引言
感谢MIT为全球有此兴趣的人提供如此高质量的课程,这门课程让我感受到了分布式的美妙与深邃,做lab1的时候还感觉云里雾里,因为有一点点兴趣,遂也继续下去,做完lab2,终于明白了我不是干程序员的料,已成功转行,现在已经把电脑砸了,正在市中心推销游泳健身,一月加提成2W+,感谢这个实验为我带来的一切。

简单发一个小小的牢骚,看官一笑即可~~ 不过有一说一,这个课程的part B非常有难度,如果说lab1,和lab2 PartA只是小打小闹的话,PartB就是正儿八经的大刀阔斧了。PartB引入了很多容错问题,这些问题有一些是在paper中有所提及的,但很多其实并没有在paper中提到,这导致在过不了测试样例的时候我们需要根据测试代码去找是哪里出了问题,我是一个分布式小白,同时也是一个Go小白,对于我来说分布式代码最好调试方式就是去打印(也许叫日志不那么low),去分析是哪里出现了问题,同时还需要结合paper才能分析出一些问题的原因所在。
这篇文章的主体思路是先分析下PartB的逻辑过程,然后说几点我在写的时候遇到的错误,最后逐函数说一下作用,最后附上全部的代码,也就是raft.go这个文件。
逻辑过程
首先PartB部分我们需要完成的是”实现领导者和随从者代码达到追加新的日志节点的目标“,也就是Raft算法的第二部分,即附加日志,这里我们需要考虑容错问题,即leader宕机,小部分follower宕机可以完成协议,大部分follower宕机无法完成协议,并发写入等各种情况。因为框架中只给我们了一个start函数,所以RPC部分也需要我们自己补充,不过这个并不困难。想要理解start函数干了什么,我们还是得看看测试代码,我们看看最简单的测试函数TestBasicAgree
func TestBasicAgree(t *testing.T) {
servers := 5
cfg := make_config(t, servers, false) // 创建5个节点,并互相连接
defer cfg.cleanup()
fmt.Printf("Test: basic agreement ...\n")
iters := 3
for index := 1; index < iters+1; index++ {
nd, _ := cfg.nCommitted(index) //有多少个节点认为下标为index的日志已经提交 返回{已提交数,命令}
if nd > 0 { // 这里注意index始终大于正常的日志 所以这里不能大于0
t.Fatalf("some have committed before Start()")
}
xindex := cfg.one(index*100, servers) //实际上就是完成了一次协议 即向Leader提交一个命令
if xindex != index {
t.Fatalf("got index %v but expected %v", xindex, index)
}
}
fmt.Printf(" ... Passed\n")
}
func (cfg *config) one(cmd int, expectedServers int) int {
t0 := time.Now()
starts := 0
for time.Since(t0).Seconds() < 10 {
// try all the servers, maybe one is the leader.
index := -1
for si := 0; si < cfg.n; si++ {
starts = (starts + 1) % cfg.n
var rf *Raft
cfg.mu.Lock()
if cfg.connected[starts] {
rf = cfg.rafts[starts]
}
cfg.mu.Unlock()
if rf != nil {
index1, _, ok := rf.Start(cmd) //这个函数使我们要填写的函数 返回写入日志的index
if ok { //返回ok证明下表是Leader
index = index1
break
}
}
}
if index != -1 { //找到了一个Leader
// somebody claimed to be the leader and to have
// submitted our command; wait a while for agreement.
t1 := time.Now()
for time.Since(t1).Seconds() < 2 { //循环两秒
nd, cmd1 := cfg.nCommitted(index) //查看start函数返回值index位置上的日志是否是cmd
if nd > 0 && nd >= expectedServers { //已经提交的日志数大于expectedServers
// committed
if cmd2, ok := cmd1.(int); ok && cmd2 == cmd {
// and it was the command we submitted.
