前言
这周六要去上海比赛,据说要考算法,感觉自己也没啥刷题的基础,就开始看动态规划,之总感觉DP非常的高大上和难理解,所以这两天学会一点就要赶紧总结呀~
因为我也没怎么刷过题,只是这两天看了看,所以如果理解上有不足之处,欢迎各位指正。
正文
感觉大家一说起动态规划,都是感觉非常的难,离我们非常的远,其实不然,费波那契数列(下用fib代替)大家一定都做过。(emmmm一般提到这个都是为了讲 递归,其实这是一部分吧)我觉得求fib就是一种最简单的动态规划,为什么? 先让我们从一道典型的DP题来看看吧。
典型的DP — 数塔
Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)
Total Submission(s): 49209 Accepted Submission(s): 29082
Problem Description
在讲述DP算法的时候,一个经典的例子就是数塔问题,它是这样描述的:
有如下所示的数塔,要求从顶层走到底层,若每一步只能走到相邻的结点,则经过的结点的数字之和最大是多少?
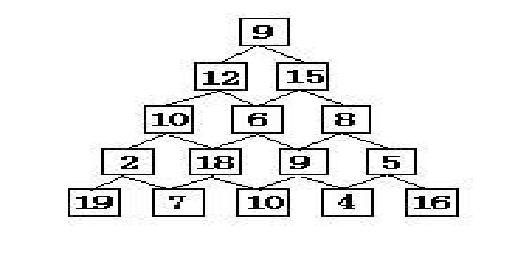
已经告诉你了,这是个DP的题目,你能AC吗?
Input
输入数据首先包括一个整数C,表示测试实例的个数,每个测试实例的第一行是一个整数N(1 <= N <= 100),表示数塔的高度,接下来用N行数字表示数塔,其中第i行有个i个整数,且所有的整数均在区间[0,99]内。
Output
对于每个测试实例,输出可能得到的最大和,每个实例的输出占一行。
Sample Input
1
5
7
3 8
8 1 0
2 7 4 4
4 5 2 6 5
Sample Output
30
我的想法
之前遇到这类问题时,脑子总是一片混乱,因为总想着:从起点开始走,然后每次都走权值大的,,,但是这样局部最优不等于全局最优啊。。。
所以这时候我们就要换一种思路
让我们设result(i,j)为从(i,j)开始往下走的权值和最大值,d(i,j)为(i,j)的权值。那么这个题求的就是result(1,1),从第一层往下走,想要找到最大权值和,那么肯定要找到第二层中的权值和较大值,因为有
result(1,1) = d(1,1) + max{result(2,1), result(2,2)}所以现在我们需要找到result(2,1)和result(2,2)的值,同样有
result(2,1) = d(2,1) + max{result(3,1), result(3,2)}
result(2,2) = d(2,2) + max{result(3,2), result(3,3)}好啦,可以看到规律啦
我们只需要求到最底下,再返回就好了。
当然,我们还可以看出,在求result(2,1)result(2,2)时我们需要计算result(3,1) result(3,2) result(3,3),但是result(3,2)却被多计算了一次,这会大大影响效率,所以我们应该将每次计算的值保存下来,这样避免了无用的重复计算。
代码如下
#include<stdio.h>
#include<string.h>
int array[100][100];//保存每个节点的权值
int result[100][100];//记录每次计算的结果
int num;
int getKey(int r, int c)
{
if(r == num - 1)//当计算到最底下一层,直接返回
return result[r][c] = array[r][c];
int resultA,resultB;
if(result[r+1][c])//如果这个结果不为0,也就是之前已经计算过了那么直接获得,不用再次计算
resultA = result[r+1][c];
else
resultA = getKey(r+1, c);
if(result[r+1][c+1])//同上
resultB = result[r+1][c+1];
else
resultB = getKey(r+1, c+1);
return result[r][c] = array[r][c] + (resultA > resultB ? resultA : resultB); //核心公式
}
int main()
{
int n;
scanf("%d",&n);
while(n--){
scanf("%d",&num);
for(int i = 0; i < num; i++)
for(int j = 0; j <= i; j++)
scanf("%d",&array[i][j]);
printf("%d\n",getKey(0,0));//从(0,0)也就是计算最顶层的最大权值和
