不知道大家有没有对.java文件进行编译之后生成的.class文件好奇过。
我们都知道Java中的class文件是经过Java编译器对Java类文件进行编译后的产物。我想有不在少数的C程序员在学习Java之后在认知上会粗略的认为C程序在经过编译后产生的.out文件与.class文件在各方面大概相同,我刚开始也这样迷惑自己,但是随着学习的深入,我们必须搞清楚.class文件到底是个什么东西。
那么今天我就为大家来分享一下Java中的.class文件到底是什么,它里面到底存储了哪些内容~
对了,如果你用IDEA这种环境集成开发工具来查阅.class文件的话,会发现它和源代码并没有什么区别,因为它将.class文件顺便进行了反编译。
.class文件和.out文件的不同
要想明白两个文件的不同,我们首先要了解两个文件的定义。
.class文件
java的编译器在编译java类文件时,会将原有的文本文件(.java)翻译成二进制的字节码,并将这些字节码存储在.class文件。
也就是说java类文件中的属性、方法,以及类中的常量信息,都会被分别存储在.class文件中。
从这段话中我们提取出重点:.class文件是二进制的字节码。由JVM识别、分析、执行。
能直接阅读字节码也是工作中分析Java代码语义问题的必要工具和基本技能。
.out文件
C语言源程序(.c文件),经编译器编译,由源代码生成机器指令,并加上描述信息,保存在.out文件(可执行文件)中。可执行文件能被操作系统加载运行,计算机执行该文件中的机器指令。
从这段话中我们提取出重点:.out文件是二进制的机器指令。由操作系统加载运行。
此时两个文件的区别已经非常明显:首先两个文件虽然都是二进制,但存储方式是完全不同的,一个是字节码,一个是机器指令。然后运行平台不同,一个是操作系统,一个是虚拟机。
.class文件的意义
理解了上面那段话,虽然我们从本质上已经知道了两个文件有什么区别,但在使用的时候却依然感觉不到任何差别,两个都是可执行文件啊,字节码和机器指令到底有什么区别呢?
从上有关计算机的第一堂课开始,老师就一直告诉我们,“计算机只认识二进制的数据,在计算机的内部,它运行的本质,就是一串010101010101… …”,这串010101… … 就是机器指令,所以操作系统可以对.out文件进行加载,运行。
那字节码是什么呢?思考这个问题的时候,你可以想一下Java的优势在哪里。有没有记得在Java界流传这样一句话,“一次编写,到处运行”。没错,字节码就是提供平台无关性的基石。
Java程序在各种不同的平台上进行编译却都生成相同的字节码,这些字节码由JVM进行加载,运行。这种统一的程序存储格式,从而实现了Java的跨平台性。
说点题外话,虚拟机如今的另一大中立特性已经越来越被开发者所重视——语言无关性,也就是说Java虚拟机已经不仅仅可以执行Java程序,像JRuby,Groovy等等其他语言都可以在Java虚拟机上运行。
.class文件整体结构
要想了解.class文件里面存储的具体内容,我们首先要对.class文件的整体存储结构有一个全面的认识。当然在这之前,我们先来对.class文件做个详细的定义。
