首先,文章的开篇我们先看几个概念
用户级线程
用户级线程顾名思义就是用户态下的线程,用户线程的建立,同步,销毁,调度完全在用户空间完成,不需要内核的帮助。因此这种线程的操作是极其快速的且低消耗的。
内核线程
内核级线程,是指由内核管理的线程
多线程模型
多对一
这种模型下创建的许多用户线程就会如下图所示。
- 优点就是创建的代价非常小
- 缺点也很明显,当一个线程阻塞住,该内核上的其它用户线程也会阻塞。因为同一时刻只有一个线程能运行在内核上,所以也不是并行执行。

一对一模型
如图所示

该模型下的优缺点也很明显 - 优点:每个线程都有一个内核与之对应,是真正意义上的并行,当一个线程阻塞的时候其它线程还能正常运行。
- 缺点:计算机中的核是有限的,当创建的线程过多时,会导致cpu频繁的切换线程降低效率。
多对多模型
多路复用多个用户线程到同样数量(或更少)的内核线程上。

二级模型:多对多模型的变种,允许将一个用户线程绑定到某个内核线程上。

线程库
线程库为程序员提供i创建和管理线程的API主要有两种方法来实现线程库。第一种方法是在用户空间中提供一个没有内核支持的库,此库的所有代码和数据结构都存在于用户空间中。调用库中的一个函数只是导致了用户空间中的一个本地函数调用,而不是系统调用。第二种方法是执行一个由操作系统直接支持的内核级的库。此时,库的代码和数据结构存在于内核空间中。调用库中的一个API函数通常会导致对内核的系统调用。
目前使用的三种主要的线程库是:
- POSIX Pthread
- Win
- Java
Pthread作为POSIX标准的扩展,可以提供用户级或内核级的库。
线程调度(调度程序激活)
- 调度程序激活:是内核与线程库之间的通信方法。可以动态调整内核线程的数量以保证其最好的性能。
该线程调度针对的是前面讲述的多对多模型。
许多实现多对多模型的系统在用户和内核线程之间设置一种中间数据结构——通常是轻量级进程LWP,如下图所示。对于用户程序而言,LWP表现为一种应用程序可以调度用户线程来运行的虚拟处理器。每个LWP与内核线程相连,该内核线程被操作系统调度到物理处理器上运行。如果内核线程阻塞,则LWP也阻塞。与LWP相连的用户线程也阻塞。
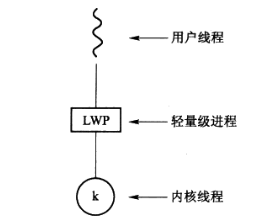
为了高效的运行,应用程序就需要一定数量的LWP。考虑到一个内核只能同时运行一个线程,所以只要一个LWP就够了,但是当遇到I/O请求密集的应用程序就可能需要多个LWP来执行。举个栗子:有5个不同的文件读请求可能同时发生,此时就需要5个LWP,因为每个都需要等待内核I/O的完成。如果只有4个LWP,那么第五个请求就必须要等待其中一个LWP从内核返回之后才能运行。
操作系统为了解决这种问题,发明了调度激活器,是解决用户线程库与内核间通信的方法。它的工作方式为:内核提供一组虚拟处理器(LWP)给应用程序,应用程序可调度用户线程到一个可用的虚拟处理器上。内核需要告知用户该线程的运行状态,这个过程被称为upcall。
- upcall:内核通知应用程序与其有关的特定事件的过程;
- upcall handler:upcall处理句柄,在虚拟处理器(LWP)上运行。
当一个应用线程阻塞时,事件就会引发一个upcall。在这个例子中,内核向应用程序发出一个upcall,通知它线程阻塞并标识特殊的线程。然后内核会分配一个新的虚拟处理器提供给应用程序,应用程序会在这个新的虚拟处理器上运行upcall处理程序,**它保存阻塞线程状态和放弃阻塞线程运行的虚拟处理器。**然后upcall调度一个适合在新的虚拟处理器上运行的线程,**当阻塞线程事件等待发生时,内核向线程库发出另一个upcall,来通知它先前阻塞的线程可以运行了。**此事件的upcall处理程序也需要一个虚拟处理器,内核可能分配一个新的虚拟处理器或先占一个用户线程并在其虚拟处理器上运行upcall处理程序。在使非阻塞线程可以运行后,应用程序调度符合条件的线程来在一个适当的虚拟处理器上运行。
上面是详细的概念,现在来简化的大概说下它的流程:
- 当一个应用程序要阻塞时,事件引发内核发送一个upcall到应用程序,通知应用程序阻塞并标识特殊的线程。
- 内核会分配一个新的虚拟处理器(LWP)给应用程序
- 保存阻塞线程状态和放弃阻塞线程运行的虚拟处理器,upcall会调度一个新的线程运行。
- 当阻塞线程可以运行,内核向线程库发出upcall表明之前阻塞的线程可以运行。因为该事件的upcall必须运行在虚拟处理器上,所以内核要为其分配一个新的LWP或者占用一个线程运行。
