众所周知,面向对象程序设计思想有三大基本特性:
封装,继承,多态。

-
封装
封装最好理解。封装是面向对象的特征之一,是对象和类概念的主要特性。
封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。 -
继承
面向对象编程 (OOP) 语言的一个主要功能就是“继承”。继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。 -
多态
所谓多态就是指一个类实例的相同方法在不同情形有不同表现形式。多态机制使具有不同内部结构的对象可以共享相同的外部接口。这意味着,虽然针对不同对象的具体操作不同,但通过一个公共的类,它们(那些操作)可以通过相同的方式予以调用。
类与类之间都有什么关系?
主要有三种: 复合,委托,继承
复合(has-a的关系):

构造由内而外,析构由外而内。
委托:

继承(is-a的关系):

继承+虚函数(从函数的调用权理解)
虚函数的分类:
- non-virtual:不希望子类重新定义该函数
- virtual:希望子类重新定义该函数,已有默认定义
- pure virtual:希望子类一定要重新定义该函数,没有默认定义(java中的抽象类,无法实例化)
class Shape
{
virtual drow() const = 0; //纯虚函数
virtual printError(); //虚函数
int fun(); //普通函数
};

注意看:myDoc.Onfileopen->CDocument::onffileopen()
seriailze() -> this->seriailze()而在他的类中是有定义该函数的
虚函数的实现机制:
虚函数表
在这个表中,主要是一个类的虚函数的地址表(所以就是只要类中有virtual函数,就会有一张虚函数表),这张表解决了继承、覆盖的问题,保证其能真实反应实际的函数。(一个类的虚函数表是静态 static 的,也就是说对这个类的每个实例,他的虚函数表的是固定的,不会为每个实例生成一个相应的虚函数表。只会在每个示例中添加一个指向虚函数表的指针),所以,当我们用父类的指针来操作一个子类实例的时候,这张虚函数表就显得由为重要了,它就像一个地图一样,指明了实际所应该调用的函数。
这里我们着重看一下这张虚函数表。C++的编译器保证虚函数表的指针存在于对象实例中最前面的位置(这是为了保证取到虚函数表的有最高的性能——如果有多层继承或是多重继承的情况下)。 这意味着我们通过对象实例的地址可以得到这张虚函数表,然后就可以遍历其中函数指针,并调用相应的函数。
class Base
{
public:
virtual void f() { cout << "Base::f" << endl; }
virtual void g() { cout << "Base::g" << endl; }
virtual void h() { cout << "Base::h" << endl; }
};
所以用图来表示就是这样子:
 注意:在上面这个图中,虚函数表的最后多加了一个结点,这是虚函数表的结束结点,就像字符串的结束符“/0”一样,其标志了
注意:在上面这个图中,虚函数表的最后多加了一个结点,这是虚函数表的结束结点,就像字符串的结束符“/0”一样,其标志了虚函数表的结束。这个结束标志的值在不同的编译器下是不同的。
-
在WinXP+VS2003下,这个值是NULL。
-
而在Ubuntu 7.10 + Linux 2.6.22 + GCC 4.1.3下,这个值是如果1,表示还有下一个虚函数表,如果值是0,表示是最后一个虚函数表。
接下来,通过对于各种继承的情况来学习一下虚函数实现的本质。
一般继承(无虚函数覆盖)
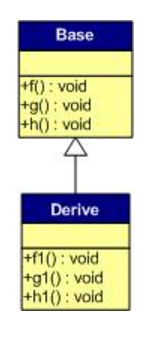
在这个继承关系中,子类没有重写任何父类的函数。那么,在子类实例的虚函数表如下所示:

我们可以看到下面几点:
-
虚函数按照其声明顺序放于表中。
-
父类的虚函数在子类的虚函数前面。( 父 —>> 子)
一般继承(有虚函数覆盖)
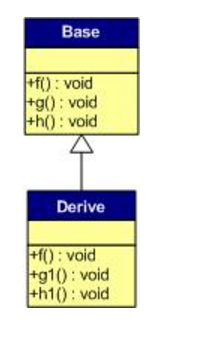
在这个类的设计中,只覆盖了父类的一个函数:f()。那么,对于派生类的实例的虚函数表会是下面的样子:

-
覆盖的f()函数被放到子类虚函数表中原来父类虚函数的位置。
-
没有被覆盖的函数依旧。
这样,我们就可以看到对于下面这样的程序,
Base *b = new Derive();
b->f();
由b所指的内存中的虚函数表(子类的虚函数表)的f()的位置已经被Derive::f()函数地址所取代,于是在实际调用发生时,是Derive::f()被调用了。这就实现了多态。
多重继承(无虚函数覆盖)

