1.protobuf是干什么的
protobuf为google公司出品,其全称为Protocol Buffers。关于其是什么网上一搜一大堆,但是初学者往往还是看的晕头转向。其实简单的概括protobuf的功能无非就是对结构化数据串行化。举个简单的小例子
struct Person
{
int number; //编号
char name[100]; //姓名
char hobby[1000]; //爱好
};上面我定义了一个简单的用于描述一个人的Person结构体,假定每个人都有一个编号(类似身份证号),我将其定义为int型就姑且认为够用吧。其次是name,好多人奇怪为什么我要给name定义100字节,个人感觉小日本的名字好长所以怕不够用(哈哈)。接着是hobby字段,由于我不能确定每个人到底有多少爱好,也是怕不够存所以就给了1000。
好了数据定义完了现在服务器有100000个人的Person结构体(person[100000])需要保存到磁盘里你会咋么做?
如果你是一个不懂序列化的新手我想你大概会这样做
for(int i = 0; i < 100000; i++)
{
......
fwrite(&person[i],sizeof(struct Person),1,fp);
......
}这么从正确性的角度来说的确没什么问题,但是试想如果大多数人的名字所占字节都不超过10个字节,爱好都不超过50字节,那么你每次往文件里写sizeof(struct Person)字节的大小岂不太浪费了?这只是往文件里写一个结构体,如果我把该问题换成让你和另一台计算机通过网络传输哪100000个结构体呢,这不仅会让你的传输效率较低,还会使网络无端的遭受很大的流量。。。
那么我们该如何避免这种浪费呢?很简单只需要将该结构体通过某种机制串行化(序列化),以此来减少之前那大量的’\0’。现在你应该理解序列化是什么了吧?
2.测试序列化之后的结果
定义message如下
message.proto
message Test
{
required int32 num=1;
required string str1=2;
required string str2=3;
required string str3=4;
}如上所示我定义了包含一个整形num,和三个字符串str的message。
测试代码如下
#include<iostream>
#include<vector>
#include<string>
#include"message.pb.h"
#include<stdio.h>
//打印出数字的二进制
void print_bin(int n)
{
int l = sizeof(n)*8;//总位数。
int i;
if(n == 0)
{
printf("0");
return;
}
for(i = l-1; i >= 0; i --)//略去高位0.
{
if(n&(1<<i)) break;
}
for(;i>=0; i --)
printf("%d", (n&(1<<i)) != 0);
printf("\n");
}
int main(int argc,char **argv)
{
Test message;
//设置message中的内容
message.set_num(1024);
message.set_str1("h");
message.set_str2("e");
message.set_str3("l");
char buf[200];
uint8_t *start = reinterpret_cast<uint8_t *>(buf);
//从start处开始序列化
uint8_t *end = message.SerializeWithCachedSizesToArray(start);
//以二进制的形式输出从start开始的每个字节的内容
for(; start != end; start++)
{
print_bin(*start);
}
return 0;
}程序输出结果如下
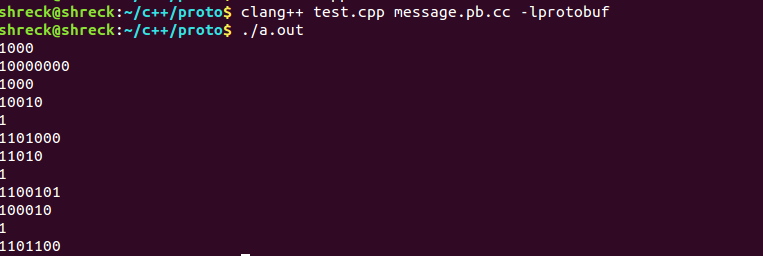
为其中的每个字节字段补0后的结果如下
1. 00001000
2. 10000000
3. 00001000
4. 00010010
5. 00000001
6. 01101000
7. 00011010
8. 00000001
9. 01100101
10. 00100010
11. 00000001
12. 01101100
程序输出的结果为每个字节前面补齐0之后如上面列出的一样
好了开始解释每一个字节的含义
1.1号字节代表num在Test这个message中的序号
2.2号字节和3号这个字节共同表示了1024这个整数的二进制,protobuf序列化整形采用 Base 128 Varints编码,该编码主要逻辑为每个字节的最高位设为1表示其后面还有字节出现。也就是说一个字节只会有7位用来表示整数的值了,在本例中1024为2的10次方,显然一个字节是保存不下其值的故2号字节的最高位被设为1,表示其后还有字节用来共同保存该整数,在看3号字节最高位为0表示其后没有更多字节用来保存该整数了,所以我们可以得出2,3号字节共同表示了1024的二进制形式,我们把2,3号字节的最高位(标记位)去掉后变为 0000000 0001000 聪明的你把这俩一合并为 00000000001000发现这哪里是1024这不是8么?为什么会这样,主要原因是我的计算机为小端,而序列化后的字节序为大段(关于大小段请读者自行百度)所以我们只需对这俩个字节做个调换即可 调换结果为0001000 0000000现在是1024了
4.4号字节表示str1在message中的序号
5.5号表示str1字符串的长度为1
6.6号表示h这个字符的ascii码的二进制
7.7号表示str2在message中的序号
8.8号表示str2字符串的长度为1
9.9号表示e这个字符的ascii码的二进制
如果读者理解以上所述内容,那么请自行推出下面的内容
3.感悟
通过上面对protobuf协议序列化后二进制内容的详细叙述可以推出protobuf的一些优缺点
优点
(1)序列化的速度较快,因为它序列化的过程相对简单一些
(2)字段可以乱序,其每个字段都有编号,故乱序也会重排的
(3)对一些小整数进行了空间压缩
缺点
(1)字段过多时会影响反序列化的速度,因为解析每一块数据都要根据序号找到对应的位置然后在插入到以解析好的数据中
(2)基于128bits存储,数据较大时效率会很受影响,需找到所有块的低7位
protobuf的详细介绍请戳这里https://www.ibm.com/developerworks/cn/linux/l-cn-gpb/