引言
2020年4月23日,这本该是美好的一天,美妙的心情,美妙的天气,美妙的清晨的第一缕阳光.本着这么好的天气不划水白不划的心态,遂打算早上试玩一下Hadoop,然后下午出去放松一下.那时的我肯定不会想到这是如此棘手的一件事情(太菜),以至于到下午七点左右才算是真正的执行了一个伪分布式的样例.
事实上我在昨天晚上简单的看完MapReduce相关的内容以后就想尝试一下,然后就从github尝试把代码拉下来,然后竟然出现了文件结束符的错误使得一晚上都没有成功(无图有真相,当时并没有截图),遂作罢,然后把这点事情放在了今天早上,想着速度搞完收工.然后就出现了以下这一系列x疼的事情.还好最后成功了.

下载
在真正的碰Hadoop之前我们首先需要安装一些配置.即SSH和JAVA环境.
sudo apt-get install openssh-server
ssh localhost
因为后面的步骤需要输入密码,所以嫌麻烦的朋友可以配置下SSH免密登录,执行以下操作即可:
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa #会有提示,都按回车就可以,这一步是生成秘钥,出现的那个奇怪的长方形就是
cat ./id_rsa.pub >> ./authorized_keys
这样我们再登录就不必再输入密码了.
至于JAVA环境不必多说,网上的教程很多,这一步我们要做的就是在环境变量中加入JAVA_HOME,这一步非常重要,后面有两个错误都会出在这里,首先抛出一个通用解决方案,后面说最终解决方案.
我们需要在~/.bashrc中加入以下语句:
export JAVA_HOME=JDK安装路径

然后执行如下命令使得配置生效:
source ~/.bashrc
然后我们执行echo $JAVA_HOME就可以看到我们的设置了.这里我们上面说到的两个问题就是:
- JDK12在执行时会出现一个反射问题,最后使用JDK8解决问题.
- 哪怕这里配置了环境变量后面在配置伪分布式的时候还是会出现找不到环境变量的问题.
以上两个问题后面会说.到了这里,我们的准备工作就完成了,然后准备下载一个Hadoop.首先开始的时候我把github上的代码拉下来准备开始尝试,但是当我进入readme中的所展示的网址也即是http://hadoop.apache.org以后发现样例中所展示的所有目录在我拉下来的代码中一概不存在,这就尴尬了,对于一个阳光可爱的男孩来说这实在是有点头凉.后来找到了这个下载地址,也希望后来的朋友们不要走弯路.传送门.
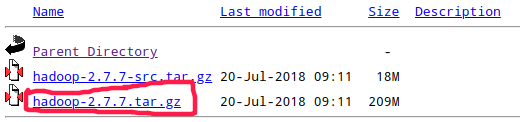
进入以后点击红框内的选项即可.
然后我们需要解压这个压缩包到我们想要的地方,我因为是随便玩玩,就放在了桌面:
sudo tar -zxf ~/Download/hadoop-2.7.7.tar.gz -C /Desktop/Hadoop
cd /Desktop/Hadoop
sudo mv ./hadoop-2.7.7/ ./hadoop
执行如下命令可以看看我们的操作是否可用:
cd /Desktop/Hadoop/hadoop
./bin/hadoop version

这样就是OK啦!
单机配置
Hadoop自带了很多有意思的小例子,这些在单机模式下不需要任何配置也能跑起来.我们只需要运行这个语句./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar就可以看到所有的小例子:
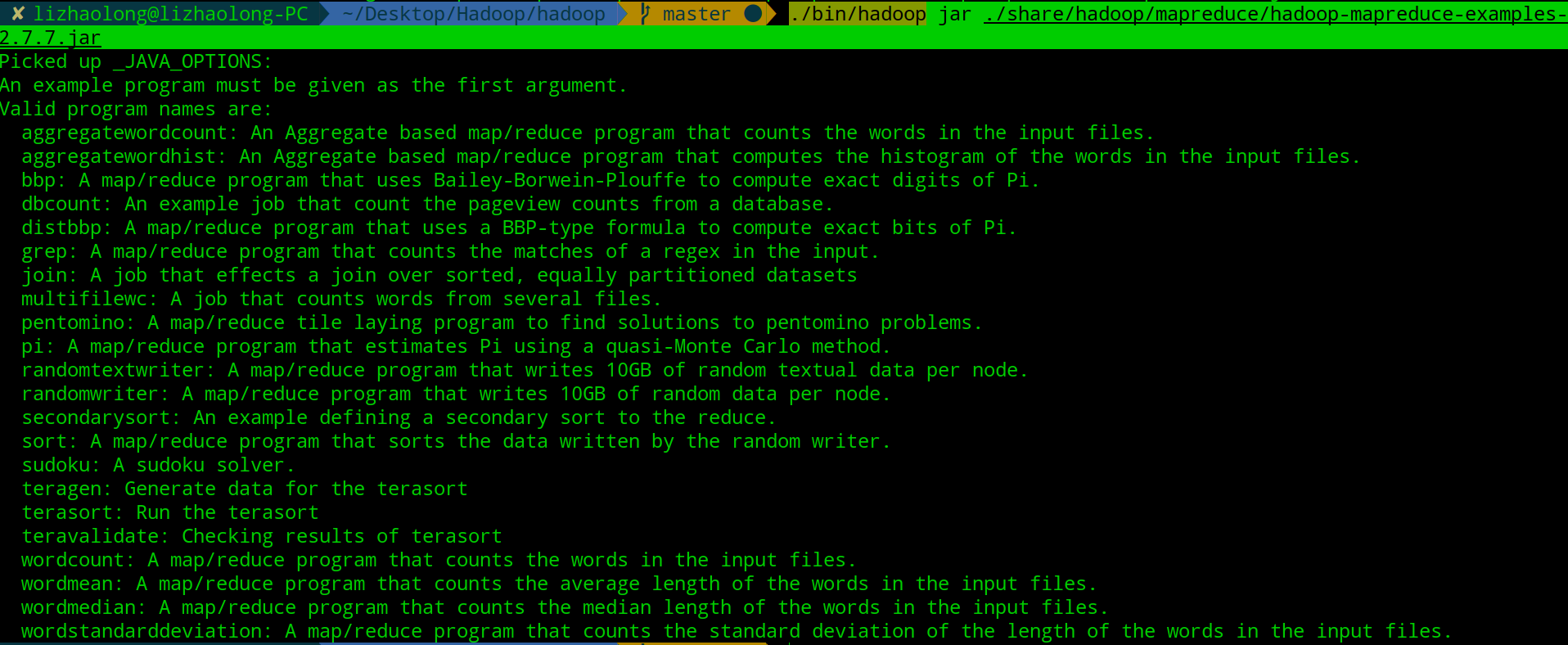
我们来简单的运行一个wordcount的样例,正如上图中所说,这是一个MapReduce程序,所以我们需要指定一个输入,这里我们指定为input,具体操作如下:
cd Desktop/Hadoop/hadoop # 进入Hadoop目录
mkdir input # 创建输入
cp ./etc/hadoop/.xml ./input # 把配置文件当做输入
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-.jar wordcount ./input ./output // 运行一个mapreduce程序
cat ./output/* // 这是我们的结果目录
然后就成了,重点在后面.
伪分布式配置
伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml,配置方式如下:
core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/lizhaolong/Desktop/Hadoop/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9001</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/lizhaolong/Desktop/Hadoop/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/lizhaolong/Desktop/Hadoop/hadoop/tmp/dfs/data</value>
</property>
</configuration>
这里伪分布式其实只需要配置 fs.defaultFS 和 dfs.replication 就可以运行,但是会默认使用临时目录/tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行,这样就可能会在后面的执行中出现NameNode失败的情况,所以这里指定一个tmp文件.然后我们执行Namenode初始化:
./bin/hdfs namenode -format

这样就算是初始化成功了.
然后就是最重要的一步,开启NameNode和DataNode守护进程,即执行:
./sbin/start-dfs.sh
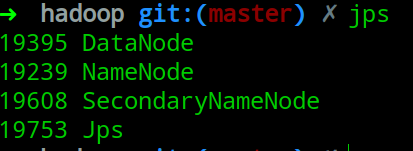
最友好的情况就是这样:

也就是三个节点全部成功,一个Namenode,一个Namenode备份,一个DataNode(知识点见MapReduce),这时我们执行jps命令,可以看到如下:
但显然事情不会这么容易,这里我一共遇到了六处错误:
- 找不到JAVA_NAME
- Permission denied (publickey,gssapi-keyex).
- Permission denied, please try again.错误。
- The authenticity of host 192.168.0.xxx can’t be established
- 执行./sbin/start-dfs.sh出现反射错误.(解决方案为切换JDK版本)
- Namenode启动失败.
对于第一个问题你可能会奇怪,明明前面配置过了,为什么这里还会出现问题,解决的方法就是去配置etc/hadoop/hadoop-env.sh.

第五个问题出现样例是这样的,就是前面出现的WARNING.但是问题的原因我在网上并没有查到,这是在看到另一个博主在切换JDK版本后解决问题然后才解决的:

第六的问题就是在执行jps以后发现没有出现Namenode,这会导致后面的操作全部失败,而这个问题出现的原因千奇百怪,如果像我一样一头钻到网上寻找解决方案你大概率会一筹莫展,这里解决的最好的方法就是看日志,惭愧的是刚开始我并没有意识到这一点.在hadoop的主目录中我们就可以看到logs这个目录,打开以后是这样的(我们应该不一样):
 然后分析
然后分析hadoop-root-namenode-lizhaolong-PC.log,你也许会说,这么大的日志,这么看?先别急着抱怨,我们暂且不谈Linux下的批处理工具,一般Namenode启动失败一定是ERROR级别日志,所以我们只需要grep一下就可以了.

看着这重启的次数你就知道我经历了什么.
然后我们去日志里找错误原因:


这就是我出现这个问题的原因,我开始使用的端口是9000,在ss -tanl以后我发现9000我其实用做了其他的事情,至此这个问题也算是解决了.在core-site.xml改下端口就好了.这件事情告诉我们日志是一个非常重要的事情.
还有三个问题,在参考中我列了出来,有需要的朋友可以点击阅读.
然后就是运行这伪为分布式的实例,
./bin/hdfs dfs -mkdir -p /user/hadoop // 在HDFS中创建一个文件夹
./bin/hdfs dfs -mkdir /user/hadoop/input // 创建一个文件
./bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input // 把一系列配置文件作为输入
./bin/hdfs dfs -ls /user/hadoop/input
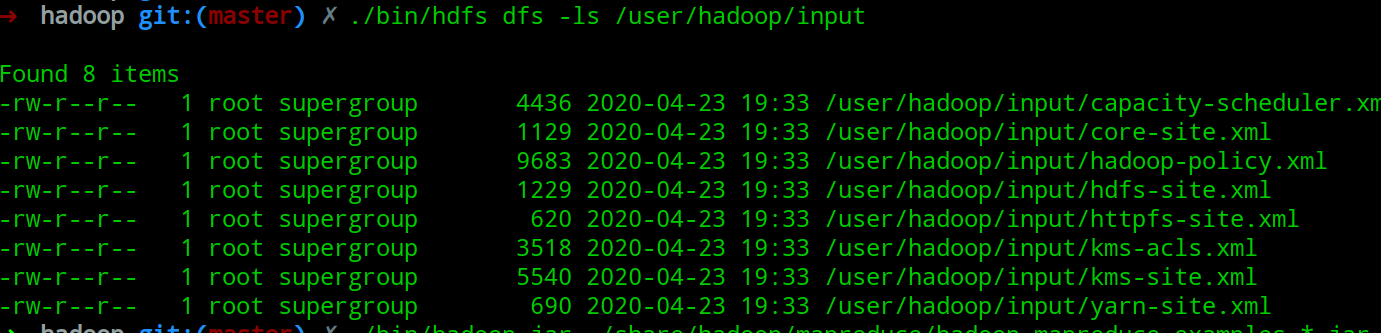
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /user/hadoop/input /user/hadoop/output '[a-z.]+' // 执行mapreduce程序
以上是执行过程的一部分.
我们来看看结果:
./bin/hdfs dfs -ls /user/hadoop/output

这里展示一部分输出:

当然,现在的输出还是在HDFS中存在,我们也可以把这个值拿出来,如下:
$ rm -r ./output # 先删除本地的 output 文件夹(如果存在)
$ ./bin/hdfs dfs -get /user/hadoop/output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
$ cat ./output/*
这里很重要的一点就是Hadoop中ouput文件不能重名,这里的文件名需要我们保证不相同,否则会出现错误.
如果我们想要在执行一次获取相同的结果,则需要:
./bin/hdfs dfs -rm -r output
为什么要这样,其实很好理解,因为真正使用没有像我们这样的使用的,一般来说Hadoop存储在文件中的值要么是一个大任务中的一个重要MapReduce的输出值,要么是一个任务(多个MapReduce组成)的返回值,我们当然不希望值被无声无息的覆盖.
以上.
总结
Hadoop确实是一个很有意思的东西,其对大数据的处理方法确实非常值得一谈,这也是为什么十几年前这东西这么火的原因,但是看过MapReduce论文和DDIA的都知道这个玩意的各个特性确实很适合谷歌,但是不一定完美适合于其他公司,所以我相信各大公司一定有各种这个东西的闭源版本,当然也有很多开源的针对不同场景的优化版本.话虽如此,但是它的设计理念仍值得我们学习,HDFS和MapReduce产生的剧烈反应实在是让人觉得精美,它向上层完美的隐藏了下层的复杂逻辑,单从这个角度它就非常成功.更不必说其借鉴的Unix的设计哲学.总之还是那一句话,学无止境,保持一颗上进于敬畏之心才可.
参考:
- 博文《好记心不如烂笔头,ssh登录 The authenticity of host 192.168.0.xxx can’t be established. 的问题》
- 博文《启动hadoop时报root@localhost’s password: localhost: Permission denied, please try again.错误。》
- 博文《普通用户ssh免密登陆完美解决(Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password))》
- 博文《启动hadoop,报错Error JAVA_HOME is not set and could not be found》
- 博文《Mac下Hadoop伪分布式安装及出现的问题(JDK版本,Hadoop本地库编译)》
- 博文《Ubuntu 16.04上安装Hadoop并成功运行》