对于子类实例中的虚函数表,是下面这个样子:

我们可以看到:
- 每个父类都有自己的虚表。
- 子类的成员函数被放到了第一个父类的表中。(所谓的第一个父类是按照声明顺序来判断的)
这样做就是为了解决不同的父类类型的指针指向同一个子类实例,而能够调用到实际的函数。
多重继承(有虚函数覆盖)


我们可以看见,三个父类虚函数表中的f()的位置被替换成了子类的函数指针。
Derive d;
Base1 *b1 = &d;
Base2 *b2 = &d;
Base3 *b3 = &d;
b1->f(); //Derive::f()
b2->f(); //Derive::f()
b3->f(); //Derive::f()
b1->g(); //Base1::g()
b2->g(); //Base2::g()
b3->g(); //Base3::g()
关于继承 Effective C++ 中需要遵守的规则:
确定 public 继承一定能够塑造出 is-a 的关系。适用于base class身上的每一件事情一定也适用于derived class 身上。因为每一个derived class 就是一个 base class 对象。- 绝不重新定义继承而来的非虚(non-virtual)函数。理所当然。
- 绝不重新定义继承而来的缺省参数值。
- 明智而谨慎的使用private,多重继承。
解释:绝不重新定义继承而来的缺省参数值和非虚(non-virtual)函数
主要原因:静态绑定与动态绑定
先来看一个发生的案例:
class A
{
public:
virtual void func(int val = 0)
{
cout << "A-> val== " << val << endl;
}
virtual void test()
{
func();
}
};
//A的虚表是:A::func A::test
class B : public A
{
public:
virtual void func(int val = 666)
{
cout << "B-> val== " << val << endl;
}
};
//A的虚表是:B::func A::test
int main()
{
B *p = new B;
p->test();
}

p->test()执行过程理解:
(1) 由于B类中没有覆盖(重写)基类中的虚函数test(),因此会调用基类A中的test();
(2) A中test()函数中继续调用虚函数 fun(),因为虚函数执行动态绑定,p此时的动态类型(即目前所指对象的类型)为B*,因此此时调用虚函数fun()时,执行的是B类中的fun();所以先输出“B->”;
(3) 缺省参数值是静态绑定,即此时val的值使用的是基类A中的缺省参数值,其值在编译阶段已经绑定,值为0,所以输出“0”;
最终输出“B->0”。所以大家还是记住上述结论:绝不重新定义继承而来的缺省参数值!
绝不定义重新定义继承而来的非虚(non-virtual)函数也是这个原因。因为non-virtual是静态绑定的,在编译器编译阶段就已经定型了,而virtual 是动态绑定的。在具体执行调用时,才进行把函数调用与响应调用所需要的代码相结合的动作。
更多设计与规划见:Effective C++
C++11新特性
语言方面
1.初始化列表,explicit(显式构造),范围 for 循环,=default,=delete,nonexcept,decltype,override,final ,auto关键字,nullptr,模板别名(alias template),Static assertion(编译时期的断言)
2.lambda 表达式
[capture list] (parameter list) ->return type { function body }
外部变量
[=] 传值
[&] 传引用
匿名函数,相当于一个匿名函数对象。
class Test
{
public:
Test(int tt) : i(tt), j(0) {}
int i;
int j;
};
int main()
{
sort(vv.begin(), vv.end(), [](const Test &lhs, const Test &rhs) {
return lhs.i < rhs.i;
});
for (auto i : vv)
cout << " i== " << i.i << " j == " << i.j << endl;
return 0;
}
3.智能指针
4.可变参数模板
//要有一个拆解包输出的终点函数调用
void print()
{
cout << "OKOKOKOK " << endl;
}
template <typename T, typename... Types>
void print(const T &fristArg, const Types &... args) //就是规定的这种写法
{
cout << "1+n-1" << endl;
cout << fristArg << endl;
print(args...);
}
template <typename... Types>
void print(const Types &... args)
{
cout << "nnnnnnn" << endl;
//cout << fristArg << endl;
print(args...);
}
int main()
{
print(7.5, bitset<16>(377), 42);
}

5.左值,右值,右值引用,std::move ,深浅拷贝,std::forward(完美转发)
- 左值 (lvalue, locator value) 表示了
一个占据内存中某个可识别的位置(也就是一个地址)的对象。(可变的变量,能够 取地址& ,非临时对象) - 右值 (rvalue) 则使用排除法来定义。一个表达式不是 左值 就是 右值 。 那么,
右值是一个 不 表示内存中某个可识别位置的对象的表达式。(临时对象)
举例:

在 C++11 之前右值是不能够被修改的,但是之后在一些特殊的情况下,右值被变得可修改,既然可以被修改,那么就会有引用存在,就存在右值的引用。
右值引用是用来支持转移语义的。转移语义(steal)可以将资源 ( 堆,系统对象等 ) 从一个对象转移到另一个对象,这样能够减少不必要的临时对象的创建、拷贝以及销毁,能够大幅度提高 C++ 应用程序的性能。临时对象的维护 ( 创建和销毁 ) 对性能有严重影响。
std::move 就是将一个左值转为右值。需要注意的就是转右值后,原来的对象是一定不能够被是使用了!!!
template<typename T>
decltype(auto) move(T&& param)
{
using ReturnType = remove_reference_t<T>&&;
return static_cast<ReturnType>(param); //四种类型转换要清楚
}
- std::forward ()
#include <thread>
#include <condition_variable>
#include <mutex>
#include <iostream>
using namespace std;
void Process(int &i)
{
cout << "Process(int &i) " << i << endl;
}
void Process(int &&i)
{
cout << "Process(int &&i) " << i << endl;
}
void Forward(int &&i)
{
cout << "Forward(int &&i) " << i << endl;
Process(i);
}
int main(void)
{
int a = 0;
Process(1); //右值
Process(std::move(a)); //右值
Forward(2);//右值(这个会完美的转发到Process(右值)吗??????)
Forward(std::move(a));
//Forward(a);
return 0;
}

根据运行结果,可见这个玩意儿真的不能够将右值完美转发。So,std::forward就有用了。
void Forward(int &&i)
{
cout << "Forward(int &&i) " << i << endl;
Process(std::forward<int&&>(i));
}
标准库方面
1.线程库std::thread
- 两线程交打印奇偶数。使用 std::thread
#include <thread>
#include <condition_variable>
#include <mutex>
#include <iostream>
using namespace std;
std::mutex mtx;
std::condition_variable cond;
bool tag = true; //需要等待的条件
//打印偶数
void printOdd()
{
for (int i = 2; i < 10; i += 2)
{
unique_lock<std::mutex> ulock(mtx);
//条件变量是一种全局的变量,需要用锁来保护
cond.wait(ulock, []() { return !tag; });
// 等待后,当前线程 占有锁
//如果当前线程被阻塞,cond.wait 操作会自动解锁使得其他线程得以运行
cout << "我是偶函数" << endl;
cout << i << endl;
tag = true;
// 通知前完成手动解锁,以避免等待线程才被唤醒就阻塞(细节见 notify_one )
ulock.unlock();
cond.notify_one();
}
}
//打印奇数
void printEven()
{
for (int i = 1; i < 10; i += 2)
{
unique_lock<std::mutex> ulock(mtx);
cond.wait(ulock, []() { return tag; });
cout << "我是奇函数" << endl;
cout << i << endl;
tag = false;
ulock.unlock();
cond.notify_one();
}
}
int main(void)
{
std::thread th1(printEven);
std::thread th2(printOdd);
th1.join();
th2.join();
return 0;
}

- 线程池的实现见:
2.std::function,std::bind 等等
3.正则表达式库,字符串类字新增与其他类型互换的方法,如to_string(),stoi(),stol等,基于hash表的无序关联容器(unordered_map以及unordered_set),array,tuple,forward_list等等。
其他面试考点总结
1.static与const 的区别
static关键字至少有下列n个作用:
- static 变量(全局变量)存在于静态存储区,随进程的消亡而消亡。
- 在类中的static成员变量,函数属于整个类所拥有,对类的所有对象只有一份拷贝,但函数不接收this指针,因而只能访问类的static成员变量。
- 限定访问权限。(限定在当前文件下,防止命名污染)
const关键字至少有下列n个作用:
- 用来定义常量。
- 保护。欲阻止一个变量被改变,可以使用const关键字。在定义该const变量时,通常需要对它进行初始化,因为以后就没有机会再去改变它了;
- 限定指针规则。
- 从汇编角度理解,只有一份拷贝。节省内存(#define 只是简单替换,多分拷贝)
限定指针规则: 记法:左定值,右定向。
解释:
const 在(*变量)的左边,即:const int *p .就不能通过(*p)来改变它的值。
const 在(*变量)的右边,即: int *const p .就不能改变指针的指向。