memset(result, 0, 100 * 100 * sizeof(int));
}
}
好啦,是不是很简单。
让我们再回过头来看一眼。
我们找到了一个核心公式,也就是
result(i,j) = d(i,j) + max{result(i+1,j), result(i+1,j+1)}这个便是状态转移方程,而result(i,j)则是一个状态。
好啦,让我们趁热打铁再做一道。
典型的DP — 矩形嵌套
时间限制:3000 ms | 内存限制:65535 KB
难度:4
描述
有n个矩形,每个矩形可以用a,b来描述,表示长和宽。矩形X(a,b)可以嵌套在矩形Y(c,d)中当且仅当a < c,b < d或者b < c,a < d(相当于旋转X90度)。例如(1,5)可以嵌套在(6,2)内,但不能嵌套在(3,4)中。你的任务是选出尽可能多的矩形排成一行,使得除最后一个外,每一个矩形都可以嵌套在下一个矩形内。
输入
第一行是一个正正数N(0< N <10),表示测试数据组数,
每组测试数据的第一行是一个正正数n,表示该组测试数据中含有矩形的个数(n <= 1000)
随后的n行,每行有两个数a,b(0 < a,b < 100),表示矩形的长和宽
输出
每组测试数据都输出一个数,表示最多符合条件的矩形数目,每组输出占一行
样例输入
1
10
1 2
2 4
5 8
6 10
7 9
3 1
5 8
12 10
9 7
2 2
样例输出
5
我的想法
对于矩形A和矩形B,如果A可以嵌套B,那么就可以看作是A节点到B节点有一条有向边,很明显,A不能嵌套自己,B也不能再嵌套A。
所以我们就可以把问题抽象为一个有向无环图(DAG),求解的是整个图中的最长边。
依然按照刚才那个题的思路,设从i节点出发的最长边,也就是i的最多嵌套数为d(i),那么我把每个d(i)都求出来,然后找一下最大值就好了。(好暴力)
那么怎么求d(i)呢?
对于i节点来说,有
d(i) = max{d(j) + 1 (i嵌套j,也就是ij有一条有向边)}好呀,你肯定已经想到了,这就是我们的状态转移方程,而d(i)就是这道题的状态。
只需要把每个i嵌套的j的d(j)求出来就好啦。
同样,为了避免重复的计算,我们要记录一下结果。
代码
#include<stdio.h>
#include<string.h>
int graph[1001][1001];//使用邻接矩阵来构建图
int d[1001];//记录装态的d数组
int num;
struct node{
int x,y;
};//node里面的xy就是边长
struct node nodes[1001];//节点数组
int dp(int i)
{
int &ans = d[i];//用一下引用,提高可读性
if(ans > 0)
return ans;//如果d(i)被计算过直接返回
ans = 1;
for(int j = 0; j < 1001; j++)//遍历i节点的所有嵌套的j
if(graph[i][j]){//如果i嵌套j
int dpRes = dp(j) + 1;
ans = ans > dpRes ? ans : dpRes;
}
return ans;
}
int main(void)
{
int n;
scanf("%d",&n);
while(n--){
scanf("%d",&num);
for(int i = 0; i < num; i++){
scanf("%d%d",&nodes[i].x,&nodes[i].y);
}
for(int i = 0; i < num; i++){
for(int j = 0; j < num; j++){
if((nodes[i].x > nodes[j].x && nodes[i].y > nodes[j].y)
|| (nodes[i].y > nodes[j].x && nodes[i].x > nodes[j].y))//判断i是否嵌套j
graph[i][j] = 1;//若嵌套,则置1
}
}
int temp,result = -1;
for(int i = 0; i < num; i++){//遍历每个节点,找到最大的d(i)
temp = dp(i);
if(temp > result)
result = temp;
}
printf("%d\n",result);
memset(graph, 0, 1001 * 1001 * sizeof(int));
memset(d, 0, 1001 * sizeof(int));
memset(nodes, 0, sizeof(struct node) * 1001);
}
}