- 默认情况下, 不管是double, 还是float , 输出一个小数, 最多输出6位有效数字.
- string 字符串类型 包含在#include <string>头文件中
- 布尔类型 bool 作用: 布尔数据类型代表真或假的值
bool类型只有两个值:true 真(本质是1)
false 假(本质是0)
bool类型占1个字节大小
另外, bool类型除了0代表假, 其它都代表真.(非0的值都代表真)
例如:如果输入给bool的值为100, 那么flag的值为1
bool flag = true;
cout << flag << endl;
flag = false;
cout << flag << endl;
// 输出结果为1
//0
- 两个整数相除, 结果仍然是整数, 将小数部分直接舍弃掉.
- 两个小数相除, 如果可以整除, 结果是整数, 如果不可以整除, 结果是小数.(cout 的智能)
double a = 0.5;
double b = 0.25;
cout << a / b << endl;
// 结果是整数2
double a = 0.5;
double b = 0.22;
cout << a / b << endl;
//结果是小数
- C++ 不允许两个小数做取模运算(实际也很少见)
- string 数组
string names[3] = {"张三", "李四", "王五"};
cout << names[0] << endl;
//打印张三
(1)两个函数函数名相同, 但是参数的个数或者参数的类型不同.返回值不同, 不能构成函数重载.因为
double fun() {
return 0;
}
int fun() {
return 0;
}
int main() {
fun();// 有歧义, 不知道调用哪个函数.
}
(2)调用函数时, 实参的隐式类型转换可能会产生二义性.
#include <iostream>
using namespace std;
void display(long a) {
cout << "long" << a << endl;
}
void display(double a) {
cout << "double" << a << endl;
}
int main()
{
display(10);// int类型
display(10L);// long类型
display(10.0);// double类型
return 0;
}
// 此时有问题, 因为int类型的10, 可以隐式类型转换为long和double类型, 产生二义性.
函数重载2
本质:采用了name mangling或者叫name decoration技术
函数重载的底层是编译器采取了name mangling技术, 就是C++编译器默认会根据参数对符号名(比如函数名)进行修饰,改编, 生成新的函数名, 这个新的函数名会包含参数的信息.所以其实调用时函数名其实是不同的可以通过IDA不用debug模式(会添加很多调试信息导致看不到),而release模式(不添加调试信息,但会被编译器做优化也会导致看不到)所以采用release模式禁止优化来看到, 所以这些函数名可以同时存在, 并且可以正常调用.
即:重载时会生成多个不同的函数名, 不同的编译器(MSVC(微软VS的编译器), g++)有不同的生成规则.
默认参数
C++允许函数设置默认参数, 在调用时可以根据情况省略实参, 规则如下:
(1)默认参数只能按照右到左的顺序.
#include <iostream>
using namespace std;
int func(int v1, int v2 = 3, int v3 = 5) {
return v1 + v2 + v3;
}
int func1(int v1 = 3, int v2 = 3, int v3 = 4) {
return v1 + v2 + v3;
}
/*
int func2(int v1 = 3, int v2) {
}
错误,默认参数必须从右到左*/
int main()
{
cout << func(1) << endl;
cout << func(1,2) << endl;
cout << func(1, 2, 3) << endl;
cout << func1() << endl;
return 0;
}
(2)如果函数同时有声明, 实现, 默认参数只能放在函数声明中.
(3)默认参数的值可以是常量, 全局符号(全局变量, 函数名)
例如:
#include <iostream>
using namespace std;
int age = 20;
void sum(int v1 = 5, int v2 = age) {
cout << v1 + v2 << endl;
}
int main()
{
sum();
return 0;
}
#include <iostream>
using namespace std;
void func(int v1, void(*p)(int)) {
p(v1);
}
void test(int a) {
cout << a << endl;
}
int main()
{
func(20, test);
return 0;
}
#include <iostream>
using namespace std;
void test(int a) {
cout << a << endl;
}
void func(int v1, void(*p)(int) = test) { // 默认参数是函数名
p(v1);
}
int main()
{
func(20);
return 0;
}
(4)用途: 如果函数的实参经常是同一个值, 可以考虑使用默认参数
(5)函数重载, 默认参数可能会产生冲突, 二义性(建议优先选择默认参数)
#include <iostream>
using namespace std;
void display(int a, int b = 20) {
cout << a << endl;
}
void display(int a) {
cout << a << endl;
}
int main()
{
display(10);
// 10既可以传给第一个也可以传给第二个, 产生二义性
return 0;
}
(6)默认参数的本质:
还是传两个参数, 只不过传的是默认参数的值, 和原来的没有不同, 只不过编译器帮我们做了一些事情而已.
extern “C” 1-作用
(1)被extern “C” 修饰的代码会按照C语言的方式去编译
例如:
#include <iostream>
using namespace std;
extern "C" void func() {
}
// 会产生错误
extern "C" void func(int v) {
}
int main()
{
return 0;
}
也可以
#include <iostream>
using namespace std;
extern "C" {
void func() {
}
void func(int v) {
}
}
int main()
{
return 0;
}
(2)如果函数同时有声明和实现, 要让函数声明被extern “C” 修饰, 函数实现可以不修饰.
extern “C” 2-C,C++混合开发
(1)第三方框架\库:可能是用C语言写的开源库
在C++里调用C语言函数时, 经常用到extern “C”
因为C语言和C++的编译规则不同, C语言没有name mangling技术来修饰函数名.
extern "C" {
#include "math.h"// 因为math.h是用C语言写的第三方库, 所以要加extern "C", 这样可以把第三方库的函数声明全拿过来, 在源文件里就可以调用函数了.
}
但如果把extern “C” 直接写在第三方库的头文件里更方便, 在别人用第三方库时, 不用extern "C"了.但是这样会导致另一个问题, 如果用在C语言代码里时, C语言没有extern "C"这个东西, 所以会报错, 所以要用下面的东西
extern “C” 3-__cplusplus
C++环境下, 编译器会自动定义一个宏, __cplusplus
代表这是C++环境, 所以可以通过是否有这个宏来区分C++环境.例如:在math.h头文件中
#ifdef __cplusplus
extern "C" {
#endif
int sum(int v1, int v2);
int del(int v1, int v2);
int divide(int v1, int v2);
#ifdef __cplusplus
}
#endif
(2)补充:在自己编写的第三方库.c文件中, 一般也要包含自己写的.h头文件, 因为这个.c文件可能会存在函数之间互相调用, 而没有头文件, 就不能调用了.
(3)补充:在.h文件中, 为了防止重复包含头文件,在.h文件中这样写:
#ifndef ABC //举例
#define ABC
#ifdef __cplusplus
extern "C" {
#endif // __cplusplus
int sum(int v1, int v2);
int del(int v1, int v2);
int divide(int v1, int v2);
#ifdef __cplusplus
}
#endif // __cplusplus
#endif // !ABC
这样如果出现重复包含头文件时, 会因为已经定义过ABC导致后面的代码不会参与编译.防止头文件的内容被重复包含.
但是如果还有一个.h文件也瞎写成ABC, 就会导致错误
所以这个宏名是有规范的, 规定: 写成文件名就可以保证不同例如: __MATH_H
#ifndef __MATH_H
#define __MATH_H
因为这是特殊的宏所以要带下划线.
extern “C” 4-#pragma once
#pragma once 可以防止整个头文件的内容被重复包含
与#ifndef #define #endif 差不多
区别:
(1)较老的编译器不支持比如:gcc 3.4版本之前
(2)#ifndef #define #endif 受C\C++标准的支持, 不受编译器的任何限制.
(3)#ifndef #define #endif 可以针对一个文件中的部分代码, 而#pragma once 只能针对整个文件.
内联函数1(inline function)
(1)使用inline修饰函数的声明或实现, 可以使其变成内联函数.
(2)建议声明和实现都增加inline修饰
特点:
(1)编译器会将函数调用直接展开为函数体代码, 就不存在函数调用了.
代价:会增加代码数量, 使代码变臃肿.
但是如果不使用内联函数的话, 由于在函数调用过程中, 会先开辟栈空间给函数, 然后执行函数内的代码, 最后回收栈空间.存在这样一个操作, 如果这个函数频繁调用的话, 就会频繁进行这个操作, 使效率变低.
所以什么时候使用内联函数?
1.函数代码体积不大
2.频繁调用函数
(2)可以减少函数调用的开销
(3)会增大代码体积
注意:
(1)尽量不要内联超过10行代码的函数
(2)有些函数即使声明为inline, 也不一定会被编译器内联, 比如递归函数(无法内联).
内联函数与宏
(1) 内联函数和宏, 都可以减少函数调用的开销.
(2)对比宏, 内联函数多了语法检测和函数特性.