任何一个类或接口都对应唯一的.class文件,具体来说如下图:(盗别人的图)
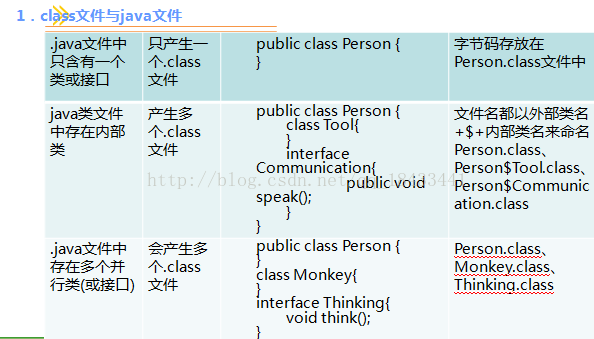
Class文件是一组以字节为基础单位的二进制流,各个数据项目紧凑的排列在Class文件中。并且数据项的存储方式类似于大端模式,不了解大端模式的自行百度。
Class文件结构中只含有两种数据类型:无符号数与表。所以并不复杂。
无符号数就是基本的数据类型,我们以u1,u2,u4,u8分别来表示1个字节,2个字节,4个字节,8个字节。无符号数可以用来描述数字,索引引用,数量值或是UTF-8编码构成的字符串。如果你对上面这句话感到抽象,别急,看到最后再回过头,就会发现疑惑已经自行解决。
表是由多个无符号数或其他表作为数据项构成的复合数据结构,习惯以“_info”结尾。Class文件本质上就是一张表。
下面贴出Class文件格式:

好了,Class文件的基本介绍已经完成。那么就来看看要深入学习Class类文件结构,我们应该从哪几个方面入手吧。
对应上图,我们需要着重了解魔数、Class文件版本、常量池、类索引,父类索引,接口索引集合、字段表集合、方法表集合、属性表集合等Class文件的重要组成部分。对于属性表集合的讲解,我会放到第二篇中。
魔数与Class文件版本
要学习Class文件的结构组成,肯定需要一个Class文件来让我们进行分析。所以我们来看一段简单的Java代码并对它进行编译,这段代码及所产生的Class文件之后会一直使用,所以不要看过去就进行遗忘~~
public class TestClass {
private int m;
public int inc() {
return m+1;
}
}我们在Ubuntu 16.04下使用GHex16进制文本编辑器对编译后产生的.class文件进行查看。如下图:
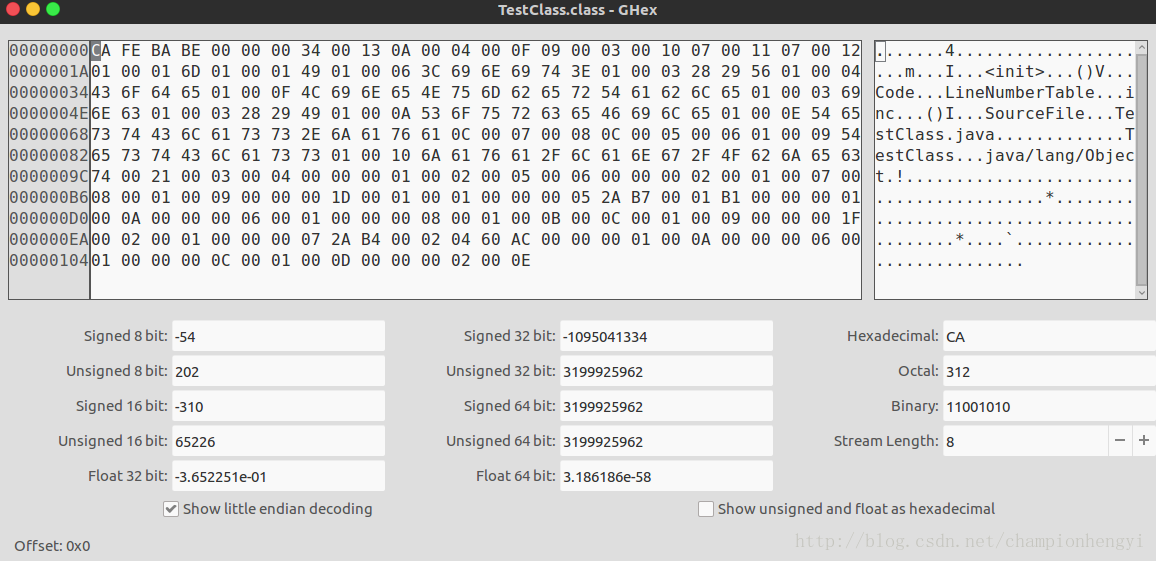
魔数是每个Class文件的头四个字节,作用为确定这个文件是否是一个能被虚拟机接受的Class文件。它的值也非常的好记,充满了浪漫气息:CAFEBABE(咖啡宝贝?),和Java的logo似乎有某种联系~~
仅接着魔数的4个字节存储的就是Class文件的版本号:5、6字节是次版本号,7、8字节是主版本号,这四个字节的作用一般是用来让我们分辨当前的JDK版本,高版本的JDK可以向下兼容低版本,反过来则不可以。
一般来说我们不需要太在意次版本号,版本号转换对应JDK一般步骤如下:
-将主版本号转换为10进制
-用版本号减去45(JDK版本号从45开始)再加上1
例如上图中我的次版本号为0x00,主版本号为0x34,转换十进制为52,则JDK版本为52-45+1,也就是8,所以我目前的JDK版本为JDK1.8,没有错误。
常量池
要说Class文件中的重要组成部分是什么,我觉得肯定属于常量池(其它项目关联最多数据类型,Class文件空间最大的数据项目之一,表类型数据项目)和属性表,关于属性表的部分我们下次再说。
Java虚拟机运行时方法区中的常量池就是将类加载进内存之后.class文件中的常量池。
常量池容量计数
