这几天数据库课没有好好听,老师讲话的速度对我来说确实有点快,听的我云里雾里,在课堂上只能虚伪的配合老师的自我陶醉,再加上本来就听不懂,还来个翻转课堂,有些准备的学生有些上去讲的更是乱七八糟。所以还是下面花时间自我修行吧!毕竟数据库还是比较重要的课程。
老师真的讲的…(此处省略n个字)
所以呢,我也不知道从何讲起,那讲一点实践的东西吧!
数据库系统支持三级模式结构,其模式,内模式,外模式中的基本对象有模式、表、视图、索引等。因此SQL的数据定义功能包括模式定义,表定义,视图和索引的定义。
SQL的数据定义语句

一个关系DBMS的实例中可以建立多个数据库,一个数据库中可以建立多个模式,一个模式下通常包括多个表,视图,索引等数据库对象。

创建模式:create schema <模式名>authorization<用户名>;
例:
为用户chang创建一个模式test,并在其中定义一个表table1。
create schema test authorization chang create table table1(col smallint,col1 int);
删除模式:
drop schema<模式名><cascade 或者restrict>;
cascade(级联):表示在删除模式的同时将模式中的所有数据库对象全部删除。
redistrct(限制):如果该模式下定义了下属数据库对象,则拒绝删除语句的执行。只有该模式下没有任何下属数据库对象时才能执行drop schema语句。
*定义表
这个感觉挺常用的。
定义表的格式:
create <表名>(<列名><数据类型>[列级完整性约束条件],<列名><数据类型>[列级完整性约束条件]......);
例如:建立一个学生表student1,属性有id,sno,sname,ssex这些吧!
create table student1(id int auto_increment, sno varchar(12),sname varchar(12),ssex varchar(12),primary key(id));
auto_increment,primary key:设置id为主键,从1开始递增。
创建好表后,插入元素:
 关于主键和外键:表中元素的主键是不能重复的,主要由计算机自动生成,主键的存在对用户没有意义。用户尽量不要手动修改或者设置主键。外键,外键用于保持数据一致性,完整性,主要目的是控制存储在外键表中的数据。
关于主键和外键:表中元素的主键是不能重复的,主要由计算机自动生成,主键的存在对用户没有意义。用户尽量不要手动修改或者设置主键。外键,外键用于保持数据一致性,完整性,主要目的是控制存储在外键表中的数据。
例
建立一个课程表course
create table course1(id int auto_increment,cno char(4), cname char(20) not NULL, cpno char(12),credit int, foreign key(cpno) references course1(cno),primary key(id));
cno) );
以上cname 有列级完整性约束条件(即cname不能为空),Cno表级完整性约束条件,cpno为外键,被参照表为course1,被参照列为cno。
在 “Persons” 表创建时在 “Id_P” 列创建 UNIQUE 约束:
CREATE TABLE Persons(Id_P int NOT NULL,LastName varchar(255) NOT NULL,
FirstName varchar(255),Address varchar(255),City varchar(255),UNIQUE (Id_P));
区分unique 约束和primary key:
UNIQUE 约束唯一标识数据库表中的每条记录。UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。PRIMARY KEY 拥有自动定义的 UNIQUE 约束,每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束。
修改表
在以后的存储数据中,我们肯定避免不了修改数据库中的数据,所以修改操作也是比较常用的操作,一定得掌握!
修改格式:
alter table
<表名>[add [column]<列名><数据类型>[完整性约束]]
<add <表级完整性约束>>
<drop[column]<列名>[cascade或diestrict]>
<drop constraint<完整约束名>[restrict或cascade]>
[alter column <列名><数据类型>]
修改操作确实比较多样化呀!
- 删除
drop table<表名>[restrict或者cascade];
同样的,要是选择cascade,该表的删除没有限制条件,再删除基本表的同时,相关的依赖对象将被一同删除。如相关视图。
district则限制这一操作,当表有依赖关系的对象的话,不允许删除操作的执行。
视图
视图是从一个或几个基本表(或视图)中导出的虚拟的表。在系统的数据字典中仅存放了视图的定义,不存放视图对应的数据。
视图是原始数据库数据的一种变换,是查看表中数据的另外一种方式。可以将视图看成是一个移动的窗口,通过它可以看到感兴趣的数据。 视图是从一个或多个实际表中获得的,这些表的数据存放在数据库中。那些用于产生视图的表叫做该视图的基表。一个视图也可以从另一个视图中产生。
视图的创建:
例
创建一个视图cs_student,只包含专业为cs的student表的学号,姓名,年龄。
create view cs_student as select sno,sname,sage from student where sdept=“cs”;