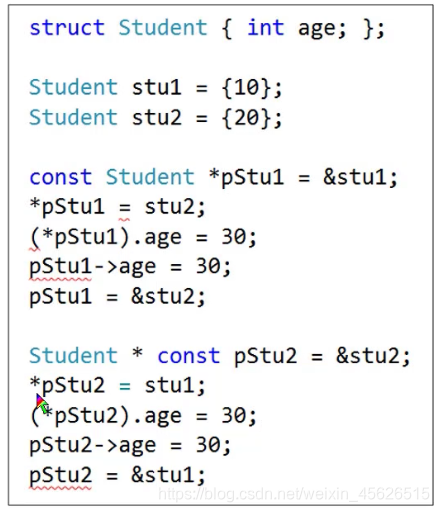
const
(1)const修饰的变量必须在定义时就指明它的值.
(2)如果修饰的是类或结构体(的指针), 其成员也不可以更改.
注意: 在C语言中定义结构体变量struct Date d = {2019,1,2};
但在C++里定义结构体变量时, 不需要struct, 可以直接Date d = {2010,2,2};
(3)
引用(Reference)
(1)在C语言中, 使用指针(Pointer)可以间接获取, 修改某个变量的值
(2)在C++中, 使用引用(Reference)可以起到跟指针类似的功能.
#include <iostream>
using namespace std;
int main()
{
int age = 10;
// 定义了一个age的引用, refAge相当于是age 的别名
int &refAge = age;
refAge = 20;
cout << age << endl;
// 结果是20
return 0;
}
注意点:
(1)引用相当于是变量的别名(基本数据类型, 枚举, 结构体, 类, 指针, 数组等, 都可以有引用)
(2)对引用做计算, 就是对引用所指向的变量做计算.
(3)在定义的时候就必须初始化, 一旦指向了某个变量, 就不可以再改变, "从一而终"
(4)可以利用引用初始化另一个引用, 相当于某 个变量的多个别名.
(5)
(6)默认情况下引用类型要跟引用的变量类型匹配
引用存在的价值之一:比指针更安全, 函数返回值可以被赋值.
引用的本质
(1)引用的本质就是指针, 只是编译器削弱了它的功能, 所以引用就是弱化了的指针.
x86: 32位 指针4个字节
x64: 64位 指针8个字节
(2)一个引用占用一个指针的大小
汇编语言
学习汇编语言2大知识点:
1.汇编指令
2.寄存器
C++可以轻易反汇编, 可以马上知道所写的C++代码的本质是什么.而其他的语言不容易看到.
汇编语言种类:
(1)8086汇编(16bit)
(2)x86汇编(32bit)
(3)x64汇编(64bit), 目前都是
(4)ARM汇编(嵌入式, 移动设备)
x64汇编根据编译器的不同, 有2种书写格式
(1)intel VS
(2)AT&T GCC, MAC
汇编语言不区分大小写
mov eax, 10
MOV EAX, 10
等价

x64汇编-寄存器(Registers)
不同的架构, 寄存器不一样
RAX\RBX\RCX\RDX : 通用寄存器
x86 32位一个寄存器能存4个字节
x64 一个寄存器能存8个字节
x64汇编兼容以前的汇编,(兼容以前的寄存器).
所以在RAX的低四个字节是EAX寄存器, EAX的低2个字节是AX寄存器, AX又分为AH和AL
AH H high AX的高位
AL L low AX的低位
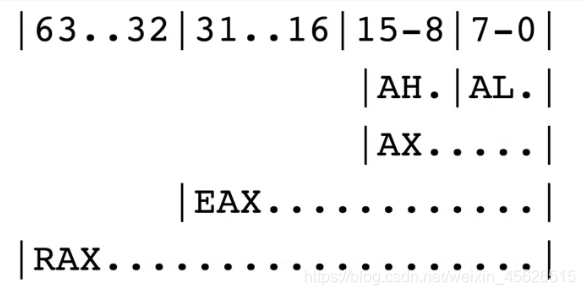
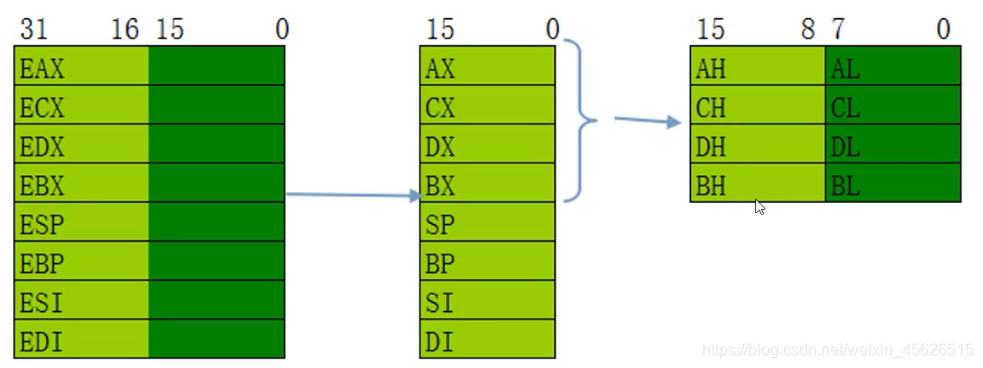
**结论:**所以如果给RAX赋8个字节的值(例如:1122334455667788), 会把原来赋值给EAX的值覆盖成55667788, 并把AX原来的值覆盖成7788.
x86 环境下(32位)
EAX\EBX\ECX\EDX : 通用寄存器
8086(16位)
AX\BX\CX\DX\ : 通用寄存器
一般的规律:
R开头的寄存器是64bit的, 占8个字节
E开头的寄存器是32bit的, 占4个字节
mov指令
(1)mov dest, src
将src的内容赋值给dest, 类似与dest = src
(2)[地址值]
中括号[]里面放的都是内存地址
word 是 2 字节, dword 是 4 字节(double word), qword是8字节(quad word)
int a = 4;
对应汇编:mov dword ptr [ebp-xxh] 4
ptr是固定写法, ebp-xxh是a的地址,dword说明是4个字节, 所以会把ebp-xxh往高地址的包括ebp-xxh的4个内存地址赋值成4
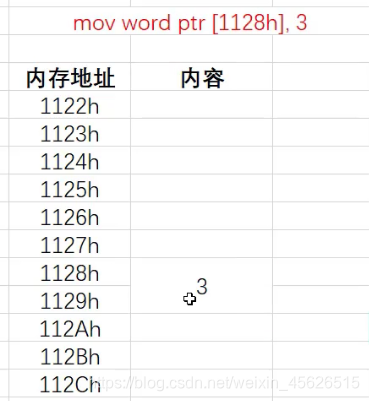
(3)call 函数地址
一旦看到call 一定是调用函数
call之前的push都是传参
(4)变量地址总结
一个变量的地址值, 是它所有字节地址中的最小值.
例: int a = 4;
a有4个字节, 那每一个字节都有一个内存地址.
所以它所有字节地址中的最小值就是变量a 的地址值.
&a 的值是0x007DF968
大小端模式, 现在大部分都是小端模式.
小端模式:
4的二进制00000000 00000000 00000000 00000011
存储时:高字节对应高地址,低字节对应低地址
所以内存地址 内容
0x7DF968 00000011
0x7DF969 00000000
0x7DF96A 00000000
0x7DF96B 00000000
读取时:从高地址读取所以读取00000000 00000000 00000000 00000011
(5)lea dest, [地址值]
lea : load effect address 装载一个有效的地址值
lea eax, [1122H]
意思:直接将地址值赋值给eax
如果是mov eax, [1122H]
意思是:取出1122H这个地址存放的值再赋值给eax.
(6)ret
ret: return
函数返回
(7)xor op1, op2
将op1和op2异或的结果赋值给op1, 类似与op1 = op1 ^ op2
(8)add op1, op2
类似于op1 = op1 + op2
(9)sub op1, op2
类似于op1 = op1 - op2
(10)inc op
inc : increase
自增, 类似于 op = op + 1
(11)dec op
dec : decrease
自减, 类似于op = op - 1
(12)jmp 内存地址
jmp : jump 跳转
调转到这个内存地址对应的代码
j开头的一般都是跳转, 大多数是带条件的跳转, 一般跟test, cmp等指令配合使用.
(13)jne :jump not equal, 比较结果不相等才跳转.
其他j开头的汇编指令详见jcc(Jump Condition Code)文件
const 引用(常引用Const Reference)
引用可以被const修饰, 这样就无法通过引用修改数据了, 可以称为常引用.
(1)const int &ref = age;
ref = 30; // 错误
可以访问
类似于 const int *ref = &age;
(2)int & const ref = age;
ref = 30; // 正确
意思是ref不能修改指向, 但是可以通过ref间接修改所指向的变量
但没有意义, 因为ref本来就不能修改指向.
所以const 必须写在&的左边, 才能算是常引用.
const引用的特点
(1)可以指向临时数据(常量, 表达式, 函数返回值等)
(2)可以指向不同类型的数据.
(3)作为函数参数时(此规则也适用于const指针)
1.可以接受const和非const实参(非const引用, 只能接受非const实参)
#include <iostream>
using namespace std;
int sum(const int &v1,const int &v2) {
return v1 + v2;
}
int main()
{
// 非const实参
int a = 10;
int b = 20;
sum(a, b);
// const实参
const int c = 10;
const int d = 20;
sum(c, d);
sum(10, 20);
return 0;
}
因为如果非const引用可以接受const实参的话, 在函数里面可以v1 = 20; 这样就会改变c的值, 但c是const的常量, 所以会冲突矛盾.
2.可以跟非const引用构成重载.
int sum(int &v1, int &v2) {
}
int sum(const int &v1, const int &v2) {
}
如果不是引用时,就不能构成重载.
int sum(int v1, int v2) {
}
int sum(const int v1, const int v2) {
}
// 不行
补充:当常引用指向了不同类型的数据时, 会产生临时变量, 即引用指向的并不是初始化时的那个变量.
数组的引用.
(1)
int arr[] = {1,2,3};
int (&ref)[3] = arr;
ref[1] = 10;
类似于0
int arr[] = {1,2,3};
int (*p)[3] = arr;
p[1] = 10;
(2)
int arr[] = {1,2,3};
int * const &ref = arr;
因为数组名arr其实是数组的地址, 也是数组首元素的地址
数组名arr可以看做是指向数组首元素的指针.(int *类型), 又因为数组的地址不能修改是常量
所以可以写成, int * const &ref = arr; 常引用
面向对象1-类和对象
C++中可以使用struct, class来定义一个类
struct 和 class的区别:struct的默认成员权限是public
class的默认的成员权限是private
变量名规范参考:
全局变量: g_ global g_age
成员变量: m_ member m_age
静态变量: s_
常量: c_ const
或使用驼峰标识 gAge, mAge
面向对象2- 对象的内存
#include <iostream>
using namespace std;
class Person {
public:
int m_id;
int m_age;
int m_height;
void display() {
cout << m_id << m_age << m_height << endl;
}
};
int main()
{
Person person;
person.m_id = 1;
person.m_age = 2;
person.m_height = 3;
cout << &person << endl;
cout << &person.m_id << endl;
cout << &person.m_age << endl;
return 0;
}

面向对象3-this
函数都存储在代码段
局部变量存储在栈区
那怎么访问person1, person2对象的成员变量的?其实内部有this指针, 隐式参数,看不到,在调用函数会把调用者的地址传过去
面向对象4-指针访问的本质
原理:如何利用指针间接访问所指向的对象的成员变量?
1.从指针中取出对象的地址
2.利用对象的地址 + 成员变量的偏移量计算出成员变量的地址
3.根据成员变量的地址访问成员变量的存储空间
面向对象5-指针的思考题
面向对象6-0xCC
涉及到函数调用栈
每调用一个函数时, 会给这个函数分配一个栈空间, 但这个栈空间里面的数据可能是垃圾数据, 也可能是之前别的函数用过的, 所以在真正在用这个栈空间之前,会用CC来填充栈空间, 使这个栈空间里面的数据全是C,为什么用CC来抹掉之前的数据, 不用00呢?
什么是CC?
如果把CC当做机器码来看的话, 对应的汇编代码是int3, int3 : 起到断点的作用. int3是断点的意思
在汇编里面int叫做中断, 后面的3是中断码,中断码是3就是断点的意思
int - interrupt
好处: 假设jmp, jz 后面跟的地址值指错了, 指成了函数的栈空间,那么一跳转到函数的栈空间, 就会执行int3就会停下来, 就不至于假设以前是一些垃圾数据, 可能做一些危险的指令操作.变得安全.这样的话, 函数的栈空间不小心被别人当做代码来执行, 那也很安全了.
函数代码在代码段, 调用函数, 执行函数代码其实就是CPU在访问代码区的内存(机器指令).
为什么函数代码在代码区, 又要给函数分配一段栈空间呢?
因为在函数里面要定义局部变量, 所以在调用函数时, 要分配一段额外的空间来存放局部变量.
因为代码区是只读的, 而函数内部的局部变量是可以改的, 所以选择了栈空间.
内存1-封装, 内存布局, 堆空间
封装
成员变量私有化, 提供公共的getter和setter给外界去访问成员变量.
内存空间的布局
每个应用都有自己独立的内存空间, 其内存空间一般都有以下几大区域:
1.代码段(代码区)(Code )
用于存放代码(机器指令)
2.数据段(全局区)
用于存放全局变量等
3.栈空间
(1)每调用一个函数就会给它分配一段连续的栈空间, 等函数调用完毕后会自动回收这段栈空间.
(2)自动分配和回收
4.堆空间
需要主动去申请和释放
堆空间
(1)堆空间的价值:
在程序运行过程, 为了能够自由控制内存的生命周期, 大小, 会经常使用堆空间的内存.
(2)堆空间的申请\释放
1.malloc\free
2.new \ delete
int *p = new int;
*p = 10;
delete p;
只要看到new就是向堆空间申请内存
申请什么看右边, new int 就是申请一个int类型大小的空间,不用强制类型转换.
所以直接new int 就是向堆空间申请4个字节, 并且把这4个字节地址值赋值给左边的指针
char *p = new char;
*p = 10;
delete p;
这个是申请1个字节
3.new [] \ delete[]
char *p = new char[4];
申请了4个连续的字节
delete[] p;
注意:
申请堆空间成功后, 会返回那一段内存空间的地址
申请和释放必须是1对1的关系, 不然可能会存在内存泄露.
内存4-堆空间的初始化
(1)malloc是否初始化与编译器有关
memset 函数 memory set
int *p = (int * )malloc(sizeof(int)*10);
memset(p, 0, 40);
第一个参数是内存地址
第二个参数是初始化为什么值
第三个参数是初始化多少字节
意思是:从p这个地址开始连续的40个字节, 每一个字节都设置为0
(2)new \ delete
int *p0 = new int; 不会初始化
int *p1 = new int(); 默认初始化为0
int *p2 = new int(5); 初始化为传入的值
int *p3 = new int[3]; 数组元素未被初始化
int *p4 = new int3; 3个数组元素都被初始化为0
int *p5 = new int[3]{}; 3个数组元素都被初始化为0
int *p6 = new int[3]{5}; 数组首元素初始化为5, 其他元素都是0
内存5-对象的内存
对象的内存可以存在于3种地方:
全局区(数据段): 全局变量
栈空间:函数里面的局部变量
堆空间:动态申请内存(malloc, new等)

构造函数1(Constructor)
构造函数(也叫构造器), 在对象创建的时候自动调用, 一般用于完成对象的初始化工作.
特点:
(1)函数名与类同名, 无返回值(void都不能写), 可以有参数, 可以重载, 可以有多个构造函数.
(2)一旦自定义了构造函数, 必须用其中一个自定义的构造函数来初始化对象.
注意:
(1)通过malloc分配的对象不会调用构造函数
(2)通过new分配的对象可以调用构造函数, 即在堆空间中的对象可以调用构造函数, 在栈空间的也可以, 在全局区(数据段)的也可以.只有malloc不会调用.因为malloc在C语言就有了, 那时候还没有构造函数.
所以new至少比malloc多做了调用构造函数这件事情.
(3)一个广为流传的, 很多教程\书籍都推崇的错误结论:
默认情况下, 编译器会为每一个类生成空的无参的构造函数.
正确理解: 在某些特定的情况下, 编译器才会为类生成空的无参的构造函数.
构造函数2
构造函数的调用:
#include <iostream>
using namespace std;
class Person {
public:
int m_age;
Person() {
m_age = 0;
cout << "Person()" << endl;
}
Person(int age) {
m_age = age;
cout << "Person(int age)" << endl;
}
};
Person person1(); // 函数声明
Person person1() { // 函数实现
return Person();
}
Person g_person0; // Person();
Person g_person1(); // 全局的函数声明
// 返回值 函数名
Person g_person2(10); // Person(int)
int main()
{
Person person0; // Person()
Person person1(); // 局部的函数声明
Person person2(20); // Person(int)
Person *p0 = new Person; // Person()
Person *p1 = new Person(); // Person()
Person *p2 = new Person(30); // personn(int)
return 0;
}
成员变量的初始化(了解)
如果自定义了构造函数, 除了全局区, 其他内存空间的成员变量默认都不会被初始化, 需要开发人员手动初始化.
