应该之后开始每天记录一点,不然这些笔记过段时间都不知道放哪了。
-
fork 和vfork 的区别在于vfork子进程共享父进程地址空间,子进程先执行,这意味着变量是共享的,子进程一边改变,父进程的变量的值也会受到影响。
-
俩进程在写同一个文件如果使用open(O_APPEND),write的系统调用的时候,父进程和子进程的调用次序不一定,写入文件中是交替的(但不会覆盖),如果使用的是fopen(“ab”),fwrite的c库函数的时候,父进程和子进程依旧调用次序不一定,但写入文件中如果数据较小,未出现交替现象,数据大起来到4096字节的时候交替给另一个进程写入。
但如果是open()+lseek(END)则会产生覆盖现象 -
、strtok_r函数
strtok_r函数是linux下分割字符串的安全函数,函数声明如下:
char *strtok_r(char *str, const char *delim, char **saveptr);
该函数也会破坏带分解字符串的完整性,但是其将剩余的字符串保存在saveptr变量中,保证了安全性。 -
当描述符0和f d共享同一文件表项 。例如,若描述符 0被只读打开,那么我们也只对 f d进
行读操作。即使系统忽略打开方式,并且下列调用成功:
fd = open("/dev/fd/0", O_RDWR);
我们仍然不能对f d进行写操作。 -
指定了O_APPEND打开文件,使用lseek到文件任意一个位置写都没有用,全会写到文件末尾。open(O_APPEND )=open()+lseek(fd,0,SEK_END)的原子操作。open(O_APPEND)需要指定O_WRONLY或者O_RDWR
-
dup(1,0)这些之间始终有着些疑问,
而且对于write(stdout,)和read(stdin,)和
write(stdin,)和read(stdout,)也是感觉很奇怪 -
#ifdef _SIZE_T
typedef _SIZE_T size_t ;
#undef _SIZE_T
这种形式的宏定义结合typedef可以让size_t在多个头文件中宏定义多次_SIZE_T都没关系 -
书上说O_TRUNC只会截断只读或者只写文件。实验证明O_TRUNC即使是可读可写文件也是会截断为0的
-
必须是本用户的程序设置u+s才可以让其他用户来通过这个程序越级访问本用户文件
-
可用通过access 来试验文件权限。
-
i节点包含了所有与文件有关的信息:文件类型、文件存取许可权位、文件长度和指向该
文件所占用的数据块的指针等等。 s t a t结构中的大多数信息都取自 i节点。只有两项数据存放在
目录项中:文件名和i节点编号数。i节点编号数的数据类型是i n o _ t。 -
目录不可以硬链接的原因:,目录非空无法删除(看rmdir,rename可知)而软链接unlink是不穿透的,因此unlink一个软链接目录可以把这个目录“副本”删除。(注:unix(我不确定linux可不可以,也不敢试)root可以硬链接目录,作者说文件系统会出问题)13. 利用宏函数会比普通函数调用快如getc,fgetc
-
fgets()用memcpy()实现,memcpy用汇编。
-
dup2(fd,1)重定向的深入理解:将fd的文件表项与1共享,原本write(fd)的内容先找到fd的文件表项,再根据当下的v节点指针(fd的)找到v节点表,写入信息。
-
stat大部分内容在v节点表,少数在文件表项,如文件名,文件的读写状态,
-
