定义
给定n个权值作为n个叶子结点,构造一棵二叉树,若带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。
相关基本概念
路径:从树中一个结点到另一个结点之间的分支序列构成两个节点间的路径。
路径长度:路径上分支的条数成为路径长度。
树的路径长度:从树根到每个结点的路径长度之和称为树的路径长度。
结点的权:给树中结点赋予一个数值,该数值称为结点的权。
带权路径长度:结点到树根间的路径长度与结点权的乘积,称为该结点的带权路径长度。
树的带权路径长度:树中所有叶子结点的带权路径长度之和,记为WPL。
最优二叉树:在叶子个数n以及各叶子的权值Wk确定的条件下,树的带权路径长度WPL值最小的二叉树称为最优二叉树。
哈夫曼树的建立
(1)初始化:根据给定的n个权值,构造n棵二叉树的森林集合F={T1,T2,…,Tn},其中每棵二叉树只有一个权值为Wi的根节点,左右子树均为空。
(2)找最小的树并构造新的树:在森林集合F中选取两颗根的权值最小的树作为左右子树构造一棵新的二叉树,新二叉树的根结点为新增加的结点,其权值为左右子树根的权值之和。
(3)删除与插入:在森林集合中删除已选取的两棵根的权值最小的树,同时将新构造的二叉树加入到森林集合F中。
(4)重复(2)和(3)步骤:直到森林集合只含有一棵树为止,这棵树即为哈夫曼树。
过程模拟:
报文A,B,C,D,E,F这6个字符构成,它们出现的频度为:3 4 10 8 6 5
首先初始化,建立6棵二叉树的森林集合

权值最小的为3和4
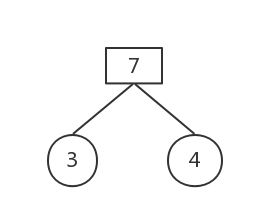
删除这两棵树,构建新树,权值为7
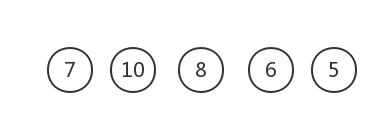
权值最小的为5和6
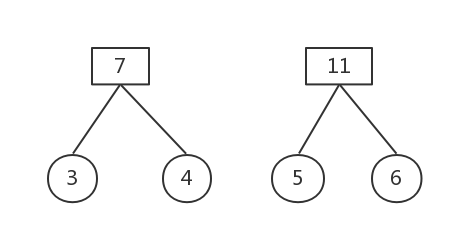
删除这两棵树,构建新树,权值为11
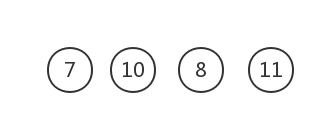
权值最小的为7和8
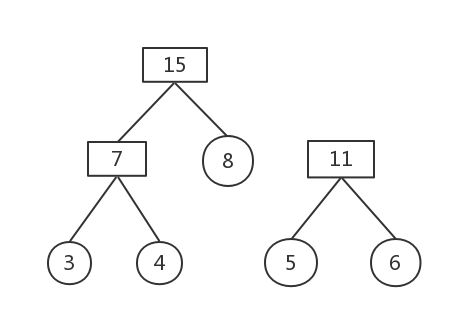
删除这两棵树,构建新树,权值为15
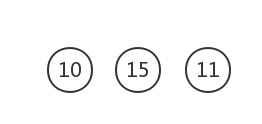
权值最小的为10和11
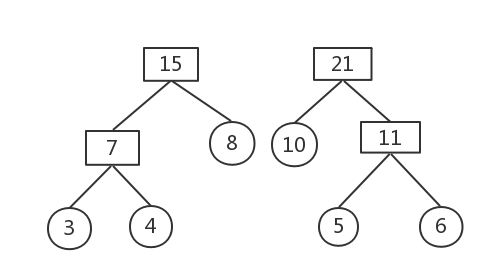
删除这两棵树,构建新树,权值为21
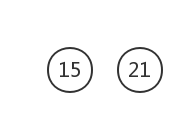
权值最小的为15和21
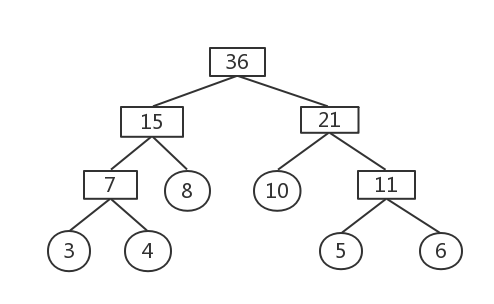
删除这两棵树,构建新树,权值为36
此时森林集合中只剩一棵树,哈夫曼树构建完成
哈夫曼树存储结构
静态三叉链表
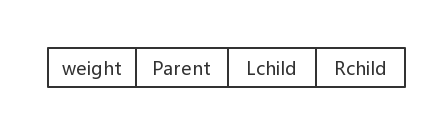
weight:结点的权值;
Parent:双亲结点在数组中的下标
Lchild:左孩子结点在数组中的下标
Rchild:右孩子结点在数组中的下标
n个叶子的哈夫曼,恰有n-1个度为2的结点,即哈夫曼树共有2n-1个结点
类型定义如下
#define N 30
#define M 2*N-1
typedef struct{
int weight;
int parent,Lchild,Rchild;
}HTNode,HuffmanTree[M+1]; //0号单元不使用哈夫曼编码
编码
前缀编码:同一字符集任何一个字符的编码都不是另一个字符编码的前缀(最左字串),这种编码称为前缀编码。
要想有效的压缩信息,要使字符集中出现频率较高的字符编码尽可能短,出现频率不高的字符则可以略长一些。
而观察哈夫曼树可以发现,权值大的叶子距离根近,权值小的距离根远,所以可以用哈夫曼树中跟到各叶子的路径设计编码。
在哈夫曼树中约定:左分支表示符号’0’,右分支表示符号’1’。
例如,一棵哈夫曼树如图所示
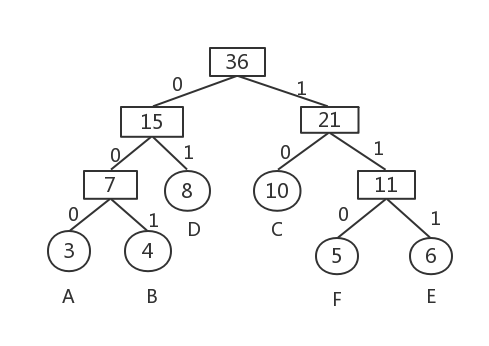
则哈夫曼编码为:
A:000
B:001
C:10
D:01
E:111
F:110
总的来说,哈夫曼树是WPL最小的树,因此,哈夫曼编码可以使信息压缩达到最短的编码。哈夫曼编码就是最优二进制前缀编码。
算法实现
(1)构造哈夫曼树
(2)在哈夫曼树上求个叶子结点的编码
译码
任何经编码压缩、传输的数据,使用时均应该进行译码。
