文章目录
轻松手撕 HashMap
TreeMap分析
-
时间复杂度:
- 添加, 删除, 搜索: O(logn)
-
特点:
- Key 必须具备可比较性
- 元素的分布是有顺序的
-
在实际应用中, 很多时候的需求
- Map 中存储的元素不需要讲究顺序
- Map 中的 Key 不需要具备可比较性
-
不考虑顺序, 不考虑 Key 的可比较性, Map 有更好的实现方案, 平均时间复杂度可以达到 O(1)
- 那就是采取哈希表来实现 Map
哈希表 (Hash Table)
-
哈希表也叫做散列表 (hash 有 “剁碎” 的意思)
-
添加, 搜索, 删除的流程都是类似的
- 1.利用哈希函数生成 key 对应的 index
O(1) - 2.根据 index 操作定位数组元素
O(1)
- 1.利用哈希函数生成 key 对应的 index
-
哈希表是
空间换时间的典型应用 -
哈希函数, 也叫做散列函数
-
哈希表内部的数组元素, 很多地方也叫 Bucket (桶) , 整个数组叫 Buckets 或者 Bucket Array 或者 Table
哈希冲突
- 哈希冲突也叫做哈希碰撞
- 2 个不同的 key, 经过哈希函数计算出相同的结果
- key1 != key2, hash(key1) == hash(key2)
- 解决哈希冲突的常见方法
- 1.开放定址法(Open Addressing)
- 按照一定的规则(线性探测, 平方探测)向其他地址探测, 直到遇到空桶
- 2.再哈希法(Re-Hashing)
- 设计多个哈希函数
- 3.链地址法(Separate Chaining)
- 比如通过链表将同一index的元素串起来
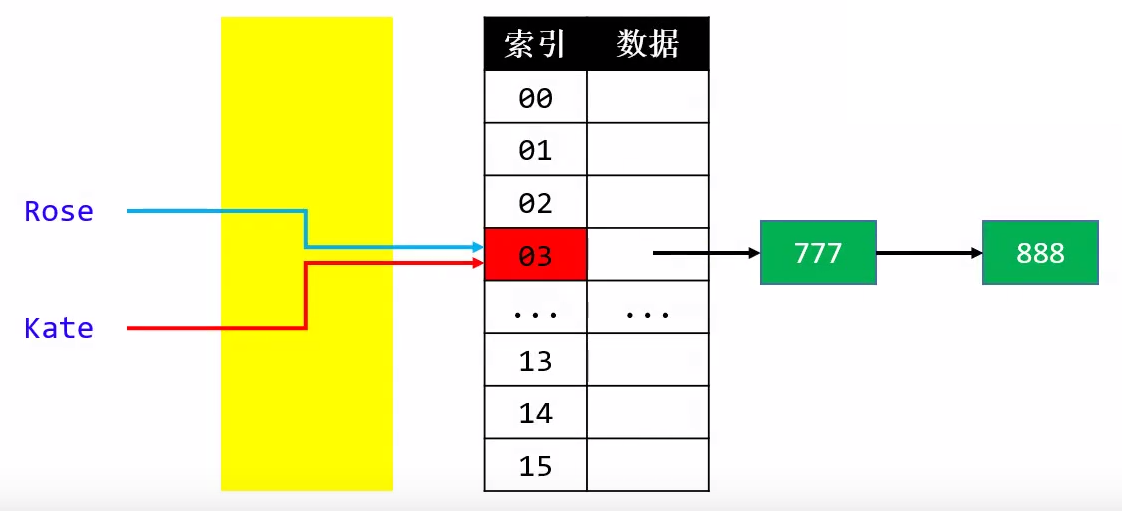
- 比如通过链表将同一index的元素串起来
- 1.开放定址法(Open Addressing)
JDK1.8的哈希冲突解决方案
- 默认使用单向链表将元素串起来
- 在添加元素时, 可能会由单向链表转为红黑树来存储元素
- 比如当哈希表容量 >= 64 且 单向链表的节点数量 > 8 时
- 当红黑树节点数量少到一定程度时, 又会转为单向链表
- JDK1.8中的哈希表是使用链表+红黑树解决哈希冲突
- 思考: 这里为什么使用单链表?
- 1.因为需要遍历链表中的key是否是要添加的key, 如果是同一个key, 则覆盖value, 如果比较到最后面都没有相同的key, 则直接将新添加的key value插入到链表的尾部.
