文章目录
我们不科普,直接从缓存开始哦!!!

最小的缓存:CPU 寄存器
先解释一下高速缓存行,组,块的区别:
- 行:行要比块要大,因为行中有
有效位和标记位+块(通常行和块互换使用) - 组:是一个或者多个行
- 块:是一个固定大小的信息包,在高速缓存和主存之间来回传送。
缓存概述

块一般是越靠近CPU越小,可能就会以字节为单位进行复制拷贝,越靠近底层越大
缓存不命中
就是要用k+1的数据,但是在k层没有找到,所以就需要拷过来,如果k层满了就需要置换,就会用到LRU算法等等…
缓存不命中的几种情况:
- 冷缓存:k 层为空(冷不命中,不会在缓存暖身稳定之后出现)
- 冲突不命中:映射到同一个缓存块,你来我往的使用
- 容量不命中:就是 k 层放不下
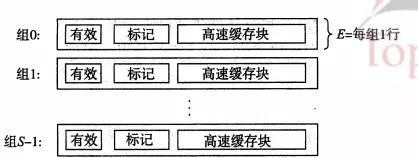
缓存通用组织结构
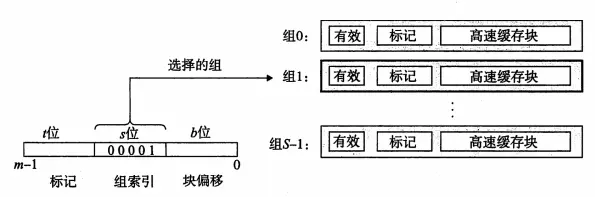
存储器的地址有m位,就会形成2^m个不同的地址.

高速缓存是一个数组,每个组包含一个或多个行,每个行有一个有效位、一个标记位,以及数据块。我们进行访问的地址结构就是:t的个标记位+s个组索引+b个块偏移;
高速缓存的大小就是:C=S*E*B
cpu -> 从主存读取地址A->将A发送到高速缓存->那么如何在高速缓存中知道它包含地址A的数据的副本呐?
参数S和B将m个地址分为三个字段,如上图:
- s个组索引位:告诉我们这个字存储在哪个组中.
- t个标记位:告诉我们在这个组的哪一行(前提:设置了有效位 && 该行的标记位与要找的标记位相同时)
- b个块偏移:告诉我们在B个字节的数据块中的偏移位置

去查缓存的时候是已经查过了内存页表,将虚拟地址转换为了物理地址,也就是说是拿物理地址去找缓存的
缓存组织结构分类
1.直接映射高速缓存(就是每个组只有一行缓存行)
假如不命中,缓存向主存请求副本,cpu等待,当缓存将其放到一个高速缓存行里时,缓存将从存储的块中抽取出对应的数据,返还给cpu.高速缓存确定一个请求是否命中,然后抽出请求字的过程分三步:
- 组选择:很好理解,就是地址位中的组索引匹配高速缓存中的组
- 行匹配和字抽取

行匹配主要是对有效位进行匹配,和标记位与高速缓存中的标记位一致,这就是一个命中。最后的字抽取就简单了,只是看地址后面的偏移值。
100 表示是从块中的字节4开始的,w0表示一个字的地位字节,依次类推,w3表示高位.
为什么使用中间的位来做索引?而不是高位?(没看懂!!哭哭)
其实很简单,就和 slab 要改造成 slub 一样,我们读知道,地位变好多下,高位变一下,如果用高位就会造成一些连续的内存块对应到相同的高速缓存块,如果连续的访问一个数组,也就会访问连续的内存块,如果这样对应,就会
组相连高速缓存(每组多于1行的高速缓存行)
这里就是将有效位+标记位看成key,缓存块看成value
全相连高速缓存(只有一个组):只适合小规模的高速缓存(翻译备用缓冲器(虚拟内存中的TLB:缓存页表项))
希望有时间讲到内存管理时,再提!!!!

不命中之后的替换策略(LFU,LRU)得知道
缓存修改之后,如何写到底层?
- 1.很好想到,只要修改就直接写到底层(称之为直写),但是考虑一个问题,如果一直在改变呐?
- 2.写回:其实就是如果该缓存行需要被替换的时候往底层写入.(类似 hash 的一点一点的搬移过程),但是这样就会必须在缓存行维护一个修改位,以标志是否修改过
OK,这样虽然复杂,但是可行性还是有的,一般也就用的是这个!!!但是我们如何解决写的不命中问题呐?
- 1.写分配:从底层加载上来,然后更新缓存块.
- 2.非写分配:直接往底层写
小总结:
- 直写与非写分配搭配
- 写回与写分配搭配
一般用的就是写回与写分配
真实的缓存结构:

可以看出这是一个UMA模式
- i-cache:只保存指令
- d_cache:只保存程序数据
- 通用 cache
独立起来就能够同时读取一条指令和一个数据字了啊
Core i7的架构中我们可以看出,L1分为数据和指令高速缓存,共享L2高速缓存,同时每个核共享L3高速缓存
最后编写代码的建议:
-
一旦从一个存储器中读了一个数据出来,就尽可能多的利用他(kij版本)。因为编译器能将它们缓存在寄存器文件中;
-
步长为1的引用模式是最好的;
-
多维数组的访问,注意使用行优先模式。
-
将你的注意力集中在内循环上,大部分计算的存储器访问都集中在这里;
UMA 与NUMA:
