 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
引言
这篇文章的目的在于记录Braft使用中一些API的具体含义,虽然有官方文档,但是还是感觉有点简略。运行并学习了代码以后和当时仅仅查看文档完全是两个不同的感受,遂简单记录下用到的一些接口。并引入一个官网的例子来了解Braft的实际执行过程。
文章首先描述一个使用Braft的样例,然后总结重要的API以及参数含义。
编译
这里Braft的文档已经非常完善了,没有什么必要再说详细过程,问题主要有两点,是我在编译过程中踩到的坑:
- Brat编译好以后把源码和动态库默认放在incubator-brpc/output中,我们需要把其中的代码和动静态库cp到系统路径中,比如/usr/include以及/usr/lib。不然会在make时报错。
- 在
example/counter和example/block中IP变量的获取是执行如下语句hostname -i | awk '{print $NF}',hostname -i的描述如下:Display the IP address(es) of the host. Note that this works only if the host name can be resolved. 但是有一个很重要的问题,即容器的网络模式默认是bridge,在这种模式下容器启动后会通过DHCP获取一个地址,这就导致hostname -i会生成两项,如下:
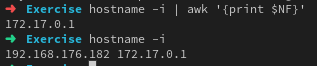
所以此时如果在本机跑的话就会出现问题,因为初始绑定的地址有问题,我们希望绑定到wlan0上,可是用上面的脚本就绑定到docker0上了。当然如果使用cpp代码写的话这种问题很好解决,只需要跑个自连接判断一下即可,但是如何用在shell中解决这个问题呢?其实问题的关键在于如何使得这个脚本在docker运行是取到docker0,在宿主机跑时取到wlan0,这是个问题。不过就跑测试来说直接把IP这个变量改成wlan0的IP就可以。这个问题我已经提了issue,编号为#287。
example:block
Braft的实现是建立在Brpc上的,所以实际上一般的使用流程是使用Brpc构建一个远程服务,然后构建一个业务逻辑实现braft::StateMachine,最后内部实现snapshot的具体存储逻辑。
这个例子是提供一个读写接口,客户端可以调用这个接口达到读写文件的作用。
proto文件的定义非常简单,如下:
syntax="proto2";
package example;
//在C++中protocol buffer编译器是否应该基于服务定义产生抽象服务代码
option cc_generic_services = true;
message BlockRequest {
required int64 offset = 1;
optional int32 size = 2;
}
message BlockResponse {
required bool success = 1;
optional string redirect = 2;
}
service BlockService {
rpc write(BlockRequest) returns(BlockResponse);
rpc read(BlockRequest) returns(BlockResponse);
};
要使用Brpc,我们首先需要继承braft::StateMachine,这个步骤主要是为了业务状态机可以和底层协议层解耦合,把业务逻辑的决策完全交由用户来实现。其中有以下几个接口非常的重要。
braft::Node::apply:这个实现了一个Raft日志项提交的过程,通常封装成一个braft::Task进行提交。on_apply:这个接口会在本地raft commit了某条(多条)日志的时候调用此接口,我们需要在这个接口实现业务状态机。on_snapshot_save:这个函数会在需要存储snapshot文件时进行调用,不过这里有一个巧妙的设计,就是其实这个接口本身并没有提供存储逻辑的实现,只是提供的一个把snapshot文件名存储到元数据的途径,即add_file接口。因为这个函数实现必然涉及磁盘操作,所以一般起一个线程做这件事,此时当然需要注意done->Run的异步触发过程。on_snapshot_load:可以把数据从snapshot以和save时一样的方式读出来,以此替换当前的状态机。
StateMachine中也实现了一个与Node状态变更相关的函数,可以用于业务逻辑的一些特殊需求:
on_shutdown:当raft Node被关闭的时候调用on_leader_start:一个副本结点变成leader以后调用,限定为在当前Term内。on_leader_stop:当结点不再为复制组的leader时执行。on_error:当遇到严重错误时,将调用on_error,此后,在错误修复并重新启动该节点之前,不允许对该节点进行任何进一步的修改。on_configuration_committed(const ::braft::Configuration& conf): 当复制组内的配置被提交的时候,目前猜测应该是成员变更和初始化的时候会打印。on_configuration_committed(const ::braft::Configuration& conf, int64_t index):on_stop_following:当Follow不再成为当前leader的副本时调用,源码注释中给出了三种情况on_start_following:当follower或者candidate开始follower 成为一个leader 的副本并修改了自己的leader_id的时候调用此函数。
首先在Block中声明Start函数,其中为Braft::Node初始化,可以想象到初始化至少需要IP:Port,以及一系列的基础配置信息。
int start() {
if (!butil::CreateDirectory(butil::FilePath(FLAGS_data_path))) {
LOG(ERROR) << "Fail to create directory " << FLAGS_data_path;
