 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
这个问题出现在阿里一面中,说实话这问题一问就知道是电话那头是个高手了。不出所料,这个问题我没答出来,其实要是有提醒的话可能还有点机会,这种看着没见过名词猜意思确实有点麻烦。
经过一些资料的查询,面试官所谓的写放大现象应该说的就是OS实际进行的IO次数大于用户态执行的IO次数。这其实是由于文件系统在磁盘中的组织结构造成的。使用df -T可以查看当前系统下的文件系统格式,一般Linux上ext4比较多。
ext4文件系统

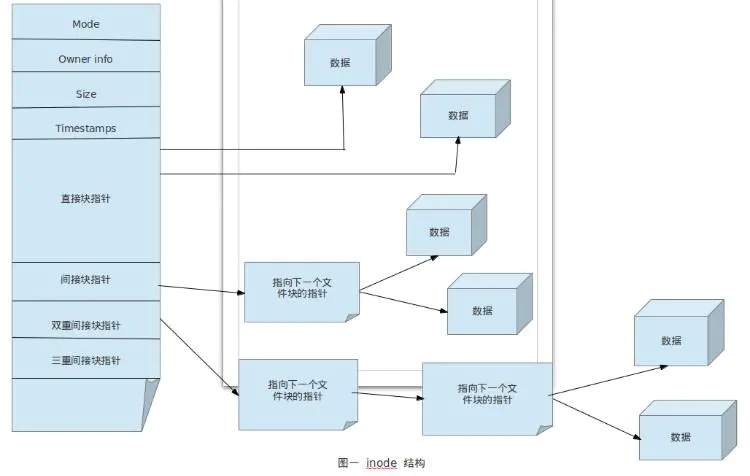
上图是ext4文件系统的基础架构图。
可以输入df查看机器上的各个文件系统,然后调用dumpe2fs -h /dev/sda10 | grep node查看与inode相关的数据,调用tune2fs -l /dev/sda10 | grep "Block size"查看block大小,当然硬盘的名称根据不同的机器进行替换。
更详细的部分可以参考[4],不过这两幅图足以让我们了解ext4的大概架构过程了。
不过此时我们应该可以敏锐的发现如果要找到某个特定的inode中的数据,尤其是偏移量较大的数据,貌似一次是没办法找到的,需要多次的入盘才可以得到,这样可能导致用户态的一次IO操作造成了操作系统实际多次的IO操作。
至于磁盘物理块到逻辑块之间的转换可以参考[9],ext4文档可以参考[10]。
写放大现象重现
我们来尝试复现一下这个过程,首先生成多个大文件。然后每次偏移读,同时每次刷新缓存。简单的代码如下:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string>
#include <vector>
#include <iostream>
using std::string;
using std::vector;
int main(){
int FileName = 0;
vector<int> arr;
arr.reserve(500);
constexpr int len = 1024*1024*1024;
// 硬盘上没空间了,所以只生成了10个文件,想要结果更准确且机器允许的话可以生成500个向上。
for (size_t i = 0; i < 10; i++){
int fd = open(std::to_string(i).c_str(), O_RDWR | O_CREAT | O_DIRECT, 0755);
arr.push_back(fd);
char *buf;
size_t buf_size = len;
posix_memalign((void **)&buf, getpagesize(), buf_size);
int ret = write(fd, buf, len);
if(ret != len){
std::cerr << "Partially written!\n";
}
}
for(auto x : arr){
close(x);
}
return 0;
}
循环读取这十个文件,每次sync,为了模拟多个大文件,机器差的苦日子啊。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string>
#include <vector>
#include <iostream>
using std::string;
using std::vector;
int main(){
vector<int> arr;
arr.reserve(500);
constexpr int len = 1024;
for (size_t i = 0; i < 10; i++){
int fd = open(std::to_string(i).c_str(), O_RDONLY | O_DIRECT, 0755);
std::cout << fd << std::endl;
arr.push_back(fd);
}
for (size_t i = 0; i < 1000; i++){
int index = i%10;
lseek(arr[index], 1024*1024*512, SEEK_SET); // 转移偏移量
char* buf;
posix_memalign((void**)&buf, getpagesize(), 1025);
std::cout << arr[index] << std::endl;
size_t buf_size = len;
int ret = read(arr[index], buf, buf_size);
if(ret != buf_size){
free(buf);
std::cerr << "Partially written!\n";
continue;
}
free(buf);
sync();
}
for(auto x : arr){
close(x);
}
return 0;
}
首先在代码中可以看到在用户态我们共执行了1000次IO操作,读取的数据总量为1000KB。
在代码执行的时候可以调用iostat -d 1,功能就是每一秒执行一次iostat,如果想指定操作数就在1后面再加上执行上限,像前面不加的话就是执行次数无上限。