return index
}
}
time.Sleep(20 * time.Millisecond)
}
} else {
time.Sleep(50 * time.Millisecond)
}
}
cfg.t.Fatalf("one(%v) failed to reach agreement", cmd)
return -1
}
我们可以看到Start函数实际的语义其实就是提交一个日志,而之后如何把它同步到follower,那就是我们的问题了,这里我的方法就是在心跳包中进行同步,不做额外的逻辑,在应该发送心跳包的时候如果有额外的日志就附带上日志,如果没有的话就是一个简单的心跳包。
这里我们也可以看出其实心跳包和一般的附加日志的结构体其实在逻辑上是差不多的,只不过heartbeat没有日志项而已,然后的问题是这个结构体该如何设计,我们使用论文中结构,如下:

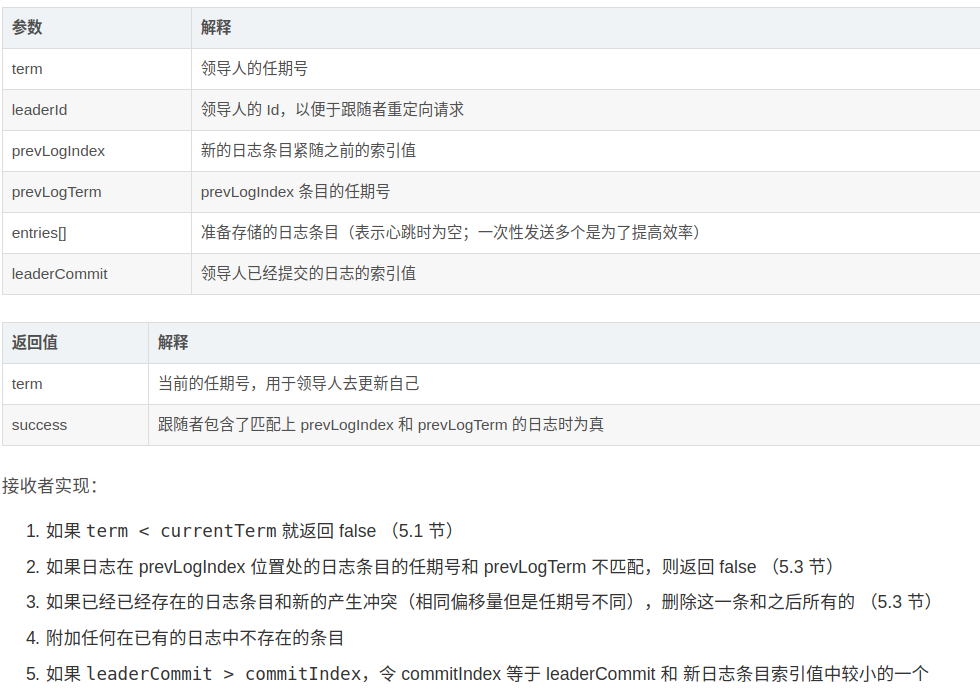
type AppendEntryArgs struct {
Term int // leader的任期号
LeaderId int // leaderID 便于进行重定向
PrevLogIndex int // 新日志之前日志的索引值
PrevLogTerm int // 新日志之前日志的Term
Entries []LogEntry // 存储的日志条目 为空时是心跳包
LeaderCommit int // leader已经提交的日志的索引
}
type AppendEntryReply struct {
Term int // 用于更新leader本身 因为leader可能会出现分区
Success bool // follower如果跟上了PrevLogIndex,PrevLogTerm的话为true,否则的话需要与leader同步日志
CommitIndex int // 用于返回与leader.Term的匹配项,方便同步日志
}
如果你看过Raft动画演示[1]的话,你就会知道在选举阶段有两个超时时间,一个是electionTimeout和heartbeatTimeout,这是非常重要的一件事情,我们上面说道,日志同步的过程其实和心跳包的过程差不多,唯一的区别就是一个日志项不为空,一个为空而已。所以当有一个日志项在leader中被添加的时候我们的处理逻辑是什么呢?也就是Start函数逻辑,我们只需要加入日志项,等到heartbeatTimeout的时候会自动发送出附加日志消息,这样看来PartB我们首先需要写一个heartbeat超时事件,其中当然涉及到RPC,然后还需要写一个RPC的处理函数,随后再补充一个处理RPC处理函数的函数(好像有一点绕)。
易错点
实验中也明确提到这一部分最重要的部分就是容错部分,而且有些错误是论文中也没有提到的,所以需要我们以身试错,以下的一些点希望大家能在完成实验的时候注意:
- 可能出现小部分follower出现网络分区,如果我们不加以判断,就会出现这部分follower不停的进行选举,然后选举失败,由进行选举,这样它们的Term会暴增,远大于没有出现分区的节点的Term,导致重连以后丢失大量的日志。
- 并行添加日志的时候各节点收到的顺序可能不同,需要我们使用PrevlogIndex进行维护。
- 重设时钟的时候一定要记得先关闭,因为对Go不熟,这样导致Term瞬间突破天际。
- 在发送leader发送完心跳包,leader端的处理函数中一定要重置时间,否则会导致不停的进行选举。
- 在发送日志项和leader处理日志项的时候一定要判断当前节点是否还是leader,因为可能有一些消息会延迟到来,导致这种情况,这是真实会发生的。
- 再就是paper中所强调的了。
正文
首先是RPC和leader在成功选举的时候需要广播选举信息的函数SendAppendEntriesToAllFollwer,
func (rf *Raft) SendAppendEntryToFollower(server int, args AppendEntryArgs, reply *AppendEntryReply) bool {
ok := rf.peers[server].Call("Raft.AppendEntries", args, reply)
return ok
}
// 用于发送附加日志项给其他服务器 也就是心跳包 超时时间为heartbeatTimeout
func (rf *Raft) SendAppendEntriesToAllFollwer() {
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
var args AppendEntryArgs
args.Term = rf.currentTerm
args.LeaderId = rf.me
args.PrevLogIndex = rf.nextIndex[i] - 1 // 当前最新的索引
if args.PrevLogIndex >= 0 {
//fmt.Printf("%d %d\n",args.PrevLogIndex,len(rf.logs))
args.PrevLogTerm = rf.logs[args.PrevLogIndex].Term
}
// 当我们在Start中加入一条新日志的时候这里会在心跳包中发送出去
if rf.nextIndex[i] < len(rf.logs) { // 刚成为leader的时候更新过 所以第一次entry为空
args.Entries = rf.logs[rf.nextIndex[i]:] //如果日志小于leader的日志的话直接拷贝日志
}
args.LeaderCommit = rf.commitIndex
go func(servernumber int, args AppendEntryArgs, rf *Raft) {
