Tesseract:训练
05 May 2015资源文件
在上一篇文章中已经讲述了 Tesseract 的基本使用,同时也提到, Tesseract 在识别是需要使用存储在磁盘上的 "语言文件" —— 为不产生歧义,这里简单以 "资源文件" 称呼它。在 Windows 系统上,这些资源文件可以在安装目录下的 tessdata 目录下找到;在 Linux 系统上,这些资源文件通常是在 /usr/share/tesseract-ocr/tessdata 目录下。按照 Tesseract 的约定,这些资源文件以 "traineddata" 作为后缀,除去后缀的部分则是该资源文件的 "名称" ,在使用 Tesseract 命令行工具或者 API 时,就通过这个名称来引用需要的资源文件。比如我们要用英语的资源文件来识别一张图像,通常会这么写:
tesseract input.png output -l eng
上述命令将会引用 eng.traineddata 这个资源文件。在 API 使用中同理。
除了默认的路径, Tesseract 还会在环境变量 TESSDATA_PREFIX 指定的目录中的 tessdata 目录下寻找资源文件 —— 事实上在 Windows 系统中,安装系统就是把该环境变量的值设置成了 Tesseract 的安装目录。这方便我们管理我们自己生成的资源文件。
如果系统中没有资源文件,或者没有需要的资源文件,该如何获取呢?一种办法是到 Tesseract 的下载页面去下载,在 "Summary+Labels" 一栏标注中有 "language data" 的就是了。对于 Linux 系统,可以直接从软件仓库中安装,以 Debian 为例,假如我们需要安装繁体中文的资源文件,可以执行
sudo apt-get install tesseract-ocr-chi-tra
如果不知道需要的资源文件在安装时用什么名称,可以使用 aptitude 进行搜索,在描述字段会有说明。
aptitude search tesseract-ocr-
存储位置与获取方式讲完了,如果是一个有足够好奇心的人,肯定会想了解一下这个资源文件里有什么内容 —— 哈,说得就是我自己啦!当然啦,我也是后面才知道怎么去查看的。
Tesseract 提供了工具来将一个资源文件打开,这个工具叫做 combine_tessdata ,它的更常用的功能是将训练过程中产生的各种资源打包到一起产生一个 Tesseract 可用的资源文件。以 eng.traineddata 为例,我们可以这样来解开它
combine_tessdata -u /usr/share/tesseract-ocr/tessdata/eng.traineddata english/eng
上述命令将会把 eng.traineddata 解开并将结果保存到 english 目录下,所有结果文件都会以 eng 作为前缀。需要注意的是,这里如果 english 这个目录不存在,是会出错的。下面是我在我的系统上的一次实际操作:
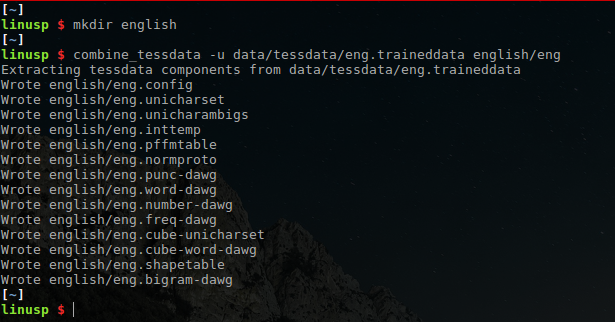
可以看到,这个资源文件里包含了很多东西,这些文件各自的意义为:
- config: 配置文件
- unicharset: 字符集文件,所谓 "字符集" 即是所有可被识别的字符的集合
- unicharambigs: 识别歧义修正文件
- inttemp: 每个字符的 "原型" ,或者是 "标准型" ,当然啦,这里面其实是包含了字符的各种特征,并不是一个标准的 "字符图像"
- pffmtable: 指明了每个字符的特征数量
- normproto: 项目网站上的说法是 "normalization sensitivity prototypes" ,不知道怎么翻译合适
- 以 dawg 结尾的文件: 有向非循环词图(Directed Acyclic Word Graph, DAWG)文件,用来增强、调整识别过程
- cube-unicharset, cube-word-dawg: 用于 Tesseract 内部名为 CUBE 的识别引擎,无资料,不详
- shapetable: 同样是个不知道如何翻译的家伙,反正项目网站上说这个文件已经不需要使用(但还是得有这个文件),就不纠结了
对于这些文件,我们可以用 combine_tessdata 将其重新打包起来:
cd english
combine_tessdata eng
上述命令会在该目录下寻找前缀为 eng 的必要文件,然后打包成 eng.traineddata。这些文件里面有一些是资源文件的必须成分,有一些则是锦上添花的成分。读者可以试试进入到这些文件所在的目录,尝试去掉其中一些然后进行打包操作。
资源文件的训练
如果刚才按照建议进行过了尝试,应该能发现哪些是必要的文件,它们是:
- unicharset
- inttemp
- pffmtable
- normproto
- shapetable
训练的过程就是为了从训练数据中产生这些东西。
数据准备
首先要准备好训练用的文本数据,根据不同的应用场景,对文本数据的要求会不一样。这些文本数据有两个用途:
- 用以产生字符集
- 用以产生语言模型
产生字符集好理解,数据文件应尽量涵盖可能出现的字 —— 不过字符集越大,在使用生成的资源文件进行识别时时间消耗也会越大,所以应该根据实际情况进行折衷处理,比如说汉语的识别,一般来说涵盖了国标一级常用汉字(3755个)就已经足够了。