- 通知完成后,非阻塞线程可以运行,应用程序需要调度符合条件的线程来运行在LWP上。
Linux下用pthread_create创建的是用户线程还是内核线程?Linux的线程库NPTL用的是哪种模型?可以看看下面的回答。
作者:大河
链接
关于线程的概念不多说了,内核级和用户级线程的定义网上也有,简单的说:内核级就是操作系统内核支持,用户级就是函数库实现(也就是说,不管你操作系统是不是支持线程的,我都可以在你上面用多线程编程)。好了,那么,我们首先明白一件事:不管Linux还是什么OS,都可以多线程编程的,怎么多线程编程呢?程序员要创建一个线程,当然需要使用xxx函数,这个函数如果是操作系统本身就提供的系统函数,当然没问题,操作系统创建的线程,自然是内核级的了。如果操作系统没有提供“创建线程”的函数(比如Linux 2.4及以前的版本,因为Linux刚诞生那时候,还没有“线程”的概念,能处理多“进程”就不错了),当然你程序员也没办法在操作系统上创建线程。所以,Linux 2.4内核中不知道什么是“线程”,只有一个“task_struct”的数据结构,就是进程。那么,后来随着科学技术的发展,大家提出线程的概念,而且,线程有时候的确是个好东西,于是,我们希望Linux能加入“多线程”编程。要修改一个操作系统,那是很复杂的事情,特别是当操作系统越来越庞大的时候。怎么才能让Linux支持“多线程”呢?首先,最简单的,就是不去动操作系统的“内核”,而是写一个函数库来“模拟”线程。也就是说,我用C写一个函数,比如 create_thread,这个函数最终在Linux的内核里还是去调用了创建“进程”的函数去创建了一个进程(因为OS没变嘛,没有线程这个东西)。 如果有人要多线程编程,那么你就调用 这个create_thread 去创建线程吧,好了,这个线程,就是用库函数创建的线程,就是所谓的“用户级线程”了。等等,这是神马意思?赤裸裸的欺骗?也不是。为什么不是?因为别人给你提供了这个线程函数,你创建了“线程”,那么,你的线程(虽然本质上还是进程)就有了“线程”的一些“特征”,比如可以共享变量啊什么的,咦?那怎么做到的?当然有一套机制,反正人家给你做好了,你用就行了。这种欺骗自然是不“完美”的,有线程的“一些”特征,但不能完全符合理论上的“线程”的概念(POSIX的要求),比如,这种多线程不能被分配到多核上,用户创建的N个线程,对于着内核里面其实就一个“进程”,导致调度啊,管理啊麻烦…为什么要采用这种“模拟”的方式呢?改内核不是一天两天的事情,先将就用着吧。内核慢慢来改。怎么干改内核这个艰苦卓越的工作?Linux是开源、免费的,谁愿意来干这个活?有两家公司参与了对LinuxThreads的改进(向他们致敬):IBM启动的NGTP(Next Generation POSIX Threads)项目,以及红帽Redhat公司的NPTL(Native POSIX Thread Library),IBM那个项目,在2003年因为种种原因放弃了,大家都转到NPTL这个项目来了。最终,当然是成功了,在Linux 2.6的内核版本中,这个NPTL项目怎么做的呢?并不是在Linux内核中加了一个“线程”,仍然和原来一样,进程(其实,进程线程就是个概念,对于计算机,只要能高效的实现这个概念就行,程序员能用就OK,管它究竟怎么实现的),不过,用的clone实现的轻量级进程,内核又增加了若干机制来保证线程的表现和POSIX相同,最关键的一点,用户调用pthread库创建的一个线程,会在内核创建一个“线程”,这就是所谓的1:1模型。所以,Linux下,是有“内核级”线程的,网上很多说Linux是用户级线程,都是不完整的,说的Linux很早以前的版本(现在Linux已经是4.X的版本了)。还有个 pthread 的问题,pthread是个线程函数库,他提供了一些函数,让程序员可以用它来创建,使用线程。那么问题是,这个函数库里面的函数,比如 pthread_create 创建线程的函数,他是怎么实现的呢?他如果是用以前的方法,那程序员用它来创建的线程,还是“用户级”线程;如果它使用了NPTL方式创建线程,那么,它创建的线程,就是“内核级”线程。OK,结论,如果你 1:使用2.6的内核的系统平台,2:你的gcc支持NPTL (现在一般都支持),那么你编译出来的多线程程序,就是“内核级”线程了。所以,现在回答问题,只要你不是很古董级的电脑,Linux下用pthread创建的线程是“内核级线程”最后,这NPTL也并不是完美的,还有一些小问题,像有一些商业操作系统,可以实现混合模型,如1:1,N:M等(就是内核线程和用户线程的对应关系),这就强大了,Linux仍有改进的空间。