排序算法详解(一)
1.冒泡排序
基本原理:冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的末尾
1.1 算法描述
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最 后的元素应该会是最大的数;
- 针对所有的元素重复以上的步骤,除了最后一个;
- 重复步骤1~3,直到排序完成。
1.2 算法图画
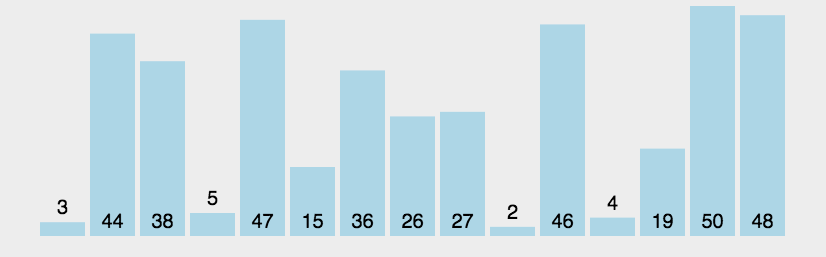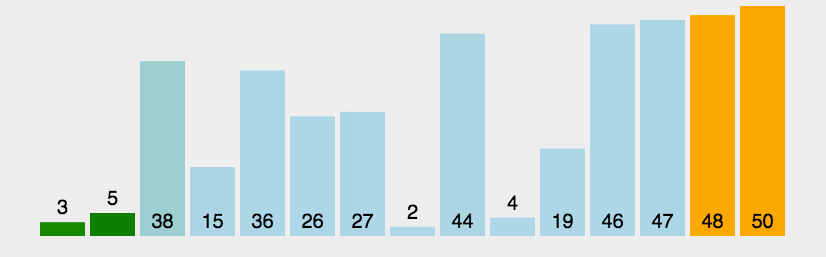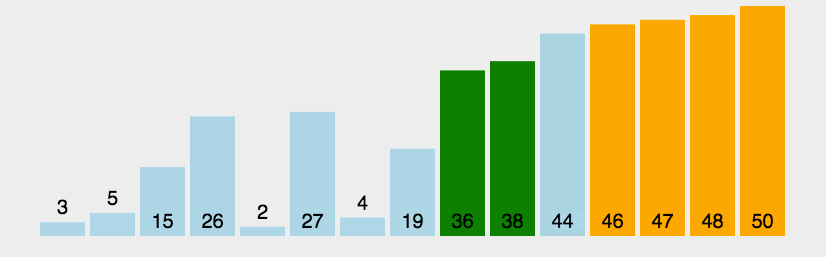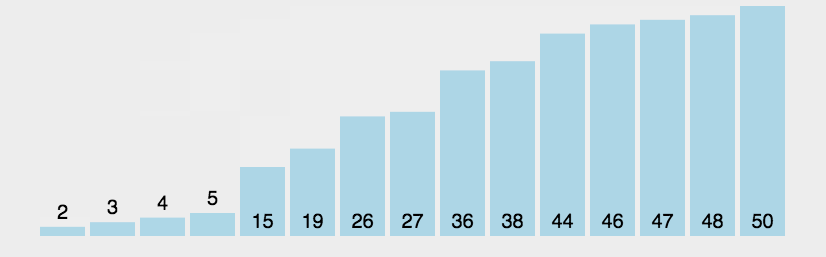 1.3 代码详解
1.3 代码详解
#include<stdio.h>
int main()
{
int i, j, t, n,;
int a[100];
//输入数字
printf("请输入数字个数:\n");
scanf("%d", &n);
for (i = 0; i <= n - 1; i++)
{
printf("请输入数字:");
scanf("%d", &a[i]);
}
//核心函数
for (i = 0; i <= n - 1; i++)// 循环次数
{
for (j = 0; j <= n - i; j++)// 具体内部对应的每个数
{
if (a[j] < a[j + 1])//比较前后两个数的大小,如果不满足大小关系,进行交换。
{
t = a[j];
a[j] = a[j + 1];
a[j + 1] =t;
}
}
}
//按顺序输出数字
for (i = 0; i <= n - 1; i++)
{
printf("%d ", a[i]);
}
return 0;
}
冒泡排序优化:
首先传统的冒泡排序的时间复杂度较高,高达O(n2),也就是说,计算机在运行这个算法的时候消耗的时间是比较长的。而导致运行时间长的原因是:在冒泡排序中,一个元素需要和它之后的每个元素比较,即使这个元素的值一定不会发生交换(即元素的值一定小于(或大于)它之后的值,所以我们可以从这里进行优化。
代码优化:
#include<stdio.h>
int main()
{
int i, j, t, n,b;
int a[100];
//输入数字
printf("请输入数字个数:\n");
scanf("%d", &n);//
for (i = 0; i <= n - 1; i++)
{
b=1;//
printf("请输入数字:");
scanf("%d", &a[i]);
}
//核心函数
for (i = 0; i <= n - 1; i++)// 循环次数
{
for (j = 0; j <= n - i; j++)// 具体内部对应的每个数
{
if (a[j] < a[j + 1])//比较前后两个数的大小,如果不满足大小关系,进行交换。
{
t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
b=0;
}
}
if(b)
break;//如果b=1,则为真,即交换数据;如果b=0;则为假,即已交换数据。
}
//按顺序输出数字
for (i = 0; i <= n - 1; i++)
{
printf("%d ", a[i]);
}
return 0;
}
相比之前的冒泡排序,这次修改之后,如果判断两个数没有进行修改,即后面的数一定大于比较值时,直接跳出循环,不需要做无用功。