除了字符集尽量涵盖可能出现的字外,我们也希望训练用的数据中的文字组合能尽量贴合真实场景,我们可以用这些数据来产生语言模型信息添加到最后的资源文件中。之前例子中的 DAWG 文件中就承载了这些信息。不过比较遗憾的是,对于中文训练,我目前知道的只是添加高频词表(freq-dawg)与词表(word-dawg),如何添加 ngram 信息目前毫无头绪。将简体中文资源文件 chi_sim.traieddata 解开后里面有一个名为 chi_sim.fixed-length-dawgs 的文件,从项目网站上来看,应该是与 ngram 信息对应的文件,但该文件无法解开,项目网站上对这个文件也是语焉不详。 如果有对这个问题的解决办法,请不吝赐教。
所以这一步要做的事情有两个:
- 数据清洗,这个和自然语言处理里的清洗是一样的
- 字符集提取,简单来说,排序、去重即可
其中清洗后的数据用来提取语言模型信息,去重后的字符集数据用来进行训练。
项目网站上说到,每个字在训练用的数据文件中一般应该有 10 个样本,低频字也至少要有 5 个,高频的应该在 20 个以上。不过就我目前进行的中文训练情况来看,每个字一个样本得到的结果也没有明显的差异,读者可以自行试验。
需要注意的是,在生成图像时可能存在一部分字符要用某个字体来表示,而另一部分字符要用另外一个字体来表示 —— 比如汉字通常用宋体而英文可能用 Time News Roman ,这种情况下建议将数据分割成开来。
图像与BOX文件生成
有了数据文件后,我们需要用这些数据文件中的文字来生成图像,用这些图像去进行训练。在 3.03 后, Tesseract 已经提供了相应的工具 text2image,使用方法为:
text2image --text=chinese.txt --outputbase=chinese.sun.exp0 --font="SimSun" --fonts_dir=./fonts/
上述命令以 chinese.txt 作为输入,字体使用宋体,将图像输出为 chinese.sun.exp0.tif。同时还会输出一个名为 chinse.sun.exp0.box 的 BOX 文件,里面会对应每一个文字在图像中的位置信息。
同一个数据文件,可以应用不同的字体产生不同的图像,字体越多,产生的资源文件所能支持的实际情况也就越多,但建议还是按照实际应用情况来添加字体支持。
字符集文件与字体信息文件生成
提取 Tesseract 能读取、处理的字符集文件,使用 unicharset_extractor 命令:
unicharset_extractor chinses.box english.box
该命令以上一步输出的 BOX 文件作为输入,实际使用时,应将本次训练时的所有 BOX 文件作为输入。该命令的输出是名为 unicharset 的文件。
此外,在后续步骤中需要字体属性文件,该文件的名称应为 font_properties ,该文件中每一行表示一种字体的信息,其格式为:
<font name> <italic?> <bold?> <fixed?> <serif?> <fraktur?>
第一个字段为字体名称,名称中不能有空格,名称可以任意,但建议尽量贴近字体在操作系统上的名称,后面五个字段分别表示:
- 该字体是否有斜体
- 该字体是否有粗体
- 该字体是否有无衬线体
- 该字体是否有衬线体
- 该字体是否有哥特体
比如宋体是有衬线体的,对应的,它在 font_properties 这个文件中的内容应为:
SimSun 1 1 0 1 0
特征文件生成
特征文件的生成使用 tesseract 命令:
tesseract chinese.sun.exp0.tif chinese.sun.exp0 nobatch box.train
上述命令将生成名为 chinese.sun.exp0.tr 的特征文件。对每一张生成的 TIFF 图像,都要进行该步骤以生成特征文件。
聚集
上一步的特征文件生成后,需要将同样文字的不同字体的特征聚集到一起来产生该文字的一个 原型 ,这一步需要执行三个命令:
shape_clustering -F font_properties -U unicharset *.tr
这一步将会生成一个名为 shapetable 的文件。
mftraining -F font_properties -U unicharset -O banker.unicharset *.tr
这一步将会生成一个名为 inttemp 的文件和一个名为 pffmtable 的文件。
cntraining *.tr
这一步将会生成一个名为 normproto 的文件。
[可选]添加配置文件、歧义修正文件、DAWG文件
略(后面补上)
打包
在上述步骤都完成后,将要打包入资源文件的那些文件加上一个统一的前缀,该前缀即是待生成的资源文件的名称,这里假定我们要生成 chi.traineddata 这样一个资源文件,那么我们的可能操作就是:
mv unicharset chi.unicharset mv shapetable chi.shapetable mv inttemp chi.inttemp mv pffmtable chi.pffmtable mv normproto chi.normproto combine_tessdata chi
至此,训练过程结束。