常量池的入口处首先是一项u2类型(无符号,2个字节)的数据,代表常量池容量计数值,设置这个值的原因乃是由于常量池中常量的数量并不固定。从上图中可以看到此Class文件的常量池容量为0x0013。
值得一提的是,常量池中的容量计数是从1开始而不是从0开始,Class文件中也就只有常量池的容量计数是从1开始。这样设计的目的在于满足后面某些指向常量池的索引值的数据在特定情况下需要表达“不引用任何一个常量池项目”的含义。
所以我的Class文件常量池容量转换为10进制为19,也就是只有18项常量,索引值范围1~18。
常量池存储项目类型
上面说到常量池容量,然后我们需要分析常量池中的内容,在分析常量池中存储的内容之前,我们需要对常量池的存储类型做一个介绍。
常量池中主要存放两大常量:字面量和符号引用。
字面量接近于Java语言层面的常量概念,如文本字符串,final常量值等。
符号引用包含下面三类常量(关于全限定名与描述符稍后再说):
- 类和接口的全限定名
- 字段的名称和描述符
- 方法的名称和描述符
Javap命令
有人说,那以后工作如果让我们阅读Class文件中的字节码岂不是要累死,放心,如今是一个讲求效率的时代,不再是以前写程序都要程序员一个个进行打孔的时代。
我们可以使用Javap命令借助计算机进行常量表的输出。
我们来看一下用法:
//TestClass 就是我们上面TestClass.java文件编译后产生的Class文件
javap -verbose TestClass看一下输出结果:(省略了常量池以外的信息)
Classfile /home/hg_yi/深入理解Java虚拟机/类文件结构/TestClass.class
Last modified 2017-10-20; size 275 bytes
MD5 checksum 4bb559d0c40918dfedd533c18bd75add
Compiled from "TestClass.java"
public class TestClass
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #4.#15 // java/lang/Object."<init>":()V
#2 = Fieldref #3.#16 // TestClass.m:I
#3 = Class #17 // TestClass
#4 = Class #18 // java/lang/Object
#5 = Utf8 m
#6 = Utf8 I
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 inc
#12 = Utf8 ()I
#13 = Utf8 SourceFile
#14 = Utf8 TestClass.java
#15 = NameAndType #7:#8 // "<init>":()V
#16 = NameAndType #5:#6 // m:I
#17 = Utf8 TestClass
#18 = Utf8 java/lang/Object我们之前说过Class文件中还有很多数据项都要引用常量池中的常量,所以上面输出的结果在后面还会使用,不要遗忘~~