译码过程是分解、识别各个字符,还原数据的过程。
从字符串头开始扫描到尾,依次去匹配。
实例分析
给定报文,哈弗曼编码、译码
题目描述
已知某段通信报文内容,对该报文进行哈弗曼编码,并计算平均码长。
(1)统计报文中各字符出现的频度。(字符集范围为52个英文字母,空格,英文句号。报文长度<=200)
(2)构造一棵哈弗曼树,依次给出各字符编码结果。
(3)给字符串进行编码。
(4)给编码串进行译码。
(5)计算平均码长。
规定:
(1)结点统计:以ASCII码的顺序依次排列,例如:空格,英文句号,大写字母,小写字母。
(2)构建哈弗曼树时:左子树根结点权值小于等于右子树根结点权值。
(3)选择的根节点权值相同时,前者构建为双亲的左孩子,后者为右孩子。
(4)生成编码时:左分支标0,右分支标1。
输入
第一部分:报文内容,以’#’结束。
第二部分:待译码的编码串。
输出
依次输出报文编码串、译码串、平均码长,三者之间均以换行符间隔。
平均码长,保留小数点2位。
解题思路
(1)统计各个字符出现的频度,在存权值时,也要存下来该字符
(2)构建哈夫曼树
(3)哈夫曼编码
(4)哈夫曼译码
代码实现
具体分析在代码中注释,比较清晰
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<math.h>
#define N 30
#define M 2*N-1
typedef struct{
int weight;
int parent,Lchild,Rchild;
}HTNode,HuffmanTree[M+1];
typedef char** huffmanCode;
void Select(HuffmanTree ht,int j,int *s1,int *s2);//找出森林集合中根权值最小的两个
void CrtHuffmanTree(HuffmanTree ht, int w[], int n);//构建哈夫曼树
void CrtHuffmanCode1(HuffmanTree ht,huffmanCode hc,int n);//哈夫曼编码
int find_code(huffmanCode hc,int n,char *dest,int *result);//在生成的哈夫曼编码中查询目标
//找出森林集合中根权值最小的两个
void Select(HuffmanTree ht,int j,int *s1,int *s2)
{
int i;
//int占4个字节,最大为2147483647
int min = 2147483647;
for(i=1;i<=j;i++){
if((ht[i].parent == 0) && ht[i].weight < min){
min = ht[i].weight;
*s1 = i;
}
}
int lessmin = 2147483647;
for(i=1;i<=j;i++){
if((ht[i].parent == 0) && ht[i].weight < lessmin && i != *s1){
//下标不能相同
lessmin = ht[i].weight;
*s2 = i;
}
}
}
//建立哈夫曼树
void CrtHuffmanTree(HuffmanTree ht, int w[], int n)
{
int m,i;
m = 2*n-1;
for(i=1;i<=n;i++){
ht[i].weight = w[i];//初始化前n个元素成为根结点
ht[i].parent = 0;
ht[i].Lchild = 0;
ht[i].Rchild = 0;
}
for(i=n+1;i<=m;i++){ //初始化后n-1个元素
ht[i].weight = 0;
ht[i].parent = 0;
ht[i].Lchild = 0;
ht[i].Rchild = 0;
}
for(i=n+1;i<=m;i++) //从第n+1个元素开始构造新结点
{
int s1,s2;
//在ht的前i-1项中选择双亲为0且全值较小的两结点s1,s2
Select(ht,i-1,&s1,&s2);
ht[i].weight = ht[s1].weight + ht[s2].weight;//建立新结点,赋权值
ht[i].Lchild = s1;
ht[i].Rchild = s2; //赋新结点左右孩子的指针
ht[s1].parent = i;