如果有很多个成员变量, 如何方便的初始化.
class Person {
int m_age1;
int m_age2;
int m_age3;
int m_age4;
int m_age5;
Person() {
memset(this, 0, sizeof(Person));
// 从person对象的地址开始, 它的所有字节都清0
}
};
析构函数(Destructor)
析构函数(也叫析构器), 在对象销毁(对象的内存被回收的时候)的时候自动调用, 一般用于完成对象的清理工作.
特点:
(1)函数名以~开头, 与类同名, 无返回值(void都不能写), 无参, 不可以重载, 有且仅有一个析构函数.
注意:
(1)通过malloc分配的对象free的时候不会调用析构函数.
(2)构造函数, 析构函数要声明为public, 才能被外界正常使用.所以构造函数和析构函数必须声明为public, 否则会报错.
内存管理
声明和实现分离
命名空间
继承
继承, 可以让子类拥有父类的所有成员(变量\函数)
成员访问权限
成员访问权限, 继承方式有3种
public : 公共的, 任何地方都可以访问(struct默认)
protected: 子类内部, 当前类内部可以访问
private: 私有的, 只有当前类内部可以访问(class默认)
结论:
子类内部访问父类成员的权限, 是以下2项中权限最小的那个
1.成员本身的访问权限
2.上一级父类的继承方式
(1)所以一般都写public继承, 因为public继承可以将父类原有的访问权限继承下来.
(2)访问权限不影响对象的内存布局.
初始化列表1
特点:
(1)一种便捷的初始化成员变量的方式
(2)只能用在构造函数中
(3)初始化顺序只跟成员变量的声明顺序有关
#include <iostream>
using namespace std;
class Person {
public:
int m_age;
int m_height;
/*Person(int age, int height) {
m_age = age;
m_height = height;
}*/
// 语法糖
Person(int age, int height) : m_age(age), m_height(height) {
}
// 这个构造函数与上面的构造函数等价
};
int main()
{
Person person(18, 180);
cout << person.m_age << endl;
cout << person.m_height << endl;
return 0;
}
初始化列表与默认参数配合使用
#include <iostream>
using namespace std;
class Person {
public:
int m_age;
int m_height;
Person(int age = 0, int height = 0) : m_age(age), m_height(height) {
}
// 一个构造函数相当于写了3个构造函数
};
int main()
{
Person person1;
Person person2(19);
Person person3(20, 180);
return 0;
}
如果函数声明和实现是分离的
初始化列表只能写在函数的实现中
默认参数只能写在函数声明中
#include <iostream>
using namespace std;
class Person {
public:
int m_age;
int m_height;
Person(int age = 0, int height = 0);
};
Person::Person(int age, int height) : m_age(age), m_height(height) {
}
int main()
{
Person person;
return 0;
}
构造函数的互相调用
结论:构造函数调用构造函数要在初始化列表里面写.
例如:
#include <iostream>
using namespace std;
class Person {
public:
int m_age;
int m_height;
Person() : Person(0, 0) {}
Person(int age, int height) : m_age(age), m_height(height) {}
};
int main()
{
Person person;
return 0;
}
注意:下面的写法是错误的, 初始化的是一个临时对象.
class Person {
int m_age;
int m_height;
Person() {
Person(0, 0);
}
Person(int age, int height) : m_age(age), m_height(height) {}
};
初始化列表3-父类的构造函数
(1)子类的构造函数默认会调用父类的无参构造函数
(2)如果子类的构造函数显式地调用了父类的有参构造函数, 就不会再去默认调用父类的无参构造函数
#include <iostream>
using namespace std;
class Person {
public:
int m_age;
Person() {
cout << "Person::Person()" << endl;
}
Person(int age) {
cout << "Person::Person(int age)" << endl;
}
};
class Student : public Person {
public:
int m_no;
Student() : Person(10) {
cout << "Student::Student()" << endl;
}
};
int main()
{
Student student;
return 0;
}
(3)如果父类缺少无参构造函数(但有有参构造函数), 子类的构造函数必须显式调用父类的有参构造函数.不然会报错. 因为子类的构造函数默认会调用父类无参的构造函数, 如果父类缺少无参的构造函数, 就报错.
#include <iostream>
using namespace std;
class Person {
public:
int m_age;
Person(int age) {
cout << "Person::Person(int age)" << endl;
}
};
class Student : public Person {
public:
int m_no;
Student() : Person(10) {
cout << "Student::Student()" << endl;
}
//父类缺少无参的构造函数, 子类的构造函数
//必须显式的调用父类的有参构造函数.
};
int main()
{
Student student;
return 0;
}
(4)如果父类什么构造函数都没有, 那子类的构造函数就不调用了.
(5)价值:
#include <iostream>
using namespace std;
class Person {
private:
int m_age;
public:
Person(int age) : m_age(age){ }
int getAge() {
return m_age;
}
};
class Student : public Person {
private:
int m_no;
public:
Student(int age, int no) : Person(age), m_no(no) { }
int getNo() {
return m_no;
}
};
int main()
{
Student student(10, 20);
cout << student.getAge() << '\n' <<
student.getNo() << endl;
return 0;
}
多态1
父类指针, 子类指针
(1)父类指针可以指向子类对象, 是安全的, 开发中经常用到(继承方式必须是public)
(2)子类指针指向父类对象是不安全的.(因为不安全, 所以编译器会报错)
#include <iostream>
using namespace std;
class Person {
public:
int m_age;
};
class Student : public Person {
public:
int m_score;
};
int main()
{
Person *p = new Student();
p->m_age = 10;
// 安全
/*
Student *p = (Student*) new Person();
p->m_age = 10;
p->m_score = 10;;
不安全
*/
return 0;
}

安全原因:
person父类指针能访问的范围只有age(父类里面定义的成员变量), 而Student对象一定有age.不会超出申请的堆空间的范围.
父类能访问的东西都是能保证在子类的对象里面能找到的.所以用父类指针去访问子类对象的内存, 肯定是安全的.
因为父类指针能访问的内存范围肯定是在子类对象的内存范围之内.
不安全原因:
p->m_socre = 100; 会找到age后面连续的4个字节赋值, 而后面的4个字节没有申请, 不属于你, 可能是别的对象的, 会把别的对象的数据覆盖掉.
多态
默认情况下, 编译器只会根据指针类型调用对应的函数, 不存在多态
多态是面向对象非常重要的一个特性
定义:同一操作作用于不同的对象, 可以有不同的解释, 产生不同的执行结果
在运行时, 可以识别出真正的对象类型, 调用对象子类的函数
多态的要素
(1)子类重写父类的成员函数(override)
(2)父类指针指向子类对象
(3)利用父类指针调用重写的成员函数
多态2-虚函数
C++中的多态通过虚函数(virtual function)来实现
虚函数:被virtual修饰的成员函数
只要在父类中声明为虚函数, 子类中重写的函数也自动变成虚函数(也就是说子类中可以省略virtual关键字)
#include <iostream>
using namespace std;
class Animal {
public:
virtual void speak() {
cout << "Animal::speak()" << endl;
}
virtual void run() {
cout << "Animal::run()" << endl;
}
};
class Dog : public Animal {
public:
// 重写(override)
void speak() {
cout << "Dog::speak()" << endl;
}
void run() {
cout << "Dog::run()" << endl;
}
};
class Cat : public Animal {
void speak() {
cout << "Cat::speak()" << endl;
}
void run() {
cout << "Cat::run()" << endl;
}
};
class Pig : public Animal {
void speak() {
cout << "Pig::speak()" << endl;
}
void run() {
cout << "Pig::run()" << endl;
}
};
void liu(Animal *p) {
p->speak();
p->run();
}
int main()
{
liu(new Dog());
liu(new Cat());
liu(new Pig());
return 0;
}
多态3-虚表
虚函数的实现原理是虚表, 这个虚表里面存储着最终需要调用的虚函数地址, 这个虚表也叫虚函数表.
虚表(x86环境的图)

一旦多了虚函数, cat对象就会多4个字节, 根据这4个字节存储的地址值, 就可以找到虚表的存储空间, 然后取出这个存储空间中存储的函数地址, 然后调用函数.(Call 函数地址)就可以调用cat的speak, cat 的run, 也就是说它提前就把Cat的speak函数地址, run函数地址放到了虚表中.
