 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
引言
这篇文章看题目像是技术专家的经验分享,但事实上其实只是我个人的臆想,掺杂了网上一些博客文献的想法。因为我并没有进行任何的测试,所以可能只是天方夜谭而已。
优化策略
这些优化大多是工业实现上的优化,而不是算法本身的优化,对于每一个点我尽量给出如果是我实现的话我的做法是什么,我会是得这些方法尽量具有可行性。
Append Log与日志存储的并行化
其实就是把Append Log 与日志项的持久化并行执行。raft日志天然有序,就目前的硬盘存储介质来说顺序写还是要远优于随机写的。一般来说日志的持久化就相当于WAL,整体是顺序的。并行化这种方案在极端情况可能会造成随机写,比如下面的情况:
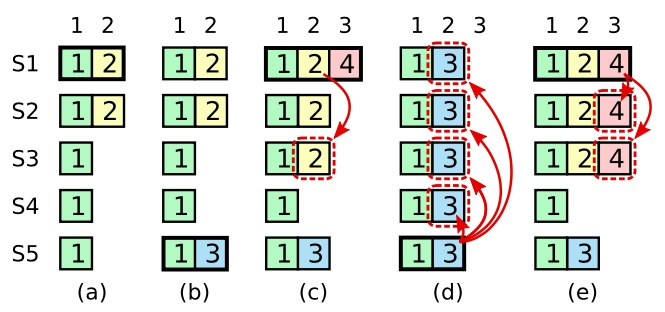
(c)中2(当然仅S1,S2落盘),3日志项已经落盘,在(d)内会全部覆盖掉。
但是这样做不会对安全性造成影响。如果Leader没有Crash,那么和顺序的处理结果一致。如果Leader Crash了,那么如果大于n/2+1的follower收到了这个消息并Append成功,那么这个Raft Log就一定会被Commit,新选举出来的Leader会响应客户端;否则这个Raft Log就不会被Commit,它会被新的日志覆盖掉。
Batching & Pipelining
显然这两种方法一定可以提升性能,不过真正难的地方在于如何保证正确性,我们分别从场景和正确性来讨论下这两者。
首先是在哪些地方应用这两个优化策略,先聊应用,再谈正确性。
Pipelining:
- 这里的优化是必要的,不然整体日志的处理不仅是线性的,而且每个请求处理之间还有一个RTT,当RTT不小时性能一定好不到哪里去。
- Pipelining的过程可以开多个线程,并行发送,接收方通过下标保证有序。
Pipelining为了保证正确性我们必须做到两点:
- 使得每一个结点所有的请求处理有序,且顺序一致。
- 需要处理连接失败的请求,与滑动窗口的过程有点类似,不过在index为T的日志项收到之前,T之后的日志项就算到了也不能应用。在Follower收到Append消息的时候,会检查是不是匹配已经接收到的最后一个Raft Log,如果不匹配,就返回Reject消息,那么按照Raft协议,Leader收到这个Reject消息,就会从3重试,4也会发送,这种情况出现的概率毕竟不大,所以额外的重试个人认为不会有太大的问题。
Batching:
- 我们可以应用在客户端提交提案的时候,把多个提案合并为一个显然性能更优,可以减少很多个RTT。
- 在append log的时候可以合并多个请求,不过这也是基础raft所做的事情。
- 当然落盘也可以批处理。
请求批处理这里可能出现的问题就是一批中执行到一半的时候出现宕机,导致一批数据其实只完成了一部分,个人认为最简单的方案就是把这几个请求放到一个日志内,其实也相当于一个请求了,然后再全部完成以后再返回commit。也就是说没有commit之前宕机可能会使得此机器内的数据结构不完整,但是它已经宕机了,这并没有什么关系,所以我们可以先写入磁盘,再写入数据结构,Follower也是一样的做法,Leader最后收到大多数回复的时候再返回请求,这样就可以了。只是简单一想,可能有些地方不太完善。
复用连接
一个机器内部可能存在着多个raft-group,因为每个group中的所有副本都会建立连接,所以多台机器之间可能会存在多个TCP,每个连接的开销其实是比较大的,连接的开销在这里不细谈。所以就raft部分来说可以每个机器之间仅有一个连接,每个raft-group有一个唯一标号,这样每个包就可以交给不同的group了。
这个看起来不难,我个人认为实现起来还是比较麻烦的,多个线程需要共用这个连接。简单的方法是一个线程从这个连接接收数据,然后把数据发送到不同的接收线程。这里是一个单写者多读者的场景。当然更为优雅的方式我认为是这个单线程从连接接收数据,维护raft-group个kfifo,把不同的数据放入不同的kfifo中,这样就优雅的完成了无锁的分发过程。
日志压缩的分片
在ChubbyGo的实现中在日志压缩时没有实现分片的功能,但是因为日志落后的可能性比较低,所有发送全部的日志显得十分不优雅,所以分片是一个很必要的做法,raft原始论文的第七节描述了这个优化。
心跳包合并
心跳包是为了保证机器之间的连通性,显然一台机器的多个raft-group没有维护多个连接没有什么意义。raft的heartbeat合并,当一个节点上的Raft-Group的很多的时候,可以省掉大量的心跳包。