var reply AppendEntryReply
retry :
if rf.current_state != "LEADER"{
return
}
ok := rf.SendAppendEntryToFollower(servernumber, args, &reply)
if ok {
rf.handleAppendEntries(servernumber, reply)
}else {
goto retry //附加日志失败的时候重新附加 这是很重要的 follower中对于附加日志项是幂等的
}
}(i, args, rf)
}
}
然后是follower中日志的处理函数AppendEntries,具体的逻辑是这样的
- 判断当前Term和leaderTerm的大小 前者大于后者的话拒绝 小于的话改变节点状态。
- 进行一个错误判断,Leader节点保存的nextIndex为leader节点日志的总长度,而Follwer节点的日志数目可能不大于nextIndex,原因是可能这个follower原来可能是leader,一部分数据还没有提交,或者原来就是follower,但是有一些数据丢失,此时要使leader减少PrevLogIndex来寻找来年各个节点相同的日志。论文[5.3]
- Follwer节点的日志数目比Leader节点记录的NextIndex多,则说明存在冲突,则保留PrevLogIndex前面的日志,在尾部添加RPC请求中的日志项并提交日志。
- 如果RPC请求中的日志项为空,则说明该RPC请求为Heartbeat,改变当前节点状态,因为可能此节点当前还是CANDIDATE,并提交未提交的日志。
func (rf *Raft) AppendEntries(args AppendEntryArgs, reply *AppendEntryReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.currentTerm > args.Term {
reply.Success = false
reply.Term = rf.currentTerm
// 其实没必要重置时钟 因为出现一个节点收到落后于自己的Term我认为只可能在分区的时候,
// 这个时候的这个leader其实没有什么意义,但是设置了也无妨
rf.resetTimer()
return
} else {
rf.current_state = "FOLLOWER" // 改变当前状态
rf.currentTerm = args.Term // 落后于leader的时候更新Term
rf.votedFor = -1 // 更新voteFor 否则在下一轮选举中可能出现两个Leader,在选举的时候初始化也可以
reply.Term = rf.currentTerm
if args.PrevLogIndex >= 0 && // 首先leader有日志
(len(rf.logs)-1 < args.PrevLogIndex || // 此节点日志小于leader 也就是说下一行数组不会越界 即日志一定大于等于PrevLogIndex
rf.logs[args.PrevLogIndex].Term != args.PrevLogTerm) { // 或者在相同index上日志不同
reply.CommitIndex = len(rf.logs) - 1
if reply.CommitIndex > args.PrevLogIndex {
reply.CommitIndex = args.PrevLogIndex //多出的日志一定会被舍弃掉 要和leader同步
}
for reply.CommitIndex >= 0 {
if rf.logs[reply.CommitIndex].Term != args.Term {
reply.CommitIndex--
} else {
break
}
}
//返回false说明要此节点日志并没有更上leader,或者有多余或者不一样的地方
//出现的原因是这个节点以前可能是leader,在一些日志并没有提交之前就宕机了
reply.Success = false
} else if args.Entries == nil { // 心跳包 用于更新状态
if rf.lastApplied+1 <= args.LeaderCommit { //TODO len(rf.logs)-1 改为 rf.lastApplied+1
rf.commitIndex = args.LeaderCommit
go rf.commitLogs() // 可能提交的日志落后与leader 同步一下日志
}
reply.CommitIndex = len(rf.logs) - 1
reply.Success = true
} else { //日志项不为空 与leader同步日志
rf.logs = rf.logs[:args.PrevLogIndex+1] // debug: 第一次调用PrevLogIndex为-1
rf.logs = append(rf.logs, args.Entries...)
if rf.lastApplied+1 <= args.LeaderCommit {
rf.commitIndex = args.LeaderCommit // 与leader同步信息
go rf.commitLogs()
}
// 如果 leaderCommit > commitIndex,令 commitIndex 等于 leaderCommit 和 新日志条目索引值中较小的一个
reply.CommitIndex = len(rf.logs) - 1
if args.LeaderCommit > rf.commitIndex{