一个表要是有了视图的话,删除时应该考虑清楚,不然及其相关视图中的元素也被清除。
删除表时带上destrict,我的数据库要是不带destrict限制,他的默认模式为cascade模式。
drop table student destrict;
*关于数据库的查询操作
数据库的查询操作是学习数据库的核心操作,查询有灵活的使用方式和功能。
一般格式:
select [all或者distinct]<目标表达式>,<目标表达式>…
from [<表名/视图名>…]<select 语句>[as]<别名>[where <条件表达式>]
[group by<列名1>[having <条件表达式>]]
[order by<列名2>[ASC|DESC]];
整个select语句的含义是,根据整个where子句的表达式从from子句指定的基本表、视图或者派生表中找出满足条件的元祖,再按照select子句的目标表达式选出元祖中的属性值,形成结果表。
如果有group by语句,则将结果按照<列名1>的值进行分组 该属性列值相等的元组为一个组,通常会在每组中作用聚集函数。如果group by带having语句则只有满足条件的组才予以输出。
如果有order by子句,则结果表还是按照<列名2>的值的升序或降序排序。
单表查询
查询全体学生的姓名和学号。
select sno,sname from student1;
查询全体学生的出生年份,和姓名。
select sno,birth_year from student1 ;
 我们也可以为输出的列名起个别名,不会改变数据库中的列名。例如:
我们也可以为输出的列名起个别名,不会改变数据库中的列名。例如:
select sno XUE_HAO,birth_year BIRTH from student1 ;
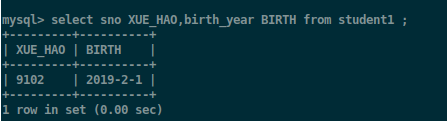
要是想改数据库中的列名:
alter table student1 change birth_year BIRTH varchar(12);
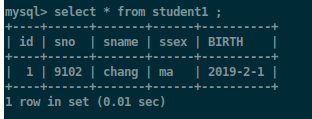
查询表中学生的姓名:
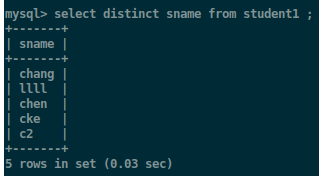
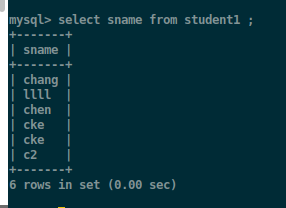 使得表中的元素输出是不重复的
使得表中的元素输出是不重复的
查询满足条件的元祖:
查询表中学生姓名为cke的学生信息。
select * from student1 where sname=“cke”;
根据一定范围查询:
between…and…
我们先为student1表中添加一个年龄列:
alter table student1 add column age int;
再为每个学生设置一下年龄:
update student1 set age=18 where sname=‘cke’;
查询
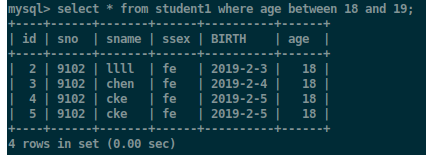
查询年龄在18-19之间的学生
select * from student where age between 18 and 19;
模糊查询:
查询姓名以c开头的学生的信息。
select * from student1 where sname like ‘c%’;
其他的查询谓词见下表:

对于数据库学习就总结至此了。