多态4-虚表的汇编分析
调用speak()
// 调用speak
Animal *cat = new Cat();
cat->speak();
// ebp-8 是指针变量cat的地址
mov eax, dword ptr [ebp-8]
// 根据指针变量的地址, 找到指针变量的存储空间, 取出存储空间里面的东西, 也就是Cat对象的地址给eax
// 所以eax是Cat对象的地址
mov edx, dword ptr [eax]
// 根据Cat对象的地址值, 找到Cat对象的存储空间, 取出4个字节出来赋值给edx
// 取出Cat对象最前面的4个字节(虚表的地址)给edx
mov eax, dword ptr [edx]
// 根据edx的地址值, 找到edx的存储空间, 取出虚表的前4个字节(Cat::speak的函数地址)赋值给eax
call eax
// call Cat::speak 调用函数
调用run()
// 调用run
Animal *cat = new Cat();
cat->run();
// ebp-8 是指针变量cat的地址
mov eax, dword ptr [ebp-8]
// 所以eax是Cat对象的地址
mov edx, dword ptr [eax]
// 根据Cat对象的地址值, 找到Cat对象的存储空间, 取出4个字节出来赋值给edx
// 取出Cat对象最前面的4个字节(虚表的地址)给edx
mov eax, dword ptr [edx+4]
// 根据edx+4之后的地址值, 从这个地址值开始找到它的存储空间, 取出4个字节(Cat::run的函数地址)赋值给eax
// 跳过虚表的最前面4个字节, 在取出4个字节(Cat::run的函数地址)赋值给eax
call eax
// call Cat::run 调用函数
多态5-虚表的作用

Pig有Pig的虚表, Cat有Cat 的虚表
编译器在编译cat->speak(); 时只知道cat是Animal*类型, 不知道cat是new Cat(), 因为new Cat()是在运行时, 才知道的, 所以采用了虚表, 即把对象的函数地址跟对象绑在一起.
多态6-虚表的细节
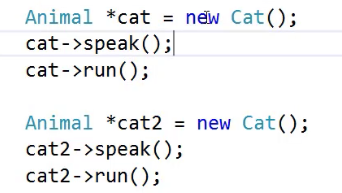
第一个Cat对象和第二个Cat 对象最前面的4个字节是一样的, 它们的虚表的地址是一样的, 它们是同一张虚表.(合理, 没有必要搞多份因为虚表的内容是一样的)
即所有的Cat对象(不管在全局区, 栈, 堆)共用同一份虚表.
(2)如果父类里面有两个虚函数, 子类里面只重写了一个, 那编译器就会把父类里面的虚函数和子类里面的虚函数放到虚表里.
(3)有虚函数就有虚表
多态7-调用父类的成员函数
当子类重写父类的成员函数时, 如果想要调用父类的成员函数的内容.直接Animal::speak();
class Animal {
public:
virtual void speak() {
cout << "Animal::speak()" << endl;
}
};
class Cat : public Animal {
public:
void speak() {
Animal::speak(); // 调用父类的成员函数
cout << "Cat::speak()" << endl;
}
};
多态8-虚析构函数
(1)如果存在父类指针指向子类对象的情况, 应该将析构函数声明为虚函数(虚析构函数)
(2)这样delete父类指针时, 才会调用子类的析构函数, 保证析构的完整性.
多态9-纯虚函数, 抽象类
纯虚函数: 没有函数体却初始化为0的虚函数, 用来定义接口规范.
抽象类(Abstract Class) : 含有纯虚函数的类就叫做抽象类.
抽象类不可以实例化(不可以创建对象)
抽象类也可以包含非纯虚函数, 成员变量
如果父类是抽象类, 子类没有重写所有的纯虚函数, 那么这个子类依然是抽象类.
如果子类重写了所有的纯虚函数, 那么这个子类不是抽象类.
#include <iostream>
using namespace std;
class Animal {
public:
virtual void speak() = 0;
virtual void run() = 0;
};
class Cat : public Animal {
public:
void speak() {
cout << "1" << endl;
}
void run() {
cout << "22" << endl;
}
};
int main()
{
Animal *cat = new Cat();
cat->speak();
cat->run();
return 0;
}
多继承
C++允许一个类可以有多个父类(不建议使用, 会增加程序设计复杂度)
先继承谁, 谁的成员变量放前面, 与父类的定义顺序无关.
多继承体系下的构造函数调用
#include <iostream>
using namespace std;
class Student {
private:
int m_score;
public:
Student(int score) : m_score(score) {}
};
class Worker {
private:
int m_salary;
public:
Worker(int salary) : m_salary(salary) {}
};
class Undergraduate : public Student, public Worker {
private:
int m_grade;
public:
Undergraduate(int score, int salary, int grade)
: Student(score), Worker(salary), m_grade(grade) {}
// 调用父类的构造函数
};
int main()
{
Undergraduate graduate(100, 2000, 3);
return 0;
}
多继承-虚函数
如果子类继承的多个父类都有虚函数, 那么子类对象就会产生对应的多张虚表.

同名函数

同名成员变量

多继承2-菱形继承

菱形继承带来的问题:
最底下子类从基类继承的成员变量冗余, 重复(有两个age, 内存是两份, 从语法上正确, 但不合理)
最底下子类无法访问基类的成员, 有二义性.
多继承3-虚继承
虚继承可以解决菱形继承带来的问题

Student和Worker共用一个age, 共享
从虚基类里面搞过来的成员变量都放到最后面, 这个对象会多出4个字节, 存放虚表指针, 20和12是拿来寻找age的, 拿来定位虚基类的成员变量在哪里, 因为age是共享的, 所以就要保证不管是从Worker这个类开始找还是从Student这个类开始找, 都能找到age.


Person类被称为虚基类
静态成员(static)
◼ 静态成员:被static修饰的成员变量\函数
□可以通过对象(对象.静态成员)、对象指针(对象指针->静态成员)、类访问(类名::静态成员)
◼ 静态成员变量
□ 存储在数据段(全局区,类似于全局变量),整个程序运行过程中只有一份内存, 不在类里面
□ 对比全局变量,它可以设定访问权限(public、protected、private),达到局部共享的目的
□ 必须初始化,必须在类外面初始化,初始化时不能带static,如果类的声明和实现分离(在实现.cpp中初始化)
◼ 静态成员函数
□ 内部不能使用this指针(this指针只能用在非静态成员函数内部)
□ 不能是虚函数(虚函数只能是非静态成员函数)
□ 内部不能访问非静态成员变量\函数,只能访问静态成员变量\函数
□ 非静态成员函数内部可以访问静态成员变量\函数
□ 构造函数、析构函数不能是静态
□ 当声明和实现分离时,实现部分不能带static
静态成员经典应用-单例模式
单例模式:设计模式的一种, 保证某个类永远只创建一个对象.
1.构造函数\析构函数私有化, 拷贝构造函数私有化, 赋值运算符重载函数私有化.
2.定义一个私有的static成员变量指向唯一的那个单例对象
3.提供一个公共的访问单例对象的接口.
#include <iostream>
using namespace std;
class Rocket {
private:
Rocket() {}
static Rocket *ms_rocket;
public:
static Rocket *sharedRocket() {
// 这里要考虑多线程安全
if (ms_rocket == NULL) {
ms_rocket = new Rocket();
}
return ms_rocket;
}
static void deleteRocket() {
// 这里要考虑多线程安全
if (ms_rocket != NULL) {
delete ms_rocket;
ms_rocket = NULL;
// 防止野指针
}
}
void run() {
cout << "run()" << endl;
}
};
Rocket *Rocket::ms_rocket = NULL;
int main()
{
Rocket *p = Rocket::sharedRocket();
p->run();
p->deleteRocket();
return 0;
}
(1)为什么要用指针?
1.在C++开发中, 对象能放堆空间, 尽量放堆空间.
2.对于单例对象, 要考虑内存的灵活使用, 因为牵扯到内存的分配和销毁, 所以用堆空间更灵活.
(2)赋值运算符重载函数为什么要私有化?
因为两个一样的对象做赋值操作没有意义.
(3)拷贝构造函数为什么要私有化?
因为如果不写拷贝构造函数, 还可以通过调用默认的拷贝构造函数去构建对象.如:
Rocket *p1 = Rocket::sharedRocket();
Rocket *p2 = new Rocket(*p1)
const成员, 引用成员
const成员: 被const修饰的成员变量, 非静态成员函数.
const成员变量:
1.必须初始化(必须在类内部初始化), 可以在声明的时候直接初始化赋值.
2.非static的const成员变量还可以在初始化列表中初始化.
const成员函数(非静态):(重点)
1.const关键字写在参数列表后面, 函数的声明和实现都必须带const
2.内部不能修改非static成员变量.
static成员变量的内存全世界只有一份, 哪里都可以修改, 而这个const的作用是限制了这个成员函数里面不能修改非static的成员变量.
3.内部只能调用const成员函数, static成员函数.
4.非const成员函数可以调用const成员函数
5.const成员函数和非const成员函数可以构成重载.
