写在前面:
分页机制完成线性地址到物理地址的转换 80x86 规定分页机制是可选的。分段和分页没有什么必然联系,分段可以说是 Intel 的 CPU 一直保持着的一种机制,而分页只是保护模式下的一种内存管理策略。想开启分页机制,CPU必须工作在保护模式,而工作在保护模式可以不开启分页。
分页机制由控制寄存器 CR0 中的 PG 位启用,如PG=1则启用分页机制,把线性地址转换为物理地址;如果PG=0则直接把段机制产生的线性地址当作物理地址使用。
为什么要分页?
问题的本质是在目前只分段的情况, CPU 认为线性地址等于物理地址,而线性地址是由编译器编译出来的,它本身是连续的,所以物理地址也必须要连续才行,但我们可用的物理地址不连续。换句话说,如果线性地址连续,而物理地址可以不连续,不就解决了吗。所以要解除线性地址和物理地址一一对应的关系,然后将他们的关系重新建立,通过某种映射关系,可以将线性地址映射到任意物理地址。
页与页表
为了效率起见,将线性地址空间分成若干大小相等的片,称为页( Page )。相应的地,逻辑上把内存划分为与页大小相等的若干存储块,称为( 物理 )块或页面( Page Frame )。常见的页面大小为 4KB,每一页都有 4K 字节长,每一页的起始地址都能被 4K 整除。
分页机制通过把线性地址空间中的页,重新定位到物理地址空间来进行管理,因为每个页面的整个 4K 字节作为一个单位来映射,并且每个页面都对齐 4K 字节的边界,因此,线性地址的低 12 位经过分页机制直接地作为物理地址的低 12 位使用。所以,线性地址的高 20位可用来定位一个物理页,低 12 位可用来在该物理页内寻址。
页表项结构
页表就是个 N 行 l 列的表格,页表中的每一行(只有一个单元格)称为页表项( Page Table Entry,PTE ),其大小是 4 字节,页表项的作用是存储内存物理地址。当访问一个线性地址时,实际上就是在访问页表项中所记录的物理内存地址。
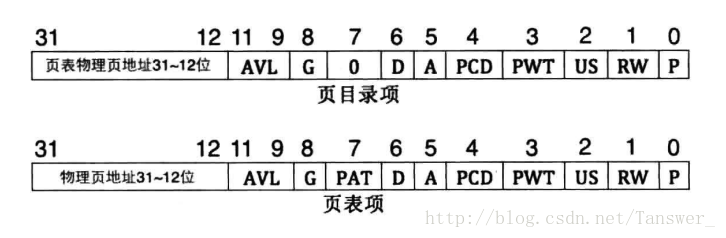
不管是页目录还是页表,每个表项占4个字节,其表项结构基本相同,如上图。
页面地址对页目录而言,指的是页表所在的物理页面在内存的起始地址;对页表而言,指的是页所对应的物理页面在内存的起始物理地址。页面的起始地址是 4K 的整数倍,所以页面项的低 12 位另做它用,内核用这 12 位来存放页的属性。
属性包括以下内容:
- 第0位是存在位,如果P=1,表示该页存在于物理内存中,如果P=0,表示不在物理内存中。
- 第1位是读/写位,若为1表示可读可写,若为0表示可读不可写。
- 第2位是普通用户/超级用户位,这两位为页目录项提供硬件保护。当特权级为3的进程要想访问页面时,需要通过页保护检查,而特权级为0的进程就可以绕过页保护。
- 第3位是PWT(Page Write-Through)位,表示是否采用写透方式,写透方式就是既写内存(RAM)也写高速缓存,该位为1表示采用写透方式
- 第4位是PCD(Page Cache Disable)位,表示是否启用高速缓存,该位为1表示启用高速缓存。
- 第5位是访问位,若为 1 表示该页被 CPU 访问过了。
- 第6位是脏页位,当 CPU 对一个页面执行写操作时,就会设置对应页表项的D位为1。仅针对页表项有效,并不会修改目录项中的 D 位。
- 第7位是Page Size标志,只适用于页目录项。如果置为1,页目录项指的是4MB的页面,请看后面的扩展分页。
- 第8位为全局位,用来指定该页是否为全局页,为 1 表示是全局页,为 0 表示不是全局页。若为全局页,该页在高速缓存TLB中一直保存,给出虚拟地址直接给物理地址
- 第9~11位由操作系统专用,Linux也没有做特殊之用。
怎样用线性地址找到页表中对应的页表项?
首先要明确:分页机制打开前,要将页表地址加载到控制寄存器 CR3 中,这个地址是页表的物理地址。虽然分页机制的作用是将线性地址转换成物理地址,但其转换过程相当于在关闭分页机制下进行,过程中所涉及到的页表及页表项的寻址,它们的地址都被 CPU 当作最终的物理地址(本来也是物理地址)直接送上地址总线,不会被分页机制再次转换(否则会无限递归下去)。
一个页表项对应一个页,所以,用线性地址的高 20 位作为页表项的索引,每个页表项要占用 4 字节大小,所以这高 20 位的索引乘以 4 后才是该页表项相对于页表物理地址的字节偏移量。用 CR3 寄存器中的页表物理地址加上此偏移量便是该页表项的物理地址,从该页表项中得到映射的物理地址,然后用线性地址的低 12 位与该物理页地址相加,所得的地址就是最终要访问的物理地址。
为什么使用两级页表?