- 2.没有往前走的操作, prev 指针没用, 所以为了节省内存空间用单向链表
哈希函数
-
哈希表中哈希函数的实现步骤大概如下
-
1.先生成 key 的哈希值(必须是整数)
-
2.再让 key 的哈希值跟数组的大小进行相关运算, 生成一个索引值
-
public int hash(Object key) { return hash_code(key) % table.length; }
-
-
为了提高效率, 可以使用**&位运算取代%**运算 ( 前提: 将数组的长度设计为 2 的幂 (2^n) )
-
public int hash(Object key) { return hash_code(key) & (table.length - 1); } /*因为 10101 & 00111 ------- 00101 所以最后算出来的结果一定是 <= 111即数组的最大下标 生成的值的范围是 000~111 所以任何一个值 & 上111, 最终结果是000~111 */ -
良好的哈希函数
- 让哈希值更加均匀分布 -> 减少哈希冲突次数 -> 提升哈希表的性能
如何生成 key 的哈希值
- key 的常见种类可能有
- 整数, 浮点数, 字符串, 自定义对象
- 不同种类的 key, 哈希值的生成方式不一样, 但目标是一致的
- 1.尽量让每个 key 的哈希值是唯一的
- 2.尽量让 key 的所有信息参与运算(减少哈希冲突)
- 在Java中, HashMap 的 key 必须实现 hashCode, equals 方法, 也允许 key 为 null
整数
-
整数值当做哈希值
- 比如 10 的哈希值就是 10
-
public static int hashCode(int value) { return value; }
浮点数
-
浮点数在内存中是怎么存储的?
- 十进制8.25的二进制是1000.01
->1.00001*2^3(3指数, 00001尾数)
因为十进制的小数点后0.1是10分之1
0.01是100分之1即10^2分之1
所以二进制的小数点后0.1是2分之1
0.01是4分之1即2^2分之1
十进制1000.01->1.00001*10^3
二进制1000.01->1.00001*2^3
浮点数中1.x*2^y也就是说1是固定的,2也是不变的,所以在内存中不用存储,在内存中只存有x和y也就是尾数和指数,当然还有符号位
- 十进制8.25的二进制是1000.01
-
将存储的二进制格式转为整数值
-
public static int hashCode(float value) { return floatToIntBits(value); }

Long 和 Double 的哈希值
-
因为在Java中规定哈希值必须是int类型, 即32位
-
public static int hashCode(long value) { return (int) (value ^ (value >>> 32)); } -
public static int hashCode(double value) { long bits = doubleToLongBits(value); return (int) (bits ^ (bits >>> 32)); } -
>>> 和 ^ 的作用是?
- 高32bit 和 低32bit 混合计算出 32bit 的哈希值
- 充分利用所有信息计算出哈希值

-
为什么要用 ^ ?
-
如果用的是&: 以上图为例, 结果直接是低32位的数据, 相当于直接用了低32位的数据作为哈希值. 相当于没算
-
如果用的是 | : 以上图为例, 结果全是1, 相当于直接用了高32位的数据作为哈希值
-
所以只有 ^ 才能办到是拿低32位和高32位混合运算出不同的数据
字符串的哈希值
-
整数 5489 是如何计算出来的?
5 * 10^3 + 4 * 10^2 + 8 * 10^1 + 9 * 10^0
-
字符串是由若干个字符组成
- 比如字符串jack , 由 j、a、c、k 四个字符组成 (字符的本质就是一个整数)
- 因此, jack的哈希值可以表示为
j * n^3 + a * n^2 + c * n^1 + k * n^0, 等价于[(j * n + a) * n + c] * n + k - 在JDK中, 乘数n为31, 为什么使用31?
- 31是一个奇素数, JVM会将 31 * i 优化成 (i << 5) - i
static void test() {
String string = "jack";
int len = string.length();
int hashCode = 0;
for (int i = 0; i < len; i++) {
char c = string.charAt(i);
hashCode = hashCode * 31 + c;
// hashCode = (hashCode << 5) - hashCode + c;
}
}
关于31的探讨
31 * i = (2^5 - 1) * i = i * 2^5 - i = (i << 5) - i- 31不仅仅是符合2^n - 1, 它是个奇素数(即使奇数, 又是素数)
- 素数和其他数相乘的结果比其他方式更容易产生唯一性, 减少哈希冲突
- 最终选择31是经过观测分布结果后的选择
自定义对象的哈希值
- 如果不实现hashCode方法, 默认是沿用基类Object的实现(与内存地址有关)