这里也意味着心跳包的回调函数中我们需要修改多个raft-group的定时器,当然这里回调的参数设置也估计比较麻烦,因为这个心跳处理过程是独立于raft-group的,需要传递一些参数才能修改,当然这些raft-group还得是一个进程内部的。目前想不到其他的细节问题了。
日志的存储
这个部分是ChubbyGo的痛点,当时持久化的设计现在看来简直可以用稀烂来形容。
正确的做法应该是基于WAL的过程。
一般的流程如下:
- raft接到一个数据
- 持久化
- 请求commit
- commit成功
- 上层应用执行日志
这样可以保证如果commit成功,数据会持久化在集群中的大多数结点中。
一般的状态转化是这样的,绿色为in-memory,蓝色为in-disk:

但是当上层数据真的applied应用时,数据并不在内存中,这需要一次IO,而磁盘IO是一个性能杀手,毫秒级别的操作(当然没考虑page cache),所以我们可以维护一个用户态的cache,以此提升性能。
这里cache的组织形式我个人认为其实一个数组和一个压缩点下标就OK了。
读优化 ReadIndex与LeaseRead
如果每个读操作都需要跑一遍raft流程的话就太慢了,所以可以参考zk提供一个客户端FIFO的语义,每个客户端在请求中携带一个ReadIndex,要求日志必须大于这一点才可以返回,这样的话可以满足一个客户端FIFO的语义,且单个从节点就可以执行请求。
要做到等待预期ReadIndex的功能的话还需要对每一个到来的数据包跑回调,目标值出现的时候调用一系列回调,类似与内核的等待队列,上面挂了一堆进程,预期事件一到,全部都被触发。
当然要保证强一致性的话也可,就是仅主节点可以接收读请求,比起读操作跑一遍流程来说这种Readindex的方案就快多了,当然LeaseRead是一种对于前者的优化。当然只在leader的话其实一般来说不会出现请求index大于目前实际index的情况,所以基本是wait-free的。
PreVote
为了避免一个分区的结点term暴增,进而在分区结束以后影响整个协议(Term较高的结点称为leader),可以引入PerVote机制解决问题,简单来讲就是在身份转化为Candidate之前引入一个新的状态,即PreCandidate,它的作用是发送一个预选举包,其中Term为自身Term+1,注意现在结点真实Term并不增加,在收到大多数结点的回复以后才进行真正的选举,此时也真正的自增Term。
这种机制很好的避免了前面提到的问题,就是选举开销多了一轮消息广播,其实问题并不是很大,因为leader宕机本来就不是一个常见的事情。
当然在实现细节上来说我们要能区分预选举和选举这两个包的区别,因为在一般选举包中检测到对端Term较高会直接设置自己的Term为对端Term大小。当然这也不难,包中打上一个标记位就可以了。
snapshot管理
这个问题海东哥在模拟面试我的时候有问道,当时讲出了分片,压缩以及和redis一样的多线程优化网络IO。
再回过头来看这个问题,一个安装快照的RPC中如果把一个快照全发送过去有以下几个问题:
- 一个RPC的数据量太大,对内存是一个挑战,而且可能出现网络IO瓶颈。
- 如果失败,整体重试代价太大(是否有想到Dynamo中merkle树的使用)。
- 难以流控。
在Elasticell的Multi-Raft实现中对这个问题有以下优化步骤,使得重试代价降低,流量也更加平均(当然在真的发现网络IO是是瓶颈的时候才有效,不过一个快照随便几个G不过分吧,一个千兆网卡的吞吐不过125mb/S,瓶颈出现在网络IO的概率还是很大的):
- Raft的snapshot RPC中的数据存放,snapshot文件的元信息(包括分片的ID,当前Raft的Term,Index,Epoch等信息)
- 发送Raft snapshot的RPC后,异步发送具体数据文件
- 数据文件分Chunk发送,重试的代价小
- 发送 Chunk的链接和Raft RPC的链接不复用
- 限制并行发送的Chunk个数,避免snapshot文件发送影响正常的Raft RPC(网卡吞吐毕竟是有上限的)
- 接收Raft snapshot的分片副本阻塞,直到接收完毕完整的snapshot数据文件(不清楚这样有什么用)
Multi-Raft
宗岱大佬在面试时问到了我这个问题,其实这不是第一次了,遥记得欢神在去年来小组的时候也和我提到过这个,不过后来因为琐事缠身,没有仔细的思考过这个问题。好在最近面试已经趋于平稳,总算是有时间去思考了。
首先致命三连,是什么?为什么?能干什么?
这里引用Cockroach对Multi-Raft的定义[5][10],解释了前两点:
- In CockroachDB, we use the Raft consensus algorithm to ensure that your data remains consistent even when machines fail. In most systems that use Raft, such as etcd and Consul, the entire system is one Raft consensus group. In CockroachDB, however, the data is divided into ranges, each with its own consensus group. This means that each node may be participating in hundreds of thousands of consensus groups. This presents some unique challenges, which we have addressed by introducing a layer on top of Raft that we call MultiRaft.
- The more nodes, the worse the performance
The system storage capacity depends on the size of the leader machine’s disk
- 在CockroachDB中,我们使用Raft共识算法来确保即使机器出现故障,您的数据也保持一致。 在大多数使用Raft的系统中,例如etcd和Consul,整个系统是一个Raft共识组。 但是,在CockroachDB中,数据分为多个范围,每个范围都有自己的共识组。 这意味着每个节点可能正在参与成千上万个共识组。 这提出了一些独特的挑战,我们通过在Raft之上引入一个称为MultiRaft的层来解决这些挑战.
- 节点越多,性能越差。系统的存储容量取决于主机(leader)磁盘的大小。
而TiKV中对Multi-raft的定义在[8]中非常清楚:
- If you’ve researched Consensus before, please note that comparing Multi-Raft to Raft is not at all like comparing Multi-Paxos to Paxos. Here Multi-Raft only means we manage multiple Raft consensus groups on one node. From the above section, we know that there are multiple different partitions on each node, if there is only one Raft group for each node, the partitions losing its meaning. So Raft group is divided into multiple Raft groups in terms of partitions, namely, Region.
如果你之前研究过共识,你需要清楚,将 Multi-raft 与 raft 进行比较根本不像将 multi-Paxos 与 Paxos 进行比较。 在这里,multi-raft 协议仅意味着我们在一个节点上管理多个raft共识组。 从上一节中,我们知道每个节点上有多个不同的分区,如果每个节点只有一个Raft组,则这些分区将失去其含义。 因此,筏组根据分区(即区域)分为多个raft组。- TiKV also can perform split or merge on Regions to make the partitions more flexible. When the size of a Region exceeds the limit, it will be divided into two or more Regions, and the range may change like [a, c)[a,c) -> [a, b)[a,b) + [b, c)[b,c); when the sizes of two sibling Regions are small enough, they will be merged into a bigger Region, and the range may change like [a, b)[a,b) + [b, c)[b,c) -> [a, c)[a,c).