if(args.LeaderCommit < len(rf.logs) - 1){
reply.CommitIndex = args.LeaderCommit
}
}
reply.Success = true
}
rf.resetTimer() // 很重要
}
}
然后是处理心跳包返回值的函数handleAppendEntries,以下为处理逻辑:
- 如果返回值中的Term大于leader的Term,证明出现了分区,节点状态转换为follower。
- 如果RPC成功的话更新leader对于各个服务器的状态。
- 如果RPC失败的话证明两边日志不一样,使用前面提到的reply。CommitIndex作为nextIndex,用于请求参数中的PrevLogIndex。
func (rf *Raft) handleAppendEntries(server int, reply AppendEntryReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.current_state != "LEADER" {
//log.Fatal("Error in handleAppendEntries, receive a heartbeat reply, but not a leader.")
return
}
if reply.Term > rf.currentTerm { // 出现网络分区 这是一个落后的leader
rf.current_state = "FOLLOWER"
rf.currentTerm = reply.Term
rf.votedFor = -1
rf.resetTimer()
return
}
if reply.Success {
rf.nextIndex[server] = reply.CommitIndex + 1 //CommitIndex为对端确定两边相同的index 加上1就是下一个需要发送的日志
rf.matchIndex[server] = reply.CommitIndex
if rf.nextIndex[server] > len(rf.logs){ //debug
rf.nextIndex[server] = len(rf.logs)
rf.matchIndex[server] = rf.nextIndex[server] - 1
//log.Fatal("ERROR : rf.nextIndex[server] > len(rf.logs)\n")
}
commit_count := 1
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
// 这里可以和其他服务器比较matchIndex 当到大多数的时候就可以提交这个值
if rf.matchIndex[i] >= rf.matchIndex[server] { //matchIndex 对于每一个服务器,已经复制给他的日志的最高索引值
commit_count++
}
}
if commit_count >= len(rf.peers)/2+1 &&
rf.commitIndex < rf.matchIndex[server] && //保证幂等性 即同一条日志正常只会commit一次
rf.logs[rf.matchIndex[server]].Term == rf.currentTerm{
rf.commitIndex = rf.matchIndex[server]
go rf.commitLogs() //提交日志 下次心跳的时候会提交follower中的日志
}
} else {
//rf.nextIndex[server] = int(math.Min(float64(reply.CommitIndex + 1),float64(len(rf.logs)-1)))
rf.nextIndex[server] = reply.CommitIndex + 1
if rf.nextIndex[server] > len(rf.logs){ //debug
rf.nextIndex[server] = len(rf.logs)
//log.Fatal("ERROR : rf.nextIndex[server] > len(rf.logs)\n")
}
rf.SendAppendEntriesToAllFollwer() //TODO 发送心跳包 其实发送单个人即可 有问题后面再改 先用已有函数
}
rf.resetTimer() // TODO 很重要 要不后面不发心跳包 导致不停的选举 Term往上飙
}
然后就是提交日志,刚开始的时候其实比较懵逼,当我们去查看测试代码中的start1的时候我们会发现这里面对每一个Raft节点都会跑一个goroutine,里面有一个channel,不停的往cfg.logs里面写日志,而在检查已提交日志的时候就在cfg.logs里面检查,所以提交日志其实就是往每个raft节点初始化的时候传入的那个channel里面写数据就可以了。所以提交日志的过程不难:
func (rf *Raft) commitLogs() {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.commitIndex > len(rf.logs)-1 {
log.Fatal("出现错误 : raft.go commitlogs()")
}
// 初始化是-1
for i := rf.lastApplied + 1; i <= rf.commitIndex; i++ { //commit日志到与Leader相同
// listen to messages from Raft indicating newly committed messages.
// 调用过程才test_test.go -> start1函数中
// 很重要的是要index要加1 因为计算的过程start返回的下标不是以0开始的
rf.applyCh <- ApplyMsg{Index: i + 1, Command: rf.logs[i].Command}
}
rf.lastApplied = rf.commitIndex
}
最后附上我们的start函数
func (rf *Raft) Start(command interface{}) (int, int, bool) {
index := -1
term := -1
isLeader := false
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.current_state != "LEADER"{ // 不是leader拒绝即可 测试代码用这个判断哪一个节点是leader
return index, term ,isLeader
}
nlog := LogEntry{command, rf.currentTerm}
isLeader = (rf.current_state == "LEADER")
rf.logs = append(rf.logs, nlog) // 提交一个命令其实就是向日志里面添加一项 在心跳包的时候同步
//fmt.Printf("leader append log [leader=%d], [term=%d], [command=%v]\n",
//rf.me, rf.currentTerm, command)
index = len(rf.logs)
term = rf.currentTerm
return index, term, isLeader
}
这样,lab2 PartB就完成了,下面是过了测试的图示:
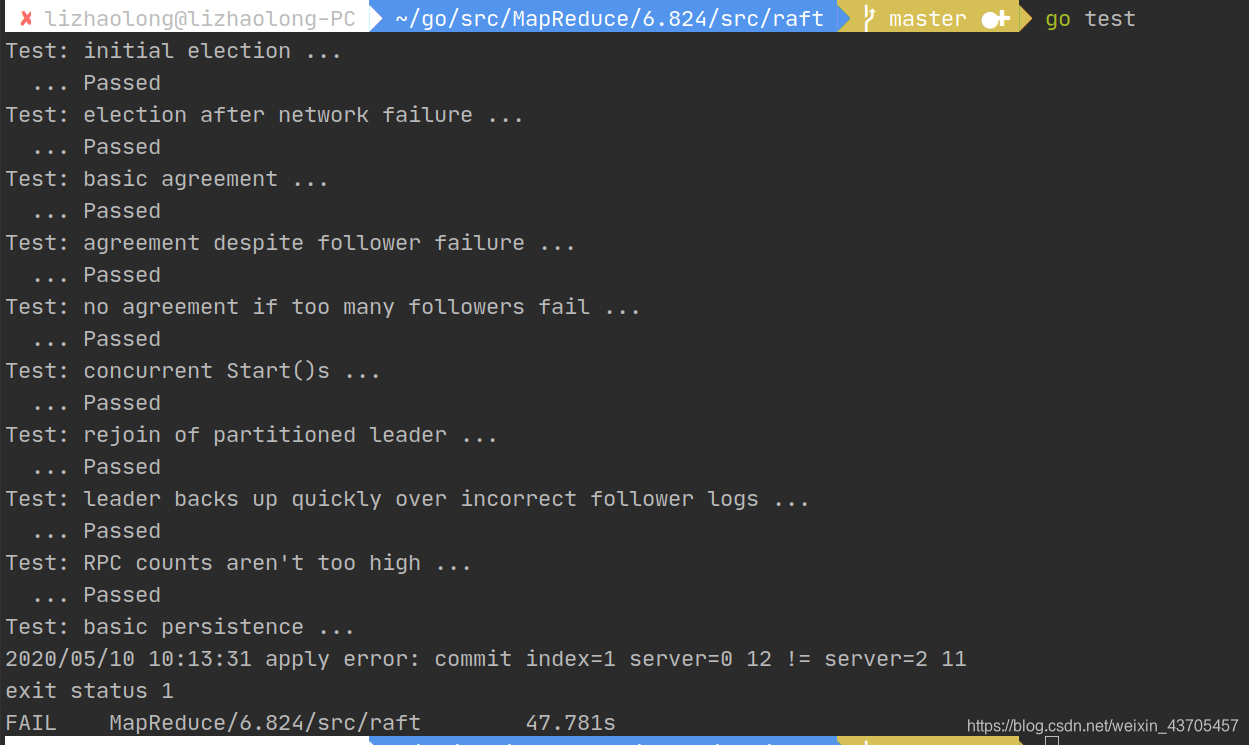
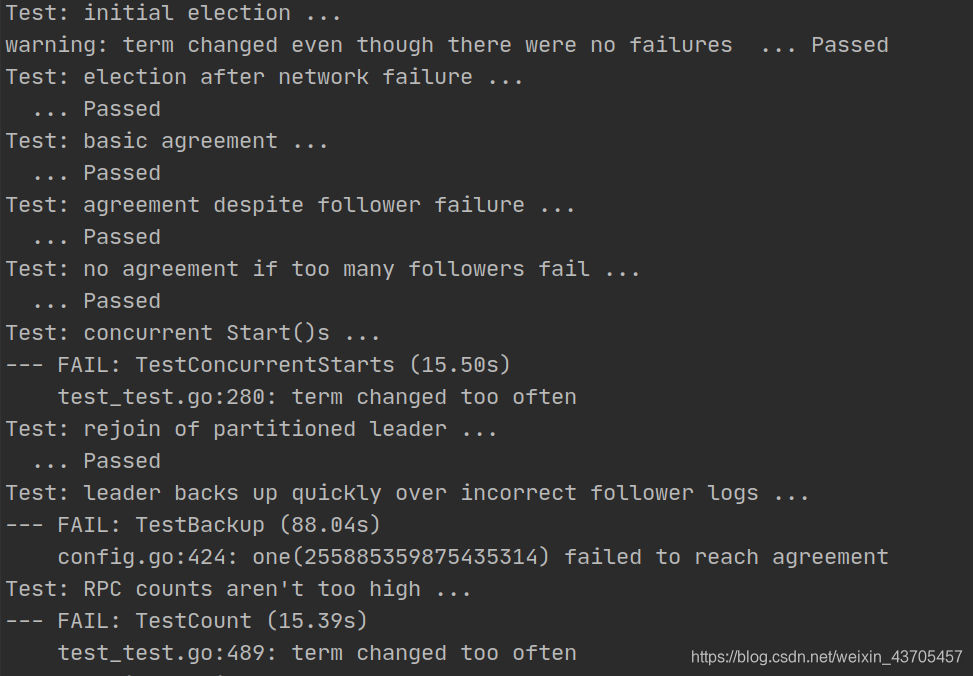