标准出错如它所应该的那样是非缓存的,而普通文件按系
统默认是全缓存的。 -
sync可用于数据库这样的应用程序,它确保修改过的块立即写到磁盘上
-
对于O_sync ,O_direct较好的理解
https://www.cnblogs.com/suzhou/p/5381738.html
这张图爱了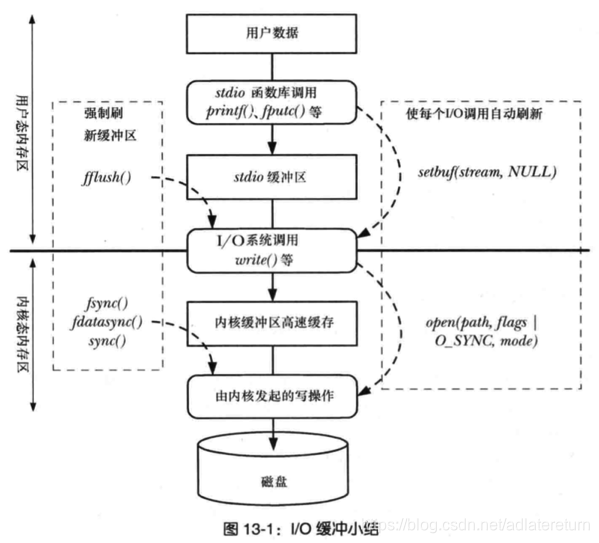
-
caltime=time(NULL);
tm=localtime(&caltime);
(strftime(line,MAXLINE,"%a %b %d %X %Z %Y\n",tm) -
atexit(void(*func)(void))类似于析构函数 -
共享库可以让可执行文件大小显著减少:共享库使得可执行文件中不再需要包含常用的库函数,而只需在所有进程都可存取的存储区中保存这种库例程的一个副本。程序第一次执行或者第一次调用某个库函数时,用动态连接方法将程序与共享库函数相连接。这减少了每个可执行文件的长度,但增加了一些运行时间开销。共享库的另一个优点是可以用库函数的新版本代替老版本而无需对使用该库的程序重新连接编辑。(假定参数的数目和类型都没有发生改变。)---->(本需要写在可执行文件里,现在放在内存中,拿过来链接就好了)缺点:变慢
-
setjmp,setlongjmp使用的过程中需要注意想像正常goto一样的数据不回滚的功能,需要让那些在过程中使用的变量施加volatile
-
子进程和父进程继续执行 f o r k之后的指令。子进程是父进程的复制品。例如,子进程获得
父进程数据空间、堆和栈的复制品。注意,这是子进程所拥有的拷贝。父、子进程并不共享这
些存储空间部分。如果正文段是只读的,则父、子进程共享正文段 (见7 . 6节)。
现在很多的实现并不做一个父进程数据段和堆的完全拷贝,因为在 f o r k之后经常跟随着
e x e c。作为替代,使用了在写时复制 ( C o p y - O n - Write, COW)的技术。这些区域由父、子进程共
享,而且内核将它们的存取许可权改变为只读的。 -
f o r k的一个特性是所有由父进程打开的描述符都被复制到子进程中。
父、子进程每个相同的打开描述符共享一个文件表项 。 -
fork甚至会把fork前父进程中标准IO如printf写缓冲区(那些是全缓存的)(如果没有fflush)的内容复制到子进程的缓存中。
-
fork 两次可以避免僵尸,前提是子先于孙死,孙则接给init而不是父。
-
setuid(500)在本程序不是root的情况下只可以500去运行的时候把有效uid改成500。
-
[对于setuid等函数的较好的实验] https://www.cnblogs.com/robbychan/archive/2013/06/05/3786945.html
-
子进程exit会刷新父进程的标准IO缓冲区,所以用_exit
-
在写myshell的过程中有个问题就是用wait(WHOHANG)实现的&究竟是不是真正的放到后台。
不是!
终端如果知道子进程在后台运行1.子进程需要向终端写数据(可以使用stty tostop禁止),可以会写出来也可能去发送SIGTTOU信号。在禁止之后呢,写数据的子进程就和从终端读数据的进程一样的会被暂停。读数据终端则发送sigsttin信号。之后呢如果需要运行则是利用fg 命令,终端向程序发送sigcont,程序在前台继续运行。可以说真正的后台就是暂停和可以拿出来继续。然而myshell实验只是让子进程和父进程同时运行了。