TiKV还可以在Regions上执行拆分或合并,以使分区更加灵活。 当区域的大小超过限制时,它将被分为两个或多个区域,范围可能会像[a,c)-> [a,b)+ [b,c); 当两个同级区域的大小足够小时,它们将合并为一个较大的区域,并且范围可能会像[a,b)+ [b,c)-> [ a,c)。
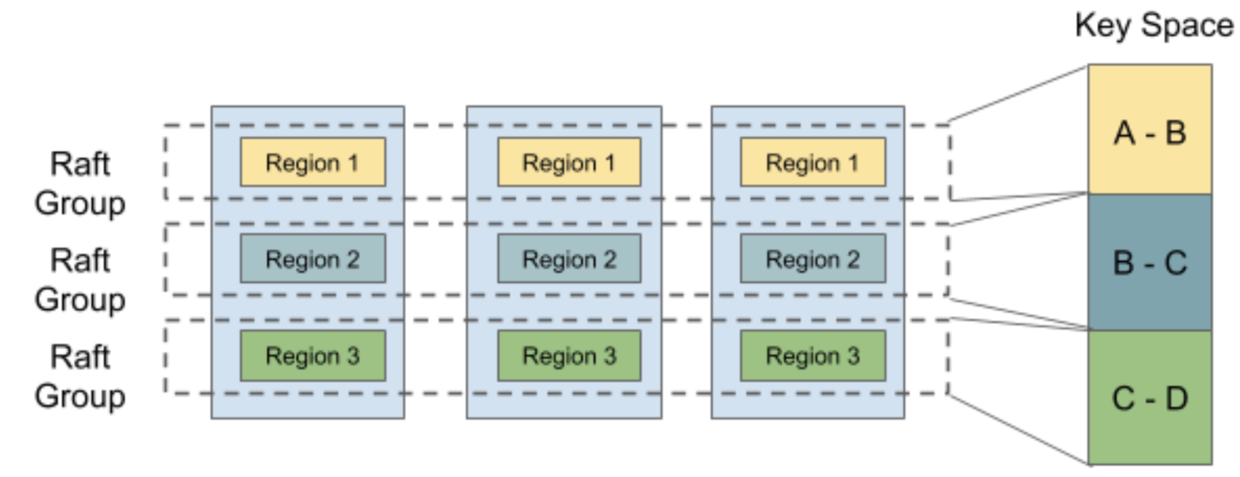
这种分片最主要的原因还是在KV场景下单个Raft很容易出现以下问题:
- 单机算力瓶颈(为了强一致性仅Leader可以处理写请求)
- 单机存储瓶颈(当然像bigtable一样使用分布式存储系统做存储引擎的除外)、
- 不能做到所有节点皆可提供服务。
以上问题的解决方案可以是分片,而multi-raft就是基于分片来做的。这样不但使得算力和存储的上限提高,也可以把以前串行的操作并行起来。因为一个结点可以是leader也可以是Follow,相当于大片机器宕机仍能保证大多数服务正常运行。
就像[5]中所说,很多核心问题需要被解决,如下:
- 如何分片:我认为一致性哈希是一种可取的方案。TiKV中可以基于hash和range。
- 分片中的数据越来越大,需要分裂产生更多的分片,组成更多Raft-Group。
- 分片的调度:让负载在系统中更平均。Cockroach在调度部分参考TiKV的PD。这里PD负责调度指令的下发,其中有两个最重要的资源,即存储 storage 以及计算 leader。PD通过心跳收集调度需要的数据,这些数据包括:节点上的分片的个数,分片中leader的个数,节点的存储空间,剩余存储空间等等。
- 新的分片如何形成一个raft-group。
以上问题在[5]中有详细的解答。
不过此时还是有一些疑惑:
- PD本身是否会成为单点呢?
- 两个分区可能合并,既然在日志超过一个区间才会分离,难道每个raft-group会进行日志压缩,如果是这样的话如何同步主从之间日志压缩的时间呢,还是各压缩各的,最后均已leader为主呢?这里的细节不是一时半会可以搞定的。
如此看来Multi-raft应用分片使得整体的吞吐大幅度提高,不过这看起来更像是工业级优化而不是算法级优化。
总结
大都是工业细节上的优化,算法级别的优化网上没有找到多少资料。可能像Multi-Paxos一样属于各大公司的机密吧。