上面的输出结果中有很多信息都与我们刚才分析Class文件所得的结果相符:
1.次版本与主版本号:
minor version: 0
major version: 522.索引值范围:
#1——#183.常量池项目类型分析
#1 = Methodref #4.#15 // java/lang/Object."<init>":()V上述代码表示第一项常量指向第4和第15项常量。
至于java/lang/Object."<init>":()V这个东西,有关我们之前说的类的全限定名与描述符,等一下再说。
访问标志
常量池结束之后,仅接的两个字节代表访问标志,用于标识一些类或者接口层次的信息,包括:这个Class是类还是接口;是否定义为public类型;是否定义为abstract类型;如果是类,是否被声明为final等。
具体标志位及含义如下:

从上面使用Javap命令输出常量表结构之后有这样一行代码:
flags: ACC_PUBLIC, ACC_SUPER我们查看访问标志可知,这个flags对类的描述是正确的,因此它的access_flags的值应为:0x0001|0x0020=0x0021。如果你对应最上面原始的字节码,会发现这个和在常量池后面所占两个字节所显示的数值相一致。
类索引、父类索引、接口索引集合
访问标志之后,就是类索引和父类索引、接口索引集合了。类索引、父类索引都是一个u2类型的数据,而接口索引集合是一组u2类型的数据集合,Class文件用这三项数据来确定这个类的继承关系。
- 类索引确定类的全限定名;
- 父类索引确定这个类父类的全限定名;
- 接口索引集合确定这个类实现了哪些接口,被实现的接口将按implements语句后的接口顺序从左到右排列在接口索引集合中。
提示:由于Java是单根继承,并且所有的Java类都有Object这个父类,除了java.lang.Object本身,所以除过Object,Java类的父类索引都不为0。
我们继续使用刚开始的例子:
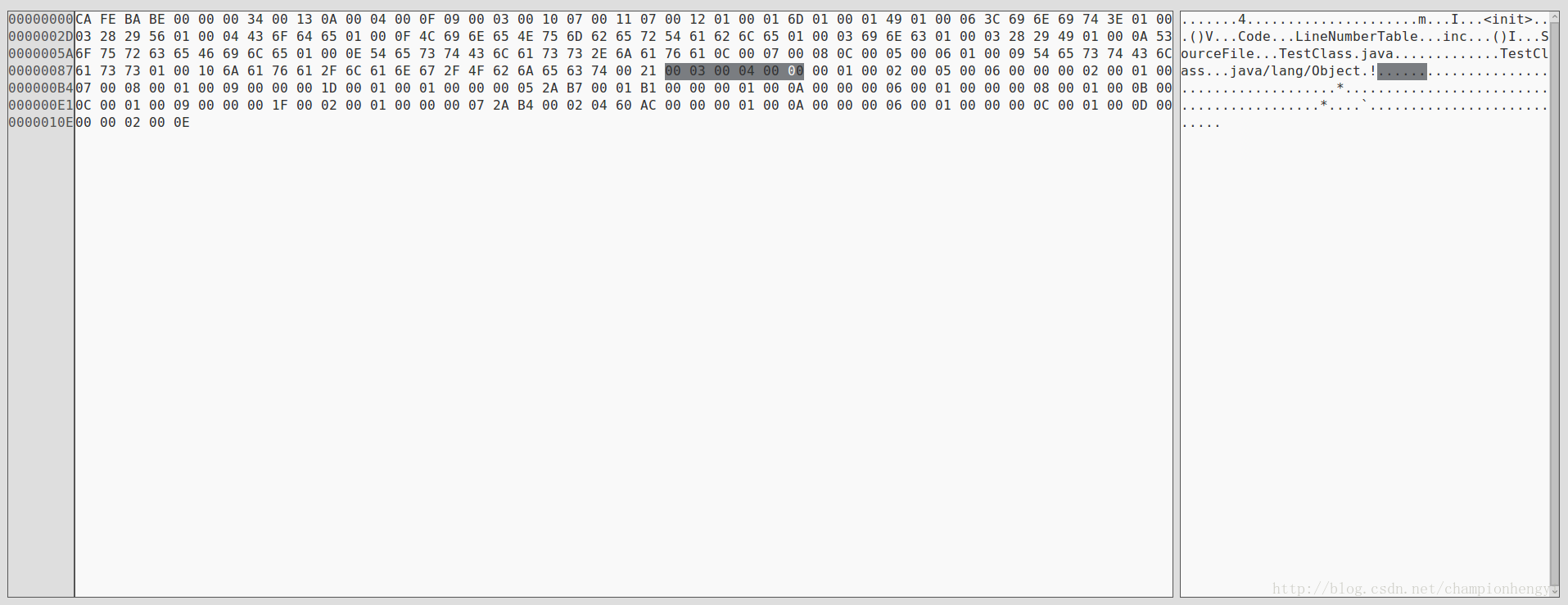
上图中我标记出来的字节码分别为0x0003、0x0004、0x0000,也就是说类索引为常量池中的第3常量、父类索引为常量池中的第4常量。而接口索引有点不同,接口索引的第一项—u2类型的数据为接口计数器,表示索引表的容量。如我刚才所说,可知接口计数器值为0,后面接口的索引表不再占用任何字节。
结合我们刚才Javap命令的输出结果:
#3 = Class #17 // TestClass
#4 = Class #18 // java/lang/Object
#17 = Utf8 TestClass
#18 = Utf8 java/lang/Object可以看到第3、4常量又分别指向17、18常量,而它们的值分别为UTF-8格式的TestClass和java/lang/Object。
这一部分分析完毕。
字段表集合
字段表的介绍
此表用于描述接口或类中声明的变量。
字段包括类级变量(static)和实例级变量,但不包括局部变量。
字段包含哪些信息?