非const对象(指针)优先调用非const成员函数
const对象(指针)只能调用const成员函数, static成员函数.
#include <iostream>
using namespace std;
class Car {
public:
const int mc_price;
Car() : mc_price(0) {}
void run() const {
cout << "run()const" << endl;
}
void run() {
cout << "run()" << endl;
}
};
int main()
{
Car car;
car.run();
const Car car1;
car1.run();
return 0;
}
引用类型成员
1.引用类型成员变量必须初始化(不考虑static情况, 很少)
2.在声明的时候直接初始化, 或者通过初始化列表初始化.
#include <iostream>
using namespace std;
class Car {
int m_age;
int &m_price = m_age;
public:
Car(int &price) : m_price(price) {}
};
int main()
{
return 0;
}
拷贝构造函数1(Copy Constructor) (重点)
1.拷贝构造函数是构造函数的一种
2.当利用已存在的对象创建一个新对象时(类似于拷贝), 就会调用新对象的拷贝构造函数进行初始化.
3.拷贝构造函数的格式是固定的, 接收一个const引用作为参数
#include <iostream>
using namespace std;
class Car {
int m_price;
int m_length;
public:
Car(int price = 0, int length = 0) : m_price(price), m_length(length) {
cout << "Car(int price = 0, int length = 0)" << endl;
}
// 拷贝构造函数
Car(const Car &car) {
cout << "Car(const Car &car)" << endl;
m_price = car.m_price;
m_lengh = car.m_lengh;
}
void display() {
cout << "price =" << m_price << ", length = " << m_length << endl;
}
};
int main()
{
Car car1;
Car car2(100);
Car car3(100, 5);
// 利用已经存在的car3对象创建了一个car4新对象
// car4初始化时会调用拷贝构造函数
Car car4(car3);
car4.display();
return 0;
}
默认时, 如果没有写拷贝构造函数的话, 就不会帮你生成一个拷贝构造函数, 那他是怎么拷贝的呢?
默认的拷贝操作是: 类似于car4.m_price = car3.m_price; car4.m_length = car3.m_length;
从car3对象的地址开始的8个字节覆盖掉car4的8个字节
默认的拷贝会这个旧对象的所有数据(字节)全部覆盖掉另外一个对象的所有字节.
有写拷贝构造函数时: 会调用拷贝构造函数去初始化对象.此时系统默认的拷贝操作就不存在了.
拷贝构造2-调用父类的拷贝构造函数
#include <iostream>
using namespace std;
class Person {
public:
int m_age;
Person(int age = 0) : m_age(age) {}
Person(const Person &person) : m_age(person.m_age) {}
};
class Student : public Person {
public:
int m_score;
Student(int age = 0, int score = 0) : Person(age), m_score(score) {}
// 因为Student继承Person所以创建Student对象时, 又有age又有score
Student(const Student &student) : Person(student), m_score(student.m_score) {}
// 调用父类的拷贝构造函数
};
int main()
{
Student stu1(18, 100);
Student stu2(stu1);
cout << stu2.m_age << endl;
cout << stu2.m_score << endl;
return 0;
}
拷贝构造3-注意点
Car car1(100, 5);
Car car2(car1); // 拷贝构造
Car car3 = car2; // 拷贝构造与上一个等价(两种写法是等价的)创建car3的同时传了个car2, 通过car2来创建car3, 通过已经存在的对象创建新对象
Car car4;
car4 = car3; // car4是已经存在的对象(不是在创建新对象), 不会调用拷贝构造.仅仅是简单的赋值操作, 构造函数是在对象创建完之后马上调用的.
拷贝构造4-浅拷贝, 深拷贝
编译器默认的提供的拷贝是浅拷贝(shallow copy)
1.将一个对象中所有的成员变量的值拷贝到另一个对象
2.如果某个成员变量是个指针, 只会拷贝指针中存储的地址值, 并不会拷贝指针指向的内存空间
3.可能会导致堆空间多次free的问题(如果堆空间指向栈空间, 栈空间无法控制它的生命周期, 如果栈空间释放了, 堆空间的指针就指向了已经销毁的空间, 就成了野指针.)所以所有的堆空间指向栈空间都是危险的.
如果需要实现深拷贝(deep Copy), 就需要自定义拷贝构造函数
将指针类型的成员变量所指向的内存空间, 拷贝到新的内存空间
#include <iostream>
#include <cstring>
using namespace std;
class Car {
private:
int m_price;
char *m_name;
void copyName(const char *name) {
if (name == NULL) return;
// 申请新的堆空间
m_name = new char [strlen(name) + 1] {};
// 拷贝字符串数据到新的堆空间
strcpy(m_name, name);
}
public:
Car(int price = 0, const char *name = NULL) : m_price(price) {
copyName(name);
}
Car(const Car &car) : m_price(car.m_price) {
copyName(car.m_name);
}
~Car() {
if (m_name != NULL) {
delete[] m_name;
m_name = NULL;
}
}
void display() {
cout << "price is" << m_price << ", name is" << m_name << endl;
}
};
int main()
{
Car car1(100, "bmw");
Car car2 = car1;
car2.display();
return 0;
}
总结:拷贝构造函数这个东西只有在你需要进行深拷贝的时候, 才需要写.(类里面全是普通数据类型, 没有指针不需要写拷贝构造函数, 而有指针时, 对象在堆空间时, 堆空间的指针指向栈空间就很危险, 就需要写拷贝构造函数完成深拷贝, 而且如果不写, 直接浅拷贝的话, 会直接将指针里面存储的地址值拷贝过去, 导致两个对象的指针指向同一个东西.)
对象类型的参数和返回值
使用对象类型作为函数参数或者返回值, 可能会产生一些不必要的中间对象
(1)对象类型做函数参数时
void test1(Car car) { // 对象类型作为参数
}
int main() {
Car car1;
test1(car1);
}
把外面的对象传给里面的对象时, 会产生一个新的对象(不必要的中间对象), 因为相当于void test1(Car car = car1)利用一个已经存在的对象, 构建出了一个新的对象, 所以就是拷贝构造.
解决这个问题: 传引用或指针
void test1(Car &car) {
}
int main() {
Car car1;
test1(car1);
}
相当于void test1(Car &car = car1) 就直接引用着外面的car1对象, 这样就不会产生新的对象, 即将car1的地址值传给了car这个引用去保存, 因为引用的本质就是指针, 所以就是地址传递, 不会直接将对象传过去去构建一个新的对象.
(2)对象类型做返回值时:
Car test2() {
Car car;
return car;
}
int main() {
Car car2;
car2 = test2();
}
当把car返回时, 会多出一个拷贝构造, 因为在函数里面定义的car对象的内存在teat2所在的栈空间, 要把test2栈空间里面的对象返回到main函数的栈空间里, 而它的内存在离开函数后就销毁了, 所以要拷贝.
它的做法是:提前将test2里面的car对象拷贝构造出一个新的对象, 而这个新对象的内存是在main函数里面的.
(3)编译器优化
Car test2() {
Car car;
return car;
}
int main() {
Car car3 = test2();
}
只会调用1次拷贝构造, 直接给car3
匿名对象(临时对象)
匿名对象:没有变量名, 没有被指针指向的对象, 用完马上调用析构
(1)编译器优化(了解)
匿名对象作为参数
(2)编译器优化(了解)
直接返回匿名对象
隐式构造
C++里面存在隐式构造的现象 : 某些情况下, 会隐式调用单参数的构造函数
(1)Person p1 = 20;
调用了单参数的构造函数, 等价于Person p1(20);
(2)
void test1(Person person) {
}
int main() {
test1(20);
}
相当于Person person = 20; 调用单参数的构造函数构建对象
(3)
Person test2() {
return 40;
}
int main() {
test2();
}
隐式构造, 调用单参数构造函数构建出对象
(4)
Person p1;
p1 = 40;
只有对象才可以赋值给对象, 所以40会发生隐式构造, 相当于Person(40), 调用单参数的构造函数构建出一个临时对象.
(5)可以通过关键字explicit(明确的意思)来禁止掉隐式构造
class Person {
int m_age;
public:
explicit Person(int age) : m_age(age) {}
};
(6)有些地方也叫转换构造, 因为会将40直接转换成Person对象.
编译器自动生成的构造函数
C++的编译器在某些特定的情况下, 会给类自动生成无参的构造函数, 比如
(1)成员变量在声明的同时进行了初始化
class Person {
public:
int m_price = 5;
}
等价于
class Person {
public:
int m_price;
Person() {
m_price = 5;
}
}
编译器会自动生成构造函数, 初始化是在构造函数中做的.
(2)有定义虚函数
因为一旦有虚函数的话, 这个对象会多出4个字节来存放虚表地址.
