前言
可能小组的同学很早就听说过大小端,但是似乎这个顺序并没有什么卵用。。(我就是这么想的)不过在学习网络编程中,突然对这个问题有了新的认识,赶紧总结下,不然以后肯定踩坑。。。
本文假定读者已经明白了大小端的区别,并且对于网络编程、TCP/IP有一定了解。
正文
主机字节序与网络字节序的转换
网络字节序都是大端,但是我们用的机器多数都是小端(Intel处理器),所以在传送数据时,我们需要转换字节序,同时,我们也应知道,在不同进程间通信时常常需要考虑这个字节序,如C编写的进程和Java编写的进程间通信,(JVM也是大端)。在主机和网络字节序的互相转化主要涉及IP地址和端口。
#include <netstat/in.h>
unsigned long int htonl(unsigned long int hostlong);
unsigned short int htons(unsigned short int hostshort);
unsigned long int ntohl(unsigned long int netlong);
unsigned short int ntohs(unsigned short int netshort);这四个函数非常明确 htonl 就是host to network long,htons 就是host to network short,下面两个同理,你一定知道意思,参数和返回值类型相同,long对应32bit的IP地址,short对应16bit的port。
深入理解传输时的字节序
在编写网络程序时,任何格式化的数据在传输时都应考虑字节序。
在总结时,我忽然想到,在之前写聊天室时。我在将其结构体里面的int类型数据直接发送,并没有转换顺序,这样不是应该出现错误吗?因为我的机器是小端,而网络字节序是大端呀?
对于网络字节序,我的理解其实是一种规定。
让我们通过一个例子说明。
我们在发送时,发送了一块数据,是一个结构体。
结构体如下:
struct Test{
int flag;
char str[10];
};
struct Test a;
a.flag = 4096; // 未转换字节序
strcpy(a.str,"hello");这时,如果在对端按照结构体的形式,接受数据,结果完全正确。可以顺利读出flag为4096.
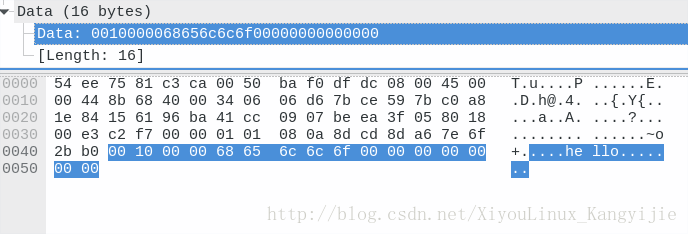
通过抓包,我们可以看到,flag就是按照小端存储的,并没有被转换。
而在前面调用htons系列函数的作用呢?
作用在于转换了IP地址的字节序。
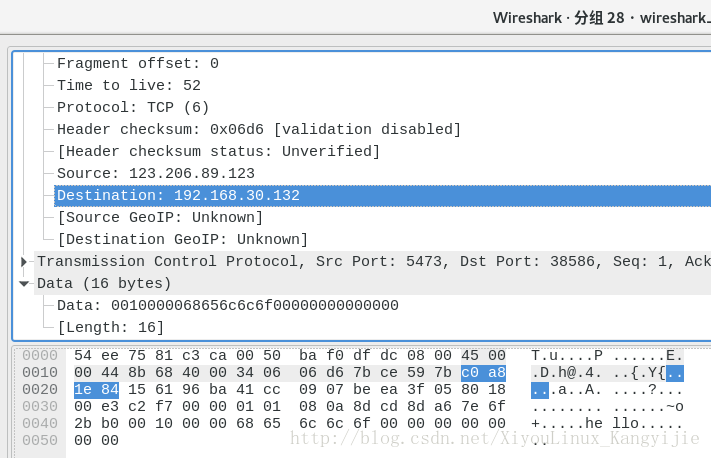
(可以看到IP中的30也就是0x1e 按照大端被放在了高地址(偏移大)的位置)
端口也是同理的。
回到开头我对字节序理解,网络字节序是一种规定,它规定了传输的数据应该按照大端,因为通信双方的字节序其实是不确定的,但是按照规定我们都认为接收到的数据都是大端,即遵守规定的顺序,这样老老实实地通过htons系列函数处理格式化的数据(如int)保证了不会出现任何错误。
但是,我们自己写的C/S因为都是小端,所以即使没有遵守规定,依然可以用,但这样并不规范,有潜在的隐患。
而对于IP地址或者端口,因为这些数据的处理全部是在应用层以下,是路由器,网卡进行处理,它们在设计时自然遵守规定全部依照网络字节序对数据进行处理,而你自己不把IP地址转换顺序,交给下层处理时自然会出错。
所以,在应用层,也应该遵守规定,对于int double 这样的数据也应该转换字节序,当然字符串也挺好(这大概也就是Json的优势了,而像protobuf这种传输时就要注意顺序)。