字段作用域(public、private、protected)、static、final、volatile、transient(序列化)、字段数据类型、字段名称。
除了字段数据类型、字段名称的字节长度无法固定而需要引用常量池中的内容外,其它修饰符都很适合用标志位来表示。
因此字段表主要存储了以下信息:
名称索引、描述符索引、访问标志、属性表
至于后面的attributes_info用来描述一个字段的额外信息,如:final static int m = 123;,字段表中就会有一个ConstantValue的属性,其值指向常量123。
接下来就介绍什么叫做“简单名称、全限定名、描述符”。
简单名称、全限定名、描述符
我们再回过头看看字段表结构中的其它数据:名称索引和描述符索引。它们都是对常量池的引用,分别代表着字段的简单名称以及字段和方法的描述符。
关于简单名称就是指没有类型和参数修饰的方法或字段名称,这个类中的inc()方法和m字段的简单名称分别是“inc”和“m”。
描述符相对来说比较复杂,而我们在上面留的那个问题,就是关于描述符的。描述符的作用是用来描述字段的数据类型、方法的参数列表(包括数量、类型、顺序)和返回值。
基本数据类型以及void都用一个大写字符表示,而对象类型用字符L加对象的全限定名来表示。

对于数组类型,每一个维度将使用一个前置的“[”字符来描述,例如定义一个“java.lang.String[][]”类型的二维数组,会被记录为:“[[Ljava/lang/String;”,说到这就不得不提全限定名的表示方法了。
全限定名顾名思义就是完整名称,但是它的表示方法和我们平常书写有所不同,例如我们最开始的测试类的全限定名为”org/fenixsoft/clazz/TestClass;”,它是把类全名中的“.”替换成“/”,并在最后加上“;”而表示全限定名的结束。
描述符的使用
先参数列表、后返回值。
你不懂啥意思?来直接看例子:
void inc()java.lang.String.toString()int indexOf(char[] source, int sourceOffset, int sourceCount, char[] target, int targetOffset, int targetCount, int fromIndex)描述符语言:
()V()Ljava/lang/String;([CII[CIII)I实例分析
类索引,父类索引、接口索引集合之后便是字段表,它的第一个u2类型数据为容量计数器field_flags。由上面的图可知值为0x0001,也就是说只有一个字段,接下来的u2便是access_flags标志… …依次类推,字段表的固定数据项目分析完成。
注意:最后,字段表集合不会列出从父类中继承而来的字段,但有可能列出原本Java代码里面不存在的字段,譬如在内部类中为了保持对外部类的访问性,会自动添加指向外部类实例的字段。
还有对于字节码来说,如果两个字段的描述符不一致,那字段重名就是合法的。这在Java里面显然是不可能的。
方法表集合
方法表与字段表十分相似,在这里我给出方法表的访问标志:

关于方法表的分析我不在赘述,与前面的分析结果都基本相同。我们来看一下在方法表中需要的注意的几个方面:
- 方法里面的代码存储在“Code”属性中,我们在下一节中进行讲述。
- 方法表集合的入口也有一个u2类型的计数器容量的数据。
- 方法表中也有可能出现编译器自动添加的方法,如<clinit> 方法。
- 在Class文件中,描述符不完全一致的方法也可以共存,也就是说在Class文件中就算只有返回值不同,也是一种重载。