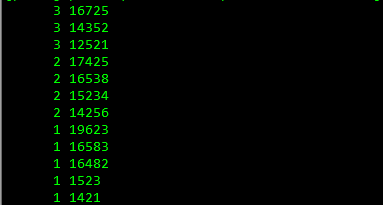
文件中保存的是好多行采集的数据,统计出现次数最多的前n个数据。
sort排序后相同的数据会连续出现此时再使用uniq进行去重,-c的含义是添加一行出现次数的数据。
awk '{print $1}' data_file | sort | uniq -c | sort -r -k1 > data_sort文件里的数据:
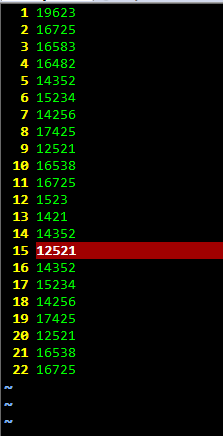
执行命令后:
文件中保存的是好多行采集的数据,统计出现次数最多的前n个数据。
sort排序后相同的数据会连续出现此时再使用uniq进行去重,-c的含义是添加一行出现次数的数据。
awk '{print $1}' data_file | sort | uniq -c | sort -r -k1 > data_sort文件里的数据:
执行命令后: