学习汇编语言是为了对计算机的工作原理和计算机操作系统有更深入的认识。日后能够站在计算机CPU的角度编写程序。
我学习汇编语言选用的教材是王爽老师的《汇编语言》。
下面总结一下这两天所学到的知识,也是复习计算机导论所学过的知识。
机器语言与汇编语言
机器语言是比汇编语言更底层的语言,也就是计算机直接识别的01语言,机器语言是机器指令的集合。
机器语言由于只有0和1,记忆困难、书写困难、检查困难,设想一下如果在编写的上百行程序中有一个0错误的写成了1,这样后续的检查是十分麻烦的。为了解决这些问题,就有了汇编语言的产生。
汇编语言的主体是汇编指令,汇编指令用规定的方式来表示相应机器指令。相较于机器指令汇编指令更便于记忆。下边引用《汇编语言》中的一个例子:
操作:寄存器BX的内容送到AX中
机器指令:1000100111011000
汇编指令:mov ax,bx
指令和数据
指令和数据是应用上的概念。在内存或磁盘上指令和数据没有任何区别,都是二进制信息。例如
1000100111011000 ->89D8H(数据)
1000100111011000->mov ax,bx(程序)
可以把上述01代码当做是数据也可以当做是程序,人如何区分是数据还是程序就要看程序员是如何引用的了。计算机中对代码的区分就要依靠总线。
CPU对存储器的读写
CPU要进行数据的读写,必须要有三类信息交互
- 存储单元的地址(地址信息)
- 器件的选择,读或写命令(控制信息)
- 读或写的数据(数据信息)
CPU要将地址、数据、控制信息传到芯片中,就要依靠总线。从逻辑上,总线分为地址总线(A)、数据总线(D)、控制总线(C)。
- 地址总线决定了CPU的寻址能力
- 数据总线的宽度体现系统总体性能的关键因素之一
- 控制总线的宽度决定了CPU对外部器件的控制能力。
寄存器(CPU工作原理)
寄存器对汇编是一个很重要的概念。“程序员通过改变各种寄存器中的内容来实现对CPU的控制”。这里我们讨论的是8086CPU相关的寄存器。
8086CPU共有14个寄存器,其中8个通用寄存器、2个控制寄存器、4个段寄存器。这些寄存器的表示:AX、BX、CX、DX、SI、DI、SP、BP、IP、CS、SS、DS、ES、PSW。
AX—累加器(Accumulator)
BX—基址寄存器(Base register)
CX—技术寄存器(Count register)
DX—数据寄存器(Date register)
SP—堆栈指示器(Stack Point)
BP—基址指示器(Base Point)
SI—源变址寄存器(Source Index)
DI—目的变址寄存器(Destination Index)
IP—指令指示器(Instruction Point)
F(PSW)—状态标识寄存器(Status Flags)
CS—代码段寄存器(Code Segment)
DS—数据段寄存器(Date Segment)
SS—堆栈段寄存器(Stack Segment)
ES—附加段寄存器(Eextra Segment)
通用寄存器
在8086CPU中寄存器都是16位的,也就是两个字节。通用寄存器指的是上述寄存器中的:AX、BX、CX、DX、SP、BP、SI、DI。
在通用寄存器中AX、BX、CX、DX由高8位和低8位之分,这样是为了让8086CPU向下具有继承性,当程序员想要使用8位来编程时8086CPU也是支持的。下面以AX寄存器为例。
如下图所示,AX寄存器共有16位,高8位为AH,低8位为AL。
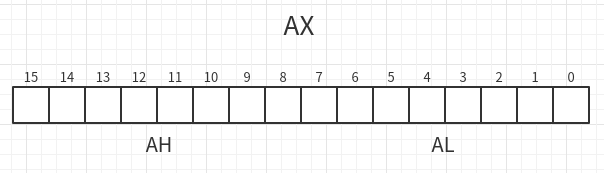
AH、AL是两个独立的8位寄存器。与AX相同,BX、CX、DX也有高8位和低8位之分。下面举几个例子来体会这个独立。(H表示16进制)
mov ax,62627 AX = F4A3H
mov ah,31H AX = 31A3H
mov al,23H AX = 3123H
add ax,ax AX = 6246H
mov bx,826CH BX = 826CH
mov cx,ax CX =6246H
mov ax,bx AX = 826CH
mov al,bh AX = 8282H
mov ah,bl AX = 6C82H
add ah,ah AX = D882H
add al,6 AX = D888H
*add al,al AX = D810H
mov ax,cx AX = 6246H
上面有*号的特别关注一下,al与al相加后的值为110,但由于只用到了低8位,所以前面的1就被省略掉。在数据传送时要注意数位相同,例如下面几条指令就是错误的
mov ax,bl --- 在8位寄存器和16位寄存器之间传送数据
mov bh,ax --- 在16为寄存器和8位寄存器之间传送数据
mov al,20000 --- 8位寄存器最大可存放值为255
add al,100H --- 讲一个高于8位的数据加到一个8位寄存器中
物理地址
这一块引用《汇编语言》的内容,我们知道,CPU访问内存单元时,要给出内存单元的地址。所有的内存单元构成的存储空间是一个一维的线性空间,每一个内存单元在这个空间中都有唯一的地址,我们将这个唯一的地址称为物理地址。
CPU通过地址总线存储器的,必须是一个内存单元的物理地址。在CPU向地址总线上发送物理地址之前,必须要在内部先形成这个物理地址。不同的CPU可以有不同的形成物理地址的方式。
下面要进行的就是CPU内部如何形成这个物理地址
这里说明一下16位CPU是指在CPU内部,处理、传输、暂时存储的信息的最大长度是16位的。
我的理解为CPU的控制器、寄存器、运算器都是16位的。
8086CPU给出物理地址的方法
8086CPU的地址总线为20位,可以传输20位的地址,但8086CPU是16位的CPU。这说明直接CPU处理只有64K,而总线的寻址能力为1M,这样显然是由很大的浪费。
8086CPU给出的解决方案是:采用两个16位地址合成一个20位的物理地址。

如图所示:
①CPU提供两个地址,一个是段地址,一个是偏移地址。
②两个地址通过内部总线到地址加法器,合成一个20位的物理地址
③物理地址通过内部总线到输入输出控制电路,再通过外部总线进行寻址。
地址加法器的工作原理:物理地址 = 段地址 × 16 + 偏移地址

段地址 ×16 相当于左移4位,这样16位的地址就变成了20位。
我对 段地址×16+偏移地址 的理解:
×16 是为了让16位的地址变成20位,这样就增强了CPU的寻址能力。然后在看这个方法本身是怎样寻址的,段地址×16像是C语言中的指针,偏移地址是使用指针时后面所加的偏移量。
例如C语言中*ptr = &information; 当我们想要知道information中的各种信息时就要ptr+(number),这样就得到我们想要的地址。段地址×16就相当于指定一个首地址,通过偏移地址去具体的寻找该段的具体地址。
段寄存器
段地址在8086CPU的段寄存器中存放。8086CPU有4个段寄存器:CS、DS、SS、ES。这里重点讨论的是CS。
CS 和 IP
这两个寄存器确定了CPU当前要读取的指令的地址。CS为代码段寄存器,IP为指令指针寄存器。

如上图所示,观察CS 和 IP的值,然后再观察右下角的值。可以看到左下角的值对应的就是CS和IP的值。这里先说明左下角的值确定CPU要执行的指令的地址,后面是指令的机器码,在后面就是汇编指令。由此可以看出CS和IP寄存器的重要性,至于所用到的debug命令,后面会进行说明。
8086CPU从CS×16+IP的内存单元开始,读取指令并执行。CS×16+IP可以表示为CS:IP。
修改CS、IP的指令
程序员可以通过改变CS、IP的内容,来控制CPU执行目标指令。
修改CS、IP的值通过jmp指令。改变CS、IP的值不能使用mov指令,因为8086CPU没有提供这样的功能。
语法如下:
jmp 段地址 : 偏移地址
jmp 1000:0 执行后:CS = 1000, IP = 0,CPU将从10000处读取指令
如果只想修改IP的值,可以这样使用:
jmp 某一合法寄存器
jmp ax,执行指令前:ax = 1000, cs = 1000, ip = 0
执行指令后:ax = 1000, cs = 1000, ip = 1000
代码段
在编程时,将代码存储在一个代码段中,要执行时就找到这个代码段运行。
举一个例子:
mov ax,1000
add ax,0123
mov bx,ax
jmp bx
这段长度为10个字节的指令,存放在10000H~10009H一组内存单元中,可以认为10000H~10009H这段内存是用来存放代码的,是一个代码段,它的段地址为1000,长度为10字节。
10字节是通过它们的机器码确定的。
《汇编语言》中在这章后面有一个实验,这里就不赘述。很推荐做一下这里的实验,对所学的知识有更深的理解。
我遇到的问题:我使用的是 Linux 环境,无法使用 dos 环境。
我的解决方案:下载 dosemu
这里推荐一片博文,里面提供的工具很全面:
Linux下学习王爽老师的汇编语言