在创建完Person对象后, 要给Person对象的最前面的4个字节赋虚表地址.

vftable = virtual function table
(3)虚继承了其他类
class Student : virtual public Person {
}
一旦虚继承了某个类, 那么当时候某个类创建出来的对象最前面4个字节存储着虚表地址
(4)包含了对象类型的成员, 而且这个成员有构造函数(自定义或编译器生成)
class Car {
public:
int m_price;
Car() {}
};
class Person {
Car car;
}
int main() {
Person person;
}
创建完person对象之后, person对象里面要搞一个Car对象, 就要调用Car的无参的构造函数,
所以这个时候编译器就会为Person这个类生成一个构造函数, 在构造函数里面调用Car的 构造函数去初始化car
(5)父类有构造函数(编译器生成或自定义)
class Person {
public:
Person() {}
};
class Student : public Person {
public:
};
因为子类要优先调用父类的构造函数, 所以编译器会为子类自动生成构造函数, 在构造函数里调用父类的构造函数.
总结:对象创建后, 需要做一些额外操作时(比如内存操作(为成员变量赋值), 函数调用), 编译器一般都会为其生成无参的构造函数.
友元
友元函数包括友元函数和友元类
(1)如果将函数A(非成员函数)声明为类C的友元函数, 那么在函数A内部就能直接访问类C对象的所有成员.
class Point {
friend Point add(Point, Point);
}
(2)如果将类A声明为类C的友元类, 那么在类A的所有成员函数内部都能直接访问类C对象的所有成员.
friend class [类名];
内部类
如果将类A定义在类C的内部, 那么类A就是一个内部类(嵌套类)
内部类的特点:
(1)支持public, protected, private 权限
class Person {
public:
class Car {
int m_price;
};
};
int main() {
Person::Car car1;
// 创建了一个car对象
}
(2)内部类的成员函数可以直接访问其外部类对象的所有成员(反过来则不行)
(3)成员函数可以直接不带类名, 不带对象名访问其外部类的static成员
class Point {
private:
static void test1() {
cout << "Point::test1()" << endl;
}
static int ms_test2;
int m_x;
int m_y;
public:
class Math {
public:
void test3() {
cout << "Point::Math" << endl;
test1();
ms_test2 = 10;
Point point;
point.m_x = 10;
point.m_y = 20;
}
};
};
(4)不会影响外部类的内存布局, 仅仅是访问权限变了而已, 内存布局是不变的.(编译器特性)
(5)可以在外部类内部声明, 在外部类外面定义.
局部类
在一个函数内部定义的类称之为局部类.
局部类的特点:
(1)作用域仅限于所在的函数内部
(2)其所有的成员必须定义(声明和实现)在类内部, 不允许定义static成员变量
因为static成员变量时使用前必须放在类外面初始化, 而局部类又要求必须放在里面, 矛盾.
(3)成员函数不能直接访问函数的局部变量(static变量除外)
因为函数的局部变量, 只有在调用函数时才分配存储空间, 那么在调用对象的成员函数访问其外部函数的局部变量时, 该局部变量还没有分配存储空间, 所以报错
在成员函数的栈空间里不能访问其他的栈空间里面的变量.
(4)局部类不影响其外部函数的内存布局.因为类的定义是代码, 存放在代码段, 不会开辟栈空间, 只有在创建对象时, 才会开辟栈空间(前提对象里面有成员变量). 类的定义和执行函数不同.
类放在函数里面或外面仅仅是访问权限的变化.
运算符重载1(operator overload)
运算符重载(操作符重载) : 可以为运算符增加一些新的功能.
#include <iostream>
using namespace std;
class Point {
friend Point operator+(const Point &, const Point &);
private:
int m_x;
int m_y;
public:
Point(int x, int y) : m_x(x), m_y(y) {}
void display() {
cout << "(" << m_x << ", " << m_y << ")" << endl;
}
};
Point operator+(const Point &p1, const Point &p2) {
return Point(p1.m_x + p2.m_x, p1.m_y + p2.m_y);
}
int main()
{
Point p1(10, 20);
Point p2(20, 30);
Point p3 = p1 + p2;
// 本质是Point p3 = operator+(p1, p2);
p3.display();
Point p4 = p1 + p2 + p3;
// 本质是调用了两次operator+, 第一次的结果又作为参数传进去
p4.display();
return 0;
}
运算符重载2-完善
(1)为什么拷贝构造函数的参数是const Point &point 形式?
1.必须是引用, 否则报错.
class Point {
public:
Point(Point point) {
this->m_x = point.m_x;
this->m_y = point.m_y;
}
};
int main() {
Point p1(10, 20);
Point p2 = p1;
// 利用已经存在的对象创建新的对象,
// 调用拷贝构造函数, 相当于Point point = p1
// 又是利用已经存在的对象创建新的的对象, 又
// 要调用拷贝构造函数, 就又相当于
// Point point = p1, 从而陷入死循环.所以
// 必须是引用. 一旦变成引用就是地址值的赋值
// 就不存在创建对象了.
}
2.最好是const, 从而保证可以接受const对象和非const对象, 使接受参数的范围更大.
运算符重载3-更多运算符
(1)一般来说跟某个对象相关的代码, 干脆重载为成员函数.
一旦变为成员函数, 就变成了
class Point {
public:
Point operator+(const Point &point) {
return Point(this->m_x + point.m_x, this->m_y + point.m_y);
// 只接受一个参数, 因为一旦变为成员函数, 就
// 通过对象去调用了, 比如p1 + p2 本质就变成了
// p1.operator+(p2);就意味着会把p1的地址传给
// operator+函数, this就指向外面的p1.
// 对比原来来说简单了, 首先只需要接受一个参数
// 其次这个功能本来就是跟Point相关的, 所以
// 直接写在Point类里面.而且一旦写成成员函数就
// 意味着我们自己的私有成员变量可以访问.
// 不需要友元函数.
}
};
(2)存在的问题:
在重载运算符的时候, 最好要保留运算符原有的特性, 比如:
因为int a = 10, b = 20; (a + b) 这个表达式不允许被赋值(因为a + b 返回的是常量并没有被存储在内存中), 所以(p1 + p2)也应该不能赋值, 因为p1 + p2 返回的是一个临时对象, 马上就要销毁了, 所以不应该可以赋值, 所以要在operator+函数的返回值前加const声明为返回常量对象, 不允许被赋值, 但这样的话, 又会导致新的问题, 在p1 + p2 + p3 时, 相当于p1.operator+(p2).operator+(p3) 因为常量对象是不能调用非常量函数的(因为在非常量函数里面按语法的话可以修改里面对象的值, 而常量对象又不允许修改, 矛盾), 所以也应该把operator+函数声明为常量函数.最终为
const Point operator+(const Point &point) const {
}
const Point operator-(const Point &point) const {
}
(3)+=运算符
因为int a = 10, b = 20; (a += b) = 10; 是可以被赋值的, 因为a += b是a + b后的结果又赋值给a, 而a可以被赋值, 所以(p1 += p2)也应该可以赋值
所以应该返回p1对象, 而返回对象(把对象作为返回值)又会导致产生中间对象的问题, 所以应该返回引用.
class Point {
public:
Point &operator+=(const Point &point) {
this->m_x += point.m_x;
this->m_y += point.m_y;
return *this;
}
};
(4)==运算符
int a = 10, b = 20;
if (a == b) 原来是相等返回1, 不相等返回0, 所以是bool类型
bool operator==(const Point &point) const {
// 要保证常量对象可以和非常量对象比较
/* if ((m_x == point.m_x) && (m_y == point.m_y)) {
return 1;
}
else {
return 0;
} */
return (m_x == point.m_x) && (m_y == point.m_y);
}
(5)!=运算符
bool operator!=(const Point &point) const {
return (m_x != point.m_x) || (m_y != point.m_y);
}
(6)-运算符(符号)
首先-p1; 不需要传参, p1.operator-();
而且
Point p1(10, 20);
Point p3 = -p1; 时p1并没有改变, 所以应该返回一个临时的
其次int a = 10, b; (-a) = 10;不允许, 因为a并没有被赋值, 返回的是一个临时的值, 所以-p1不允许被赋值, 所以返回const
const Point operator-() const {
// 因为(-(-p1))时相当于 p1.operator-().operator-(),
// 而返回的const对象不能调用非const函数, 所以函数也要声明为const
return Point(-m_x, -m_y);
}
(7)++, --运算符
1.为了区分前置++和后置++规定
void operator++() {
// 是前置++
}
void operator++(int) {
// 是后置++
}
2.前置++可以被赋值, 后置++不可以被赋值
因为int a = 10;
int b = ++a + 5;
相当于a += 1; int b = a + 5; 也就是说++a是先让a += 1, 再把最新的a返回.所以可以被赋值.