32 位环境下,4GB 线性空间分成 4KB 一个页,那就是 1M 个页,每个页表项需要 4 个字节来存储,那么整个 4GB 空间的映射就需要 4MB 的内存来存储管理信息。这只是一个线性地址空间的映射,每个进程都有自己的映射,假设有100个进程在运行,就需要 400MB 的内存来存储管理信息,太浪费了 。
一级页表中所有页表项必须提前建好,且要求是连续的。为什么需要连续的呢? 如果不连续,就没有办法通过页表寄存器+偏移量找到对应的页表项了。
所以要解决的是:不要一次性地将页表项全建好,需要时动态创建页表项。二级页表很好的解决了这个问题。
两级页表结构
所谓两级页表就是对页表再进行分页,一个页表内的所有页表项是连续存放的,页表本质上是一堆数据,也是以页为单位存放在主存中。
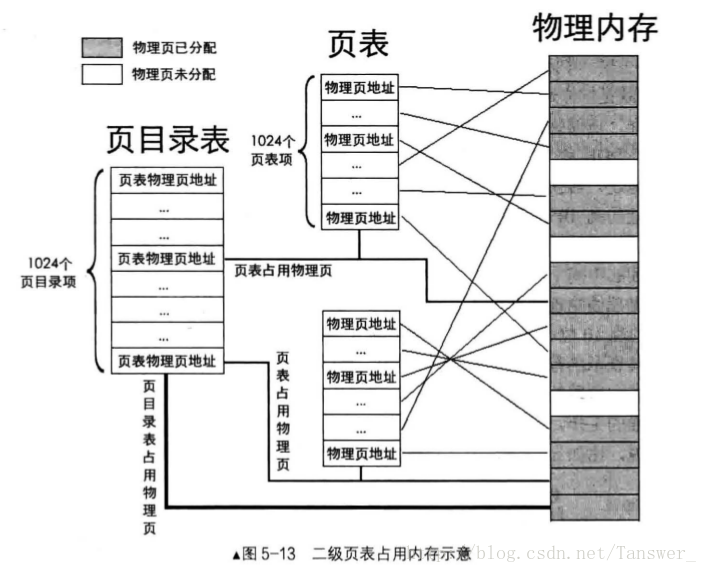
第一级称为页目录表。每个页表的物理地址在页目录表中都以页目录项( Page Directory Entey,PDE ) 的形式来存储,4MB 的页表再次分页可以分为 1K ( 4MB / 4KB )个页,对每个页的描述需要 4 个字节,所以页目录表占用 4K 大小,正好是一个标准页的大小,其指向第二级表。线性地址的高 10 位产生第一级的索引,由索引得到的表项中,指定并选择了 1K 个二级表中的一个页表。
第二级称为页表,存放在一个 4K 大小的页面中,包含 1K 个表项,每个表项包含一个页的物理基地址。线性地址的中间 10 位产生第二级索引,可以获得包含页的物理地址的页表项。这个物理地址的高 20 位与线性地址的低 12 位形成了最终的物理地址。
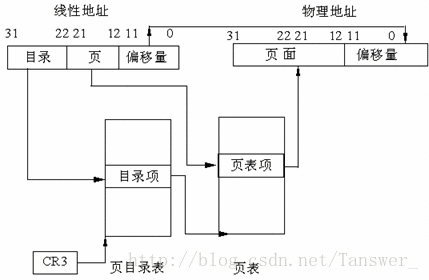
有人觉着这样做的话映射 4GB 地址空间需要 4MB+4KB 的内存,不是更大了吗? 当然不是,在一个进程中,实际使用到的内存远没有4GB这么大,一级页表需要一次分配所有页表空间,且要求是连续的,两级页表则可以在需要的时候再分配页表空间,这样节省内存。
线性地址到物理地址的转换
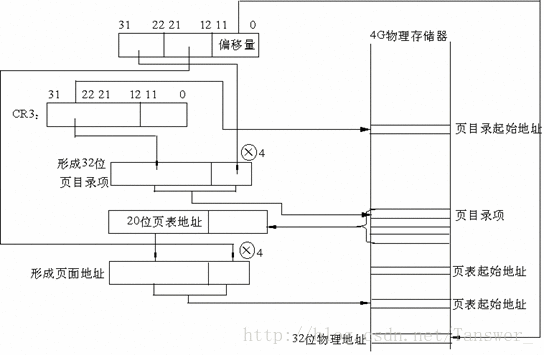
- CR3包含着页目录的起始地址,用32位线性地址的最高10位A31~A22作为页目录的页目录项的索引,将它乘以4,与CR3中的页目录的起始地址相加,形成相应页表的地址。
- 从指定的地址中取出32位页目录项,它的低12位为0,这32位是页表的起始地址。用32位线性地址中的A21~A12位作为页表中的页面的索引,将它乘以4,与页表的起始地址相加,形成32位页面地址。
- 将A11~A0作为相对于页面地址的偏移量,与32位页面地址相加,形成32位物理地址。
整个过程是比较机械的,每次转换先获取物理页基地址,再从线性地址中获取索引,合成物理地址后再访问内存。不管是页表还是要访问的数据都是以页为单位存放在主存中的,因此每次访问内存时都要先获得基址,再通过索引(或偏移)在页内访问数据,因此可以将线性地址看作是若干个索引的集合。
