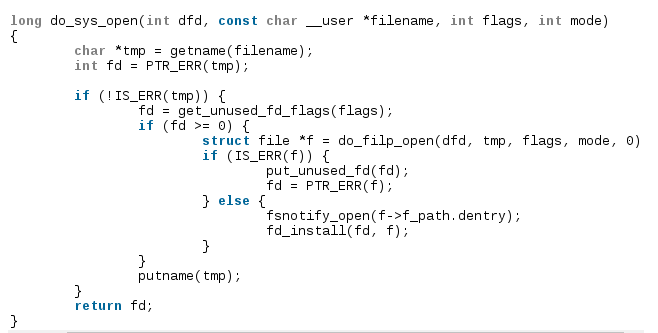
本质上touch命令实现方式是open系统调用,open具体调用do_sys_open。
- getname:将用户态的文件名转换成内核态。
- get_unused_fd_flags(flags):返回一个可以用的文件描述符,文件描述符保存在进程task_struct中files_struct中,是一个fd数组。
- do_filp_open:file对象根据传入的文件名查找是否有这样的file,如果有的话,touch命令会将file打开,更新时间,要是没有查找到file,并且传入的mode中有O_create标志,那就重新申请inode结点。并且分配新的block.最后返回fd。
linux下一切都是文件?
正是因为虚拟文件系统通过定义通用的数据结构,向下兼容,向上屏蔽。所以我们对于文件的操作都是通过操作VFS定义的数据结构,包括某些设备,比如网络编程中的套接字
#include <sys/types.h> /* See NOTES */
#include <sys/socket.h>
int socket(int domain, int type, int protocol);我们知道socket函数返回的是fd,实际上就是task_struct中files_struct中fd数组中的一个,也就是进程打开的文件中一个file对象,我们以后包括recv函数从内核中读取数据,组织数据的方式也是用虚拟文件系统中定义的几个数据结构。这就是linux下一切皆是文件的解释,这里的文件实际上并不是我们普通操作的文件,而是linux操作系统对于磁盘的抽象,就像进程是对CPU的抽象一样,文件是对磁盘的抽象。