而后置++ int a = 10;
int c = a++ + 5; 会先将a之前的值放到a++的地方等价于int c = 10 + 5; 在 a += 1; 所以a++的话并不会返回a.
3.最终实现:
前置:
Point &operator++() {
m_x++;
m_y++;
return *this;
}
后置:
而Point p2 = p1++ + Point(30, 40);
应该可以, 所以p1不能返回void而应该返回p1之前的值
所以
const Point operator++(int) {
Point old(this->m_x, this->m_y);
this->m_x++;
this->m_y++;
return old;
}
(8)<<运算符
1.因为cout << p1 << endl;
所以<<重载函数不能是成员函数, 一旦是成员函数就必须通过Point对象调用
其实cout也是对象, 它的类是ostream
ostream -> output stream
在头文件iostream中
2.因为cout << 1 << 2 << endl;
所以调用完函数后应该返回cout
3.因为(cout << 1) = cout; 返回cout后不允许被赋值, 所以const
但是返回值是const之后, 会导致cout << p1 << p2 出问题, 所以参数cout也应该const, 但是因为系统自带的const的定义是非const的, 所以参数是const会导致原来的const找不到.所以放弃, 但是发现其实不能被赋值, 因为在iostream头文件里, 将=赋值运算符重载到了private导致外面不能访问=
所以返回值不能是const, cout参数不能是const
ostream &operator<<(ostream &cout, const Point &point) {
cout << "(" << point.m_x << ", " << point.m_y;
return cout;
}
(9)cin运算符
input stream -> istream
1.要去掉后面参数的const, 因为是要输入东西去改变point对象.
istream &operator>>(istream &cin, Point &point) {
cin >> point.m_x;
cin >> point.m_y;
return cin;
}
运算符重载-调用父类的运算符重载函数
class Person {
int m_age;
public:
Person &operator=(const Person &person) {
this->m_age = person.m_age;
}
};
class Student : public Person {
int m_score;
public:
Student &operator=(const Student &student) {
Person::operator=(student);
this->m_score = student.m_score;
}
};
int main() {
Student stu;
stu.m_score = 60;
stu.m_age = 10;
Student stu1;
stu1 = stu;
}
运算符重载-仿函数(函数对象)
//int sum(int a, int b) {
// return a + b;
//}
class Sum {
int m_age;
public:
int operator()(int a, int b) {
return a + b;
}
};
int main() {
Sun sum;
cout << sum(10, 20) << endl;
// cout << sum.operator()(10, 20) << endl;
sum(20, 30);
}
仿函数和普通函数的区别是仿函数是成员函数, 意味着可以访问类里面的所有成员变量.
运算符重载注意点
1.有些运算符不可以被重载, 比如
(1)对象成员访问运算符: .
(2)域运算符: ::
(3)三目运算符: ?:
(4)sizeof
2.有些运算符只能重载为成员函数, 比如
(1)赋值运算符: =
(2)下标运算符: []
(3)函数运算符: ()
(4)指针访问成员: ->
模板(template)
泛型, 是一种将类型参数化以达到代码复用的技术, C++中使用模板来实现泛型
模板的使用格式如下:
template <typename\class T>
typename和class是等价的
模板没有被使用时, 是不会被实例化出来的.
例如:
template <class T>
T add(T a, T b) {
return a + b;
}
template <class T, class A, class C>
C add(T a, A b) {
return a + b;
}
int main() {
add<int>(10, 20);
add<double>(10.1, 2.2);
}
模版2-编译细节
模板的声明和实现如果分离到.h和.cpp中, 会导致链接错误.
编译, 链接原理
1.头文件不会参与编译, 因为头文件是拿来被包含的
2.编译器在编译时, 会对每一个cpp文件单独编译, 有一个add函数时, 通常把函数声明写在头文件add.h, 把函数实现
写在add.cpp文件(要#include “add.h”), 在main.cpp里面(#include “add.h”)即可, 这样的话在main.cpp里面有函数的声明, 没有函数的实现,
那么当使用add函数时, 因为有函数的声明所以不会报错, 但因为是单独编译, 所以main.cpp找不到函数的定义,
所以汇编代码是call <假的函数地址>, 在链接时, 才把假的函数地址修正成真的函数地址.
而如果有模板时, 因为编译add.cpp时, 不会生成具体的函数实现, 因为是单独编译, 不知道main里面的参数类型(没有被使用, 就不会生成函数实现),
所以不会生成具体的实现.所以在链接时, 就无法修正call 的函数地址.所以会导致链接错误
所以在写模板时, 不要把模版的声明和实现分离, 要放在同一个.h文件中
一般将模板的声明和实现统一放到一个.hpp文件(仍是头文件, 只是语义好一点)中, 在直接#include “add.hpp”
类型转换
C语言风格的类型转换符
(type)expression
int a = 10;
double d = a; // 隐式转换
C++中有4个类型转换符
static_cast
dynamic_cast
reinterpret_cast
const_cast
cast是转换的意思
使用格式:xx_cast(expression)
1.const_cast
一般用于去除const属性, 将const转换成非const
例如:
const Person *p1 = new Person();
// C++风格
Person *p2 = const_cast<Person *>(p1);
// C风格
Person *p3 = (Person *)p1;
// 这两种写法没有任何区别, 只是不同语言的写法而已
很多强制类型转换只是骗一下编译器, 本质其实就是赋值
相当于Person *p2 = p1;
2.dynamic_cast
一般用于多态类型的转换, 有运行时安全检测.
多态类型: 能完成多态功能的那几个类.
用法:
class Person {
virtual void run() {}
};
class Student : public Person {
};
int main() {
Person *p1 = new Person();
Person *p2 = new Student();
Student *stu1 = dynamic_cast<Student *>(p1);
// 不安全, 因为相当于
// Studnet *stu1 = new Person();就成了用子类指针
// 指向父类对象, 不安全, 因为子类指针可以访问的
// 范围超过父类对象所占的内存.
Student *stu2 = dynamic_cast<Student *>(p2);
// 安全, 相当于Student *stu2 = new Student();
}
dynamic_cast 可以检测到是否安全, 一旦检测到不安全, 直接让指针清空 = NULL, 变成空指针.
3.static_cast(了解, 开发中很少用)
1.对比dynamic_cast, 缺乏运行时安全检测
2.不能交叉转换(不是同一继承体系的, 无法转换)
3.常用于基本数据类型的转换, 非const转成const
int main() {
int a = 10;
double b = static_cast<double>(a);
// 完全等价于double b = a;和double b = (double)a;
Person *p1 = new Person();
const Person *p2 = static_cast<const Person *>(p1);
// 等价于 const Person *p2 = p1;
}
4.reinterpret_cast
1.属于比较底层的强制转换, 没有任何类型检查和格式转换, 仅仅是简单的二进制数据拷贝
2.语法限制:如果是不同类型之间的转换, 需要用引用, 仅仅是语法糖
3.可以交叉转换
int main() {
int a = 10;
double d = a;
// 不是简单的二进制数据拷贝, 而是转换成浮点数的存储方式
double d = reinterpret_cast<double&>(a);
// 没有任何类型检查, 仅仅是简单的二进制数据拷贝.
// 但double有8个字节, int有4个字节, 所以仅仅是
// 将a的4个字节覆盖掉double的4个字节, double剩下
// 的4个字节不管. 如果在栈空间默认是cc
}
C++11新特性
1.auto
可以从初始化表达式中推断出变量的类型, 大大简化编程工作
int a = 10;
auto a = 10; // 发现右边是整型, 所以a是int类型
auto str = "C++"; // const char *
auto p = new Person(); // Person*
属于编译器特性, 不影响最终的机器码质量, 不影响运行效率
2.decltype
decl = declear type 声明类型
可以获取变量的类型
int a = 10;
decltype(a) b = 20; // 相当于int b = 20;
3.nullptr
nullptr == null pointer 空指针
以后凡是清空指针都用nullptr不用NULL, 因为不专业
int *p = NULL
int *p1 = nullptr;
可以解决NULL二义性的问题
func(0);
func(nullptr);
func(NULL);
NULL -> #define NULL 0
4.快速遍历
int array[] = {1, 2, 3, 4};
for (int item : array) {
cout << item << endl;
}
// 将array里面的元素挨个取出来赋值给item
// 等价于
for (int i = 0; i < 4; i++) {
int item = array[i];
cout << item << endl;
}
5.更加简洁的初始化方式
int array[]{1, 2, 3 , 4};
完全等价于
int array[] = {1, 2, 3, 4};
6.Lambda表达式(重点)
Lambda表达式