快表 TLB( Translation Lookaside Buffer )简介
分页机制虽然很灵活,但是从线性地址转换为物理地址的过程还是比较麻烦,过程不再赘述。每一个线性地址到物理地址的转换都要重复转换的过程,涉及到多级页表就更显得麻烦。而且处理器的速度和内存的速度完全是两个数量级,页表在内存中,转换过程中频繁的访问内存,使得地址转换的速度慢上加慢。
那能不能通过线性地址直接得到对应的物理地址,免去查表的过程? 答案是可以的,就是应用到缓存,根据程序局部性原理,可以将近来常访问的地址和指令加载到速度更快的设备中。处理器准备了一个高速缓存,专门用来存放虚拟地址页框与物理地址页框的映射关系,这个缓存就是 TLB,俗称快表。
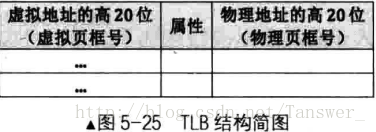
有了 TLB,处理器在寻址之前会用虚拟地址的高 20 位作为索引来查找 TLB 中的相关条目,如果命中则返回虚拟地址所映射的物理页框地址,否则会查询内存中的页表,获得物理地址后再更新 TLB。
Linux中的分页机制
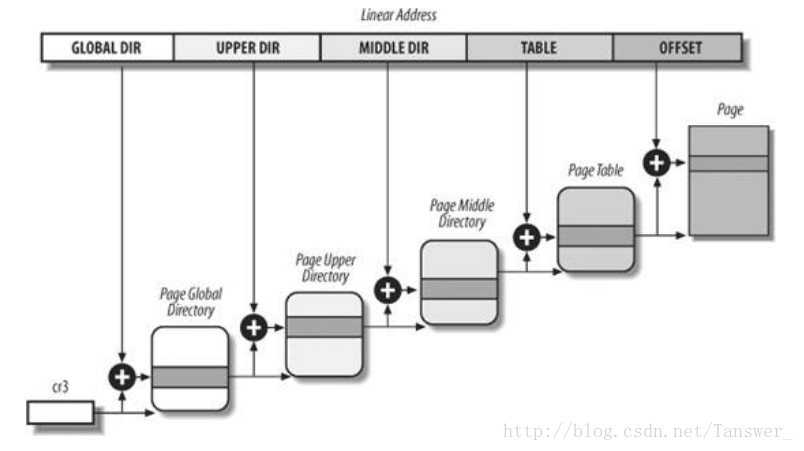
- 页全局目录
- 页顶级目录
- 页中间目录
- 页表
页全局目录包含若干页上级目录的地址,页上级目录又依次包含若干页中间目录的地址,而页中间目录又包含若干页表的地址。每一个页表项指向一个页框。线性地址因此被分成五个部分。图中没有显示位数,因为每一部分的大小与具体的计算机体系结构有关。
对于没有启用物理地址扩展的32位系统,两级页表已经足够了。从本质上说Linux通过使“页上级目录”位和“页中间目录”位全为0,彻底取消了页上级目录和页中间目录字段。不过,页上级目录和页中间目录在指针序列中的位置被保留,以便同样的代码在32位系统和64位系统下都能使用。内核为页上级目录和页中间目录保留了一个位置,这是通过把它们的页目录项数设置为1,并把这两个目录项映射到页全局目录的一个合适的目录项而实现的。
启用了物理地址扩展的32 位系统使用了三级页表。Linux的页全局目录对应80×86 的页目录指针表(PDPT),取消了页上级目录,页中间目录对应80×86的页目录,Linux的页表对应80×86的页表。
最后,64位系统使用三级还是四级分页取决于硬件对线性地址的位的划分。
我们虽然讨论的是Linux的分页机制,实际上我们用了大部分篇幅来讨论Intel CPU的分页机制实现。因为Linux的分页机制是建立在硬件基础之上的,不同的平台需要有不同的实现。Linux在软件层面构造的虚拟地址,最终还是要通过MMU转换为物理地址,也就是说,不管Linux的分页机制是怎样实现的,CPU只按照它的分页实现来解读线性地址,所以Linux传给CPU的线性地址必然是满足硬件实现的。例如说:Linux在32位CPU上,它的四级页表结构就会兼容到硬件的两级页表结构。可见,Linux在软件层面上做了一层抽象,用四级页表的方式兼容32位和64位CPU内存寻址的不同硬件实现。