文章目录
以下论述,皆以32位机器举例子.64位道理相同,类比即可
内存管理有两种状态的管理方式,分别是内核态和用户态.用户态比较随意一点,而内核态就必须严格把控内存(不这样,系统就会崩溃啊,不是吗?)
页
学过计算机的都知道,OS是通过 基本单位-页 来管理内存的,那么具体主要有什么呐?
struct page {
page_flags_t flags; 页标志符
atomic_t _count; 页引用计数
atomic_t _mapcount; 页映射计数
unsigned long private; 私有数据指针
struct address_space *mapping; 该页所在地址空间描述结构指针,用于内容为文件的页帧
pgoff_t index; 该页描述结构在地址空间radix树page_tree中的对象索引号即页号
struct list_head lru; 最近最久未使用struct slab结构指针链表头变量
void *virtual; 页虚拟地址
};
- flags:页标志包含是不是脏的,是否被锁定等等,每一位单独表示一种状态,可同时表示出32种不同状态,定义在<linux/page-flags.h>
- _count:计数值为-1表示未被使用。
- virtual:页在虚拟内存中的地址,对于不能永久映射到内核空间的内存(比如高端内存),该值为NULL;需要事必须动态映射这些内存。
内核用struct page结构体表示每个物理页,假定struct page结构体占40个字节,系统物理页大小为4KB,对于4GB物理内存,1M个页面,故所有的页面page结构体共占有内存大小为40MB,相对系统4G,这个代价并不高。
需要注意的是:page结构体描述的是物理页而非逻辑页,描述的是内存页的信息而不是页中数据。,其实就和i-node 对象一样
区
在X86架构中,Linux虚拟地址空间划分为0~3G为用户空间,3~4G为内核空间(为什么这样?为了减少系统调用的成本,通过系统调用的方式直接去3~4G的表中去查找内核态的页表(所有程序都一样的)就行了,而不用去切换到内核然后再去查页表,执行系统调用,所以这也就解释了为什么现代操作系统执行系统调用的时候几乎不用切换到内核态了)
内核空间的内存中所有的页分为三类,分别放在三个区
| 区 | 描述 | 物理内存(MB) |
|---|---|---|
| ZONE_DMA | DMA使用的页 | <16 |
| ZONE_NORMAL | 可正常寻址的页 | 16 ~896 |
| ZONE_HIGHMEM | 动态映射的页 | >896 |
由于内核的虚拟和物理地址只差一个偏移量:物理地址 = 逻辑地址 – 0xC0000000,其实这就是说内核的对应是一对一的对应.所以如果1G内核空间完全用来线性映射,显然物理内存也只能访问到1G区间,这显然是不合理的。HIGHMEM就是为了解决这个问题,专门开辟的一块不必线性映,可以灵活定制映射的区域,以便访问1G以上物理内存的区域。从网上扣来一图

具体对应struct zone 结构
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long watermark[NR_WMARK];
unsigned long nr_reserved_highatomic;
/*
* We don't know if the memory that we're going to allocate will be
* freeable or/and it will be released eventually, so to avoid totally
* wasting several GB of ram we must reserve some of the lower zone
* memory (otherwise we risk to run OOM on the lower zones despite
* there being tons of freeable ram on the higher zones). This array is
* recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl
* changes.
*/
long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
int node;
#endif
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset;
#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn;
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
#ifdef CONFIG_MEMORY_ISOLATION
/*
* Number of isolated pageblock. It is used to solve incorrect
* freepage counting problem due to racy retrieving migratetype
* of pageblock. Protected by zone->lock.
*/
unsigned long nr_isolate_pageblock;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
seqlock_t span_seqlock;
#endif
int initialized;
/* Write-intensive fields used from the page allocator */
ZONE_PADDING(_pad1_)
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
...
}
需要注意的是:并不是所有的体系结构都定义了全部区,有些64位的体系结构,比如Intel的x86-64体系结构可以映射和处理64位的内存空间,所以其没有ZONE_HIGHMEM区。而有些体系结构中的所有地址都可用于DMA,所以这些体系结构就没有ZONE_DMA区。
内存页分配接口
页的分配

先来看alloc_pages(gfp_mask, order) 函数
...
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,
unsigned int order)
{
if (nid == NUMA_NO_NODE)
nid = numa_mem_id();
return __alloc_pages_node(nid, gfp_mask, order);
}
#ifdef CONFIG_NUMA
extern struct page *alloc_pages_current(gfp_t gfp_mask, unsigned order);
static inline struct page *
alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_current(gfp_mask, order);
}
extern struct page *alloc_pages_vma(gfp_t gfp_mask, int order,
struct vm_area_struct *vma, unsigned long addr,
int node, bool hugepage);
#define alloc_hugepage_vma(gfp_mask, vma, addr, order) \
alloc_pages_vma(gfp_mask, order, vma, addr, numa_node_id(), true)
#else
#define alloc_pages(gfp_mask, order) \
...
再来看__get_free_pages(gfp_t gfp_mask, unsigned int order) 函数
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
//使用了上一个函数
page = alloc_pages(gfp_mask & ~__GFP_HIGHMEM, order);
if (!page)
return 0;
// 使用 page_address,转为了虚拟地址
return (unsigned long) page_address(page);
}
最后来看get_zeroed_page(gfp_mask) 函数
我们在使用这些接口获取页的时会面对一个问题,我们获得的这些页若是给用户态用,虽然这些页中的数据都是随机产生的垃圾数据,不过,虽然概率很低,但是也有可能会包含某些敏感信息。所以,更谨慎些,我们可以将获得的页都填充为0。这会用到get_zeroed_page函数
unsigned long get_zeroed_page(gfp_t gfp_mask)
{
//可以看到,这里只是加了一种 __GFP_ZERO的gfp_mask方式,其余的都一样
return __get_free_pages(gfp_mask | __GFP_ZERO, 0);
}
页的释放
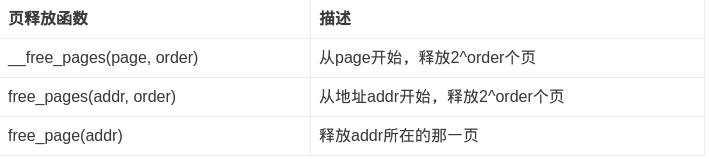
内存字节分配接口
前面讲的那些接口都是以页为单位进行内存分配与释放的。而在实际中内核需要的内存不一定是整个页,可能只是以字节为单位的一片区域。下面两个函数就是实现这样的目的。
kmalloc
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size)) {
#ifndef CONFIG_SLOB
unsigned int index;
#endif
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags);
#ifndef CONFIG_SLOB
index = kmalloc_index(size);
if (!index)
return ZERO_SIZE_PTR;
return kmem_cache_alloc_trace(
kmalloc_caches[kmalloc_type(flags)][index],
flags, size);
#endif
}
return __kmalloc(size, flags);
}
// kmalloc -> __kmalloc -> __do_kmalloc -> ....
static __always_inline void *__do_kmalloc(size_t size, gfp_t flags,
unsigned long caller)
{
struct kmem_cache *cachep;
void *ret;
if (unlikely(size > KMALLOC_MAX_CACHE_SIZE))
return NULL;
cachep = kmalloc_slab(size, flags);
if (unlikely(ZERO_OR_NULL_PTR(cachep)))
return cachep;
ret = slab_alloc(cachep, flags, caller);
kasan_kmalloc(cachep, ret, size, flags);
trace_kmalloc(caller, ret,
size, cachep->size, flags);
return ret;
}
kmalloc() 函数返回的是一个指向内存块的指针,其内存块大小至少为size,所分配的内存在物理内存中连续且保持原有的数据(不清零)
其中部分flags取值说明:
- GFP_USER: 用于用户空间的分配内存,可能休眠;
- GFP_KERNEL:用于内核空间的内存分配,可能休眠;
- GFP_ATOMIC:用于原子性的内存分配,不会休眠;典型原子性场景有中断处理程序,软中断,tasklet等
kmalloc内存分配最终总是调用__get_free_pages 来进行实际的分配,故前缀都是GFP_开头。
kmalloc分最多只能分配32个page大小的内存,每个page=4k,也就是128K大小,其中16个字节用来记录页描述结构。kmalloc分配的是常驻内存,不会被交换到文件中。最小分配单位是32或64字节。
kzalloc 函数等于分配并置零
static inline void *kzalloc(size_t size, gfp_t flags)
{
return kmalloc(size, flags | __GFP_ZERO);
}
vmalloc
void *vmalloc(unsigned long size)
{
return __vmalloc_node_flags(size, NUMA_NO_NODE,
GFP_KERNEL);
}
static inline void *__vmalloc_node_flags(unsigned long size,
int node, gfp_t flags)
{
return __vmalloc_node(size, 1, flags, PAGE_KERNEL,
node, __builtin_return_address(0));
}
static void *__vmalloc_node(unsigned long size, unsigned long align,
gfp_t gfp_mask, pgprot_t prot,
int node, const void *caller)
{
return __vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END,
gfp_mask, prot, 0, node, caller);
}
void *__vmalloc_node_range(unsigned long size, unsigned long align,
unsigned long start, unsigned long end, gfp_t gfp_mask,
pgprot_t prot, unsigned long vm_flags, int node,
const void *caller)
{
struct vm_struct *area; //vm_struct 虚拟内存结构
void *addr;
unsigned long real_size = size;
size = PAGE_ALIGN(size);
if (!size || (size >> PAGE_SHIFT) > totalram_pages)
goto fail;
area = __get_vm_area_node(size, align, VM_ALLOC | VM_UNINITIALIZED |
vm_flags, start, end, node, gfp_mask, caller);
if (!area)
goto fail;
addr = __vmalloc_area_node(area, gfp_mask, prot, node);
if (!addr)
return NULL;
/*
* In this function, newly allocated vm_struct has VM_UNINITIALIZED
* flag. It means that vm_struct is not fully initialized.
* Now, it is fully initialized, so remove this flag here.
*/
clear_vm_uninitialized_flag(area);
kmemleak_vmalloc(area, size, gfp_mask);
return addr;
fail:
warn_alloc(gfp_mask, NULL,
"vmalloc: allocation failure: %lu bytes", real_size);
return NULL;
}
该函数返回的是一个指向内存块的指针,其内存块大小至少为size,所分配的内存是逻辑上连续的。
不同之处在于,kmalloc分配的是虚拟地址连续,物理地址也连续的一片区域,vmalloc分配的是虚拟地址连续,物理地址不一定连续的一片区域。