我们可以看到操作系统共执行了大概2500次IO,数据总量为4000KB左右。
我们把Direct IO改成正常的IO过程,也就是把open里面的O_DIRECT参数去掉,然后内存分配改为malloc,继续监测IO:

IO次数为1200次,但是明显可以看到读取的数据量变小了很多,即40KB,十个文件,再考虑上面的4倍,显然它们之间有一些关系,我个人认为是这样的,ext4的组织结构我们在上面已经看过了,在block为4096字节的情况下要存一个G的文件需要一个双间接索引来存,也就是说相比于直接IO这里需要两次额外IO,在加上开始要在磁盘上找到此inode,最后需要在数据block中读取数据。
至于为什么tps还是1000,因为我并没有去掉sync,这也是写入字节数非常大的原因,如果去掉sync,因为这个文件数据现在还存在在page cache,所以可以预料到的读取数据会比较小,tps也会比价小。
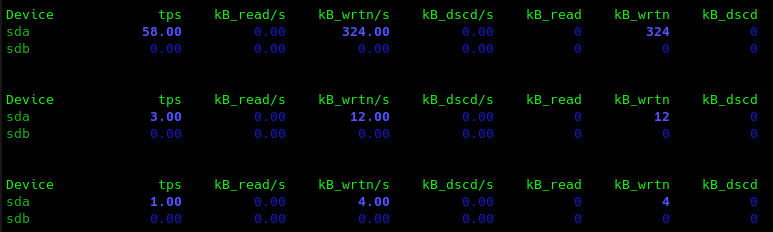
符合预期。
总结
经过上面探究和对[3]这篇的文章的学习,基本上可以把Direct IO出现写放大的现象的原因定位到文件系统的实现上,因为每次Direct IO如果都是不同的文件的话意味着我们需要在进行多次额外的IO操作以获得数据的实际存储位置,虽然这些数据被缓存,但是下一次并不能使用到,所以导致额外的IO数大幅度提升。在ext4的1G大小文件中已经是4倍这个恐怖的数字了。
当然更细致的总结就是[3]中的最后三点了,防止原文丢失,这里记录下:
- ext3采用的文件索引方式在读偏移较大的时候会产生额外IO,而且偏移越大,额外IO次数越多;
- Linux采用了buffer cache缓存ext3的索引块,查找数据块位置会首先在缓存中查找索引块,缓存未命中需要从磁盘读取索引块;
- DirectIO时Linux内核发出的IO请求次数实际上与以下因素相关:a).逻辑块在物理磁盘上的连续性;b).应用程序缓冲区对齐粒度,编程中尽量做到以PAGE_SIZE对齐。
其实也可以看出一点,两种情况使用Direct IO比较合适,分别在读写两端。
写入即需要数据即刻入盘,防止掉电内存数据丢失,我们已经定位到写放大现象的原因在于cache和文件系统的实现,所以类似于WAL这样的场景不需要过于担心,因为磁盘的索引在第一次已经缓存了,后面的操作就是一次IO而已(相比于batching写入当然效率也比较低)。
读取即确定数据访问不遵循局部性的时候,当然fadvise也干了这样的事情。
结论不一定正确,如果发现错误还请麻烦指出。
参考: