1.问题
多个进程对同一个文件进行访问会使得写入的数据出现错乱吗,write与fwrite之间到底有什么区别呢,哪种情况会丢掉数据呢.
2.结论
- 多个进程写同一个文件不会出现数据交叉的情况
- 在多进程使用write时不会丢掉数据, fwrite会丢掉数据
- fwrite速度优于write
3.实验
write版本
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
#include<fcntl.h>
#include<sys/stat.h>
#include<time.h>
int main(){
pid_t pid;
pid = fork();
char* pathname = "test.txt";
char* ChildProcess = "aaaaa\n";
char* FatherProcess = "bbbbb\n";
switch (pid)
{
case 0:
{
printf("in the child\n");
int fd = open(pathname, O_RDWR | O_APPEND);
for(int i=0;i<100000;++i){
write(fd, ChildProcess,6);
}
close(fd);
break;
}
case -1:
perror("error message\n");
break;
default:
{
printf("in the father\n");
int fd = open(pathname, O_RDWR | O_APPEND);
for(int i=0;i<100000;++i){
write(fd, FatherProcess, 6);
}
close(fd);
break;
}
}
return 0;
}
非常简单的一个测试代码 父子进程同时向test.txt文件写内容 我们可以看到结果是这样的,
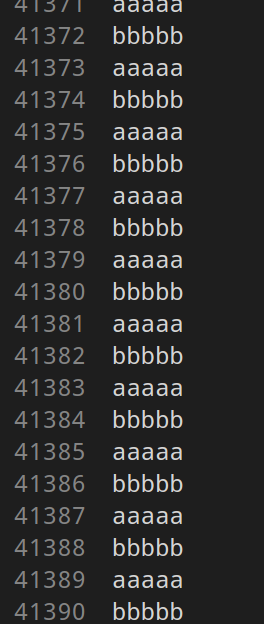

我们可以看到父子进程交替打印 且200000行没有丢失数据
如果改为fwrite呢 我们来看看下面的测试代码
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
#include<fcntl.h>
#include<sys/stat.h>
int main(){
pid_t pid;
pid = fork();
char* pathname = "test.txt";
char ChildProcess[7] = "aaaaa\n";
char FatherProcess[7] = "bbbbb\n";
switch (pid)
{
case 0:
{
printf("in the child\n");
FILE* fl = fopen(pathname, "rt+");
for(int i=0;i<100000;++i){
fwrite(ChildProcess, 6,1,fl);
}
fclose(fl);
break;
}
case -1:
perror("error message\n");
break;
default:
{
printf("in the father\n");
FILE* fl = fopen(pathname, "rt+");
for(int i=0;i<100000;++i){
fwrite(FatherProcess, 6,1,fl);
}
fclose(fl);
break;
}
}
return 0;
}
我们来看看打印结果
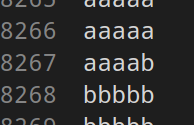

我们可以发现 出现了数据交叉 且不止一处出现了数据交叉 而且数据只有一半,有十万行数据丢失了,
对比一下时间 也非常的令人震惊
write:

fwrite:

我们可以看到 对于相同的十万组读写 时间相差近150倍,这是一个很可怕的数据了,这是为什么呢,其实时间相差这个问题很好解释,一个write系统调用因为牵扯到磁盘的读写非常的耗时,相比与L1,L2级别的高速缓存,读取磁盘的周期数(csapp p345)为前者的几千倍!一次write意味着我们需要访问一次磁盘,且还有一次系统调用,经历内核态到用户态的转换和上下文切换,十万次的写入相当于十万次的系统调用,以及十万次的写入磁盘,而fwrite相当于write的一个封装,维护一个用户态buf,可以在内存中存储要写入磁盘的数据, 到了一定的量一次写入,一次减少读入磁盘的次数,所以时间差异如此的大.
接下来的问题是为什么多进程write写入不会出现数据交叉,而fwite会出现
关键在于O_APPEND这个参数 看一段源码
ssize_t generic_file_aio_write(struct kiocb *iocb, const char __user *buf,
size_t count, loff_t pos)
{
struct file *file = iocb->ki_filp;
struct address_space *mapping = file->f_mapping;
struct inode *inode = mapping->host;
ssize_t ret;
struct iovec local_iov = { .iov_base = (void __user *)buf,
.iov_len = count };
BUG_ON(iocb->ki_pos != pos);
down(&inode->i_sem);
ret = __generic_file_aio_write_nolock(iocb, &local_iov, 1,
&iocb->ki_pos);
up(&inode->i_sem);
if (ret > 0 && ((file->f_flags & O_SYNC) || IS_SYNC(inode))) {
ssize_t err;
err = sync_page_range(inode, mapping, pos, ret);
if (err < 0)
ret = err;
}
return ret;
}
inline int generic_write_checks(struct file *file, loff_t *pos, size_t *count, int isblk)
{
struct inode *inode = file->f_mapping->host;
unsigned long limit = current->signal->rlim[RLIMIT_FSIZE].rlim_cur;
if (unlikely(*pos < 0))
return -EINVAL;
if (unlikely(file->f_error)) {
int err = file->f_error;
file->f_error = 0;
return err;
}
if (!isblk) {
/* FIXME: this is for backwards compatibility with 2.4 */
if (file->f_flags & O_APPEND)
*pos = i_size_read(inode);
if (limit != RLIM_INFINITY) {
if (*pos >= limit) {
send_sig(SIGXFSZ, current, 0);
return -EFBIG;
}
if (*count > limit - (typeof(limit))*pos) {
*count = limit - (typeof(limit))*pos;
}
}
.......................
}
generic_write_checks由__generic_file_aio_write_nolock调用
我们可以看到当检测到mode为有O_APPEND时 就是把偏移量调整到当前数据的长度 而这个操作是加锁的(信号量) 意味着写入操作是原子性的,所以直接write数据不会丢失,还是20万行,但是fwrite操作只输出十万行,这个现在确实没办法解释,了解的朋友希望能在评论区留下宝贵的指导
send与recv也是原子操作 意味着我们对套接字的操作也是多进程或多线程操作的
https://stackoverflow.com/questions/1981372/are-parallel-calls-to-send-recv-on-the-same-socket-valid
本人水平有限,错误之处请指正
参考
https://blog.csdn.net/yangbodong22011/article/details/63064166
https://blog.csdn.net/zhangyifei216/article/details/76653746