ht[s2].parent = i; //改s1,s2的双亲指针
}
}
//哈夫曼编码
void CrtHuffmanCode1(HuffmanTree ht,huffmanCode hc,int n)
{
//从叶子到根,逆向求各叶子结点的编码
char *cd;
int start,i,c,p;
cd = (char * )malloc(n*sizeof(char ));//临时编码数组
cd[n-1] = '\0'; //从后向前逐位求编码,首先放置结束符
for(i=1;i<=n;i++) //从每个叶子开始,求相应的哈夫曼编码
{
start = n-1;
c = i;
p = ht[i].parent; //c为当前节点,p为其双亲
while(p!=0){
--start;
if(ht[p].Lchild == c)
cd[start] = '0';//左分支为'0'
else
cd[start] = '1';//右分支为'1'
c = p;
p = ht[p].parent; //上溯一层
}
hc[i] = (char *)malloc((n-start)*sizeof(char)); //动态申请编码空间
strcpy(hc[i],&cd[start]); //复制编码
}
}
//在生成的哈夫曼编码中查询目标
int find_code(huffmanCode hc,int n,char *dest,int *result)
{
int i ;
for(i=1;i<=n;i++){
if(strcmp(dest,hc[i])==0){
*result = i;
return 1;
}
}
return 0;
}
//主函数
int main(void)
{
HuffmanTree ht;
huffmanCode hc;
int n,i;
int w[100]; //用来存取权值
int chlist[100];//用来存取相应的字符
int cal[128] = {0};
char str[10001];
char code[10001];
char tmp;
while((tmp=getchar())!='#')
{
str[i] = tmp;
i++;
}
str[i] = '\0';
getchar();
gets(code);
//计算各个字符出现的频度
for(i=0;i<strlen(str);i++)
cal[str[i]]++;
//将各个字符及权值存下来
int j = 1;
for(i=32;i<=122;i++){
//空格为32,z为122,题中所出现的字符都在这个范围中
if(cal[i]>0){
w[j] = cal[i];
chlist[j] = i;
j++;
}
}
//计算字符个数并构建哈夫曼树
n=j-1;
CrtHuffmanTree(ht,w,n);
//存取哈夫曼编码
hc = malloc(sizeof(char)*(n+1)*(n+1));
CrtHuffmanCode1(ht,hc,n);
//编码,并计算编码结果的总长度
long long codelength = 0;
for(i=0;i<strlen(str);i++){
for(int x=1;x<=n;x++){
if(str[i]== chlist[x]){
printf("%s",hc[x]);
codelength +=strlen(hc[x]);
break;
}
}
}
printf("\n");
//译码
char temp[100];
int result;
int k = 0;
for(i=0;i<strlen(code);i++){
temp[k] = code[i];
if(find_code(hc,n,temp,&result)){//看是否匹配
putchar(chlist[result]);
k = 0;
memset(&temp,0,sizeof(temp));//若是匹配要输出结果,并将临时数组置空
}
else{
k++; //不匹配将下一个字符添加进来再判断
}
}
printf("\n");
//输出平均码长,平均码长为:编码总长/原始数据长度
printf("%0.2f\n",(codelength*1.0)/strlen(str));
free(hc);//要注意malloc和free要搭配使用,学习了
return 0;
}
关于优化
可以在存取哈夫曼编码时采用键值对,省去查找编码时的遍历。