在这之前,经历了不少的失败,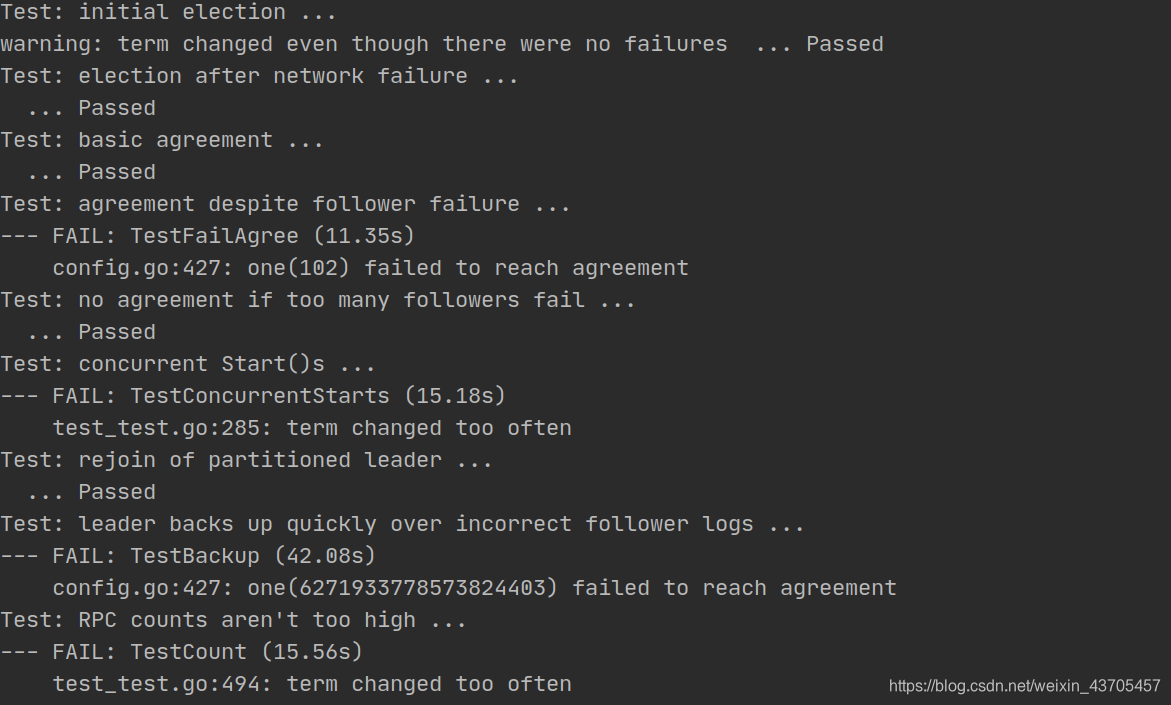
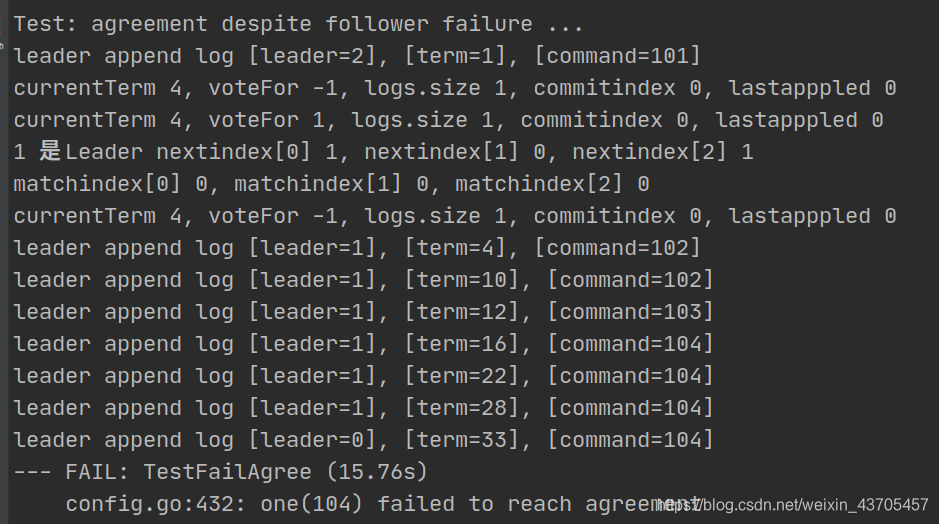
总结
对于Lab2来说,当出现bug的时候可以说唯一的方法就是把想测试的样例以外的测试函数都注释,然后加日志,一点一点分析,完成以后还是很开心的,但是也有一点累,因为分布式的代码实在是太难排错了,比C++还难。其实最后版本也可能还是有问题的,因为测试代码中是有随机性的,所以后面有心的话可以在修改下代码。现在也才知道为什么这门课开始选择C++,后来改为Go了。快开学了,开学前不想再像这样一样费脑子了,已经两天没看海贼王,而且今天还是母亲节,明天就不碰电脑了,休息一下,后天再写PartC吧,好在看起来C并不难。附上全部的代码链接。
参考:
- [1] 《Raft动画演示》
- [2] 《MIT-6.824-lab2-raft(实验内容+测试用例讲解)》
- [3] 《论文翻译》