上篇博文写到爬取教务系统获取信息时,登录时的验证码是手动输入的,所以就想试试能不能自别识别验证码并填充。查阅了很多信息,选取了Tesseract。
What is Tesseract ?
Tesseract是能够运行在多种操作系统上的开源ORC(Optical Character Recognition , 光学字符识别)引擎,目前由Google维护,是最精确的开源ORC引擎之一。与Microsoft Office Document Imaging(MODI)相比,我们可以不断地训练,使图像转换文本的能力不断增强;如果团队深度需要,还能以它为模板,开发出符合自身需求的OCR引擎。
How to use Tesseract
1. 安装
ubuntu 下可以直接进行安装
sudo apt-get install tesseract-ocr安装图像解析的包
sudo apt-get install libpng12-dev
sudo apt-get install libjpeg62-dev
sudo apt-get install libtiff4-dev查看是否安装成功
limeng@KID:~$ tesseract --version
tesseract 4.0.0-beta.3-249-g607e
leptonica-1.76.0
libjpeg 6b (libjpeg-turbo 1.3.1) : libpng 1.2.54 : libtiff 4.0.8 : zlib 1.2.8 : libwebp 0.4.4 : libopenjp2 2.1.2
Found AVX2
Found AVX
Found SSE
其他发行版参考GitHub教程:https://github.com/tesseract-ocr/tesseract/wiki
2. 使用
tesseract imagename|imagelist|stdin outputbase|stdout [options...] [configfile...]以下内容为本人自己翻译,有可能不准确,有能力直接看英文使用手册即可。
OCR 的一些参数:
| 参数 | 作用 |
|---|---|
| -l LANG[+LANG] | 指定ORC使用的语言。 |
| -c VAR=VALUE | 指定一些配置,支持多组-c参数。 |
| –psm N | 指定分割模式。 |
| –oem N | 指定OCR引擎模式。 |
| –tessdata-dir PATH | 指定tessdata的位置。 |
| –user-words PATH | 指定user words file的位置。 |
| –user-patterns PATH | 指定patterns file的位置。 |
注意: 选项的使用要在任何配置文件前。
页面分割的模式:
| code | function |
|---|---|
| 0 | 只做方向和脚本的检测 (OSD)。 |
| 1 | 使用OSD自动分割。 |
| 2 | 自动分割,但不是用OSD或OCR。 |
| 3 | 完全自动分割,但不是用OSD。(缺省情况) |
| 4 | 假定是可变大小的单列文本。 |
| 5 | 假定是个包含垂直对齐文本的整齐的块。 |
| 6 | 假定是个整齐的块。 |
| 7 | 把图像视为一行文字。 |
| 8 | 把图像视为单个单词。 |
| 9 | 将图像视为圆圈中的单个单词。 |
| 10 | 把图像视为单个字符。 |
| 11 | 稀疏文字,找到尽可能多的文本,不以特定的顺序。 |
| 12 | 稀疏文字,利用OSD处理。 |
| 13 | 原生线,通过传递Tesseract特殊的信息把图像视为单一的文本行。 |
OCR 引擎模式:
| code | function |
|---|---|
| 0 | 只用传统引擎 |
| 1 | 只用神经网络LSTM引擎 |
| 2 | 传统 + LSTM 引擎 |
| 3 | 默认(缺省),基于有哪个引擎 |
在网上找了一个比较好识别的图片,如下:
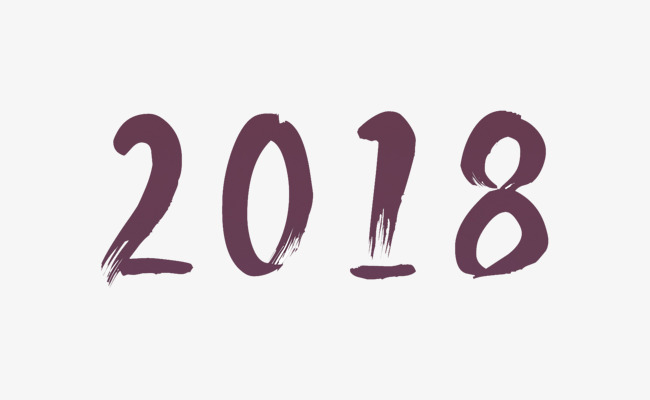
识别结果如下:
limeng@KID:~/Desktop$ tesseract test.jpg result -l eng --psm 7 digits
Tesseract Open Source OCR Engine v4.0.0-beta.3-249-g607e with Leptonica
limeng@KID:~/Desktop$ cat result.txt
2018因为没有对图片灰度化、二值化、降噪等处理,直接识别不能保证很准确。
在程序中使用
直接用调用上面用到的命令
//OCR的使用是以命令方式调用
public static String getImgText(String imgPath) {
String result = "";
BufferedReader br = null;
//识别语言
String ocrLangData = "-l eng";
String outPath = imgPath.substring(0, imgPath.lastIndexOf("."));
File file = new File(outPath + ".txt");
try {
//终端执行
Runtime runtime = Runtime.getRuntime();
String command = "tesseract " + imgPath + " " + outPath +" "+ ocrLangData +" digits";
Process ps = runtime.exec(command);
ps.waitFor();
//读取文件
br = new BufferedReader(new FileReader(file));
String temp = "";
StringBuffer sb = new StringBuffer();
while ((temp = br.readLine()) != null) {
sb.append(temp);
}
//保存识别结果
result = sb.toString();
} catch (Exception e) {
System.out.println("识别图片异常!");
e.printStackTrace();
}finally{
try {
br.close();
file.delete();
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}Summary
自己以前并没有接触过模式识别过一块,只稍微了解了一下,看了李飞飞(斯坦福计算机视觉实验室负责人)在TED的演讲,感觉如何研究计算机识别图片并理解图片是蛮有趣的,但是感觉自己差很多东西,毕竟自己没有接触过AI(Artificial Intelligence)和深度学习(Deep learning)等。
以前总感觉它们太遥远,其实就在我们身边。
References
Tesseract的man手册