管理page的算法-Buddy
由来:

假设这是一段连续的页框,阴影部分表示已经被使用的页框,现在需要申请一个连续的5个页框。这个时候,在这段内存上不能找到连续的5个空闲的页框,就会去另一段内存上去寻找5个连续的页框,这样子,久而久之就形成了页框的浪费。
Buddy 算法是什么?
为了避免出现这种情况,Linux内核中引入了伙伴系统算法(Buddy system)。把所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续页框的页框块。最大可以申请1024个连续页框,对应4MB大小的连续内存。如图:

假设要申请一个256个页框的块,先从256个页框的链表中查找空闲块,如果没有,就去512个页框的链表中找,找到了则将页框块分为2个256个页框的块,一个分配给应用,另外一个移到256个页框的链表中。如果512个页框的链表中仍没有空闲块,继续向1024个页框的链表查找,如果仍然没有,则返回错误。页框块在释放时,会主动将两个连续的页框块合并为一个较大的页框块。
从上面可以知道Buddy算法一直在对页框做拆开合并拆开合并的动作。Buddy算法牛逼就牛逼在运用了世界上任何正整数都可以由2^n的和组成。这也是Buddy算法管理空闲页表的本质。
查看自己系统的页面情况

从左向右,依次是1,2,4,8… 页框大小的剩余个数
这里我在想一个问题:就是这样的一个算法,他最后不也是会形成许许多多的小的碎片的吗?那么Linux是怎样解决的呐?目前正在探索.
Slab 分配器
由来:
在Linux中,伙伴系统(buddy system)是以页为单位管理和分配内存。但是现实的需求却以字节为单位,假如我们需要申请20Bytes,总不能分配一页吧!那岂不是严重浪费内存。那么该如何分配呢?slab分配器就应运而生了,专为小内存分配而生。
Slab 分配器的作用?
- 频繁使用的数据结构也会频繁分配和释放,因此应当缓存它们。
- 解决小内存分配的问题
- 对存放的对象进行着色( color),以防止多个对象映射到相同的高速缓存行( cache line )。
Slab 分配器是什么?
slab分配器分配内存以Byte为单位。但是slab分配器并没有脱离伙伴系统。我们先来看一张图:

这里讲到的高速缓存结构就是下文中显示的kmem_cache
物理内存中有多个高速缓存,每个高速缓存都是一个结构体类型,一个高速缓存中会有一个或多个slab,slab通常为一页(连续的内存块),其中存放着数据结构类型的实例化对象。
分配高速缓存的接口是struct kmem_cache kmem_cache_create (const char *name, size_t size, size_t align,unsigned long flags, void (*ctor)(void ))
这个接口函数为一个结构体分配了高速缓存,那么高速缓存有了,是不是就要为缓存中分配实例化的对象呢?这个接口是
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags)
参数是kmem_cache结构体,也就是分配好的高速缓存,flags是标志位。
该函数从给定的高速缓存cachep中返回-一个指向对象的指针。如果高速缓存的所有slab中都没有空闲的对象,那么slab层必须通过kmem_ getpages() 获取新的页,fags 的值传递给_ getfree_ pages()。
具体的slab还分为三种,这里不再详述,下文给出参考链接

这里举个例子来说明,用struct kmem_cache结构描述的一段内存就称作一个slab缓存池。一个slab缓存池就像是一箱牛奶,一箱牛奶中有很多瓶牛奶,每瓶牛奶就是一个object。分配内存的时候,就相当于从牛奶箱中拿一瓶。总有拿完的一天。当箱子空的时候,你就需要去超市再买一箱回来。超市就相当于partial链表,超市存储着很多箱牛奶。如果超市也卖完了,自然就要从厂家进货,然后出售给你。厂家就相当于伙伴系统。
实例分析: 内核初始化期间,/kernel/fork.c的fork_init()中会创建一个名叫task_struct的高速缓存; 每当进程调用fork()时,会通过dup_task_struct()创建一个新的进程描述符,并调用do_fork(),完成从高速缓存中获取对象。
Maybe ,这种缓存方式的实现,就是一种写时复制.我还不清楚哦
总结:

以上内容都来自以下链接:
Linux内核内存管理算法Buddy和Slab
Linux内存管理
Linux内存管理原理
内存管理(Linux内核源码分析)