return -1;
}
std::string data_path = FLAGS_data_path + "/data";
int fd = ::open(data_path.c_str(), O_CREAT | O_RDWR, 0644);
if (fd < 0) {
PLOG(ERROR) << "Fail to open " << data_path;
return -1;
}
_fd = new SharedFD(fd); // RAII一下
butil::EndPoint addr(butil::my_ip(), FLAGS_port);
braft::NodeOptions node_options;
// conf的配置在run_server.sh中
if (node_options.initial_conf.parse_from(FLAGS_conf) != 0) {
LOG(ERROR) << "Fail to parse configuration `" << FLAGS_conf << '\'';
return -1;
}
// 选举超时时间
node_options.election_timeout_ms = FLAGS_election_timeout_ms;
// 所实现的StateMachine的指针,这里要求不能为空
node_options.fsm = this;
// If below item is true, fsm would be destroyed when the backing Node is no longer referenced.
node_options.node_owns_fsm = false;
// 多长时间执行一次快照,单位为秒
node_options.snapshot_interval_s = FLAGS_snapshot_interval;
// 存储各类数据的协议以及存储路径,分别为log数据,raft元数据以及快照数据, 协议部分curve中就实现了自己的协议
std::string prefix = "local://" + FLAGS_data_path;
node_options.log_uri = prefix + "/log";
node_options.raft_meta_uri = prefix + "/raft_meta";
node_options.snapshot_uri = prefix + "/snapshot";
// If true, RPCs through raft_cli will be denied.
node_options.disable_cli = FLAGS_disable_cli;
// 参数为集群名称与peer的地址
braft::Node* node = new braft::Node(FLAGS_group, braft::PeerId(addr));
if (node->init(node_options) != 0) {
LOG(ERROR) << "Fail to init raft node";
delete node;
return -1;
}
_node = node;
return 0;
}
当然既然读写接口是以RPC接口提供的,那么我们n显然必须先实现RPC部分的代码:
class BlockServiceImpl : public BlockService {
public:
explicit BlockServiceImpl(Block* block) : _block(block) {
}
void write(::google::protobuf::RpcController* controller,
const ::example::BlockRequest* request,
::example::BlockResponse* response,
::google::protobuf::Closure* done) {
brpc::Controller* cntl = (brpc::Controller*)controller;
return _block->write(request, response,
&cntl->request_attachment(), done);
}
void read(::google::protobuf::RpcController* controller,
const ::example::BlockRequest* request,
::example::BlockResponse* response,
::google::protobuf::Closure* done) {
brpc::Controller* cntl = (brpc::Controller*)controller;
brpc::ClosureGuard done_guard(done);
return _block->read(request, response, &cntl->response_attachment());
}
private:
Block* _block;
};
可以看到非常的简单,直接引用了Block中的成员,其中只有一个疑点,一般来说数据不是都应该存储在request中吗,这里竟然使用了request_attachment来获取请求数据,我们可以在brpc的文档中找到其作用,即:用户附加的数据或http请求的正文,它们直接连接到网络,而不是序列化为protobuf消息。
我们来仔细看一看:
void write(const BlockRequest* request,
BlockResponse* response,
butil::IOBuf* data,
google::protobuf::Closure* done) {
brpc::ClosureGuard done_guard(done);
// Serialize request to the replicated write-ahead-log so that all the
// peers in the group receive this request as well.
// Notice that _value can't be modified in this routine otherwise it
// will be inconsistent with others in this group.
// Serialize request to IOBuf
const int64_t term = _leader_term.load(butil::memory_order_relaxed);
if (term < 0) {
// 显示的重定向,把数据导向新leader;当on_leader_stop被调用的时候将_leader_term设置为-1
return redirect(response);
}
butil::IOBuf log;
// 获取元数据的长度
const uint32_t meta_size_raw = butil::HostToNet32(request->ByteSize());
// 向log中插入数据
log.append(&meta_size_raw, sizeof(uint32_t));
butil::IOBufAsZeroCopyOutputStream wrapper(&log);
// Write the message to the given zero-copy output stream. All required fields must be set.
if (!request->SerializeToZeroCopyStream(&wrapper)) {
LOG(ERROR) << "Fail to serialize request";
response->set_success(false);
return;
}
// 可以看到log中其实就是[长度+对应数据]
log.append(*data);
// Apply this log as a braft::Task
braft::Task task;
task.data = &log;
// This callback would be iovoked when the task actually excuted or fail
// 非常标准的一个异步调用brpc中的闭包范例
// 当然这里使用BlockClosure的作用我想就是把这些数据带到commit时使用
task.done = new BlockClosure(this, request, response,
data, done_guard.release());
if (FLAGS_check_term) {
// ABA problem can be avoid if expected_term is set
task.expected_term = term;
}
// Now the task is applied to the group, waiting for the result.
// 把数据插入raft状态机中开始执行,也就是apply,但是未commit,了解raft的同学应该理解这句话是什么意思
return _node->apply(task);
}
这里最引人注目的其实就是expected_term这个参数,因为源码注释中提到了ABA问题,此ABA并非CAS中的
ABAWEN,这个问题官网文档如下:
由于apply是异步的,有可能某个节点在term1是leader,apply了一条log,但是中间发生了主从切换,在很短的时间内这个节点又变为term3的leader,之前apply的日志才开始进行处理,这种情况下要实现严格意义上的复制状态机,需要解决这种ABA问题,可以在apply的时候设置leader当时的term.
这种情况可能会在某些特殊的场景下出现问题,比如幽灵复现的问题,不过在raft中这个问题是可以被解决的,解法就是在一个leader上任时插入一条新日志,这样可以把上个任期的数据全部删除掉,不过如果这个leader上任没来得及commit一条日志又挂了,且上一个任期的leader又上线,并commit了在那一个任期没有commit的日志,此时就出现了ABA问题,这个expected_term可以让使用者察觉到这种情况。
这里读接口比较特殊,没有走Raft协议,自然这样调用此接口的用户就没有办法使得此操作成为全局全序了。
当需要生成快照的时候会调用on_snapshot_save(想想上面的配置项),其中具体逻辑由用户实现。参数为接收一个braft::SnapshotWriter,由继承braft::SnapshotStorage的不同SnapshotStorage创建,这里看开始时配置的是什么协议,默认支持local,需要支持其他自定义协议需要自行注册,curve中的代码如下:
void RegisterCurveSnapshotStorageOrDie() {
static CurveSnapshotStorage snapshotStorage;
braft::snapshot_storage_extension()->RegisterOrDie(
"curve", &snapshotStorage);
}
我们来看看此样例中on_snapshot_save如何实现:
// 直接把入磁盘的操作写入逻辑中可能会阻塞线程,比如save_snapshot,所以需要跑一个线程异步执行这样耗时的任务
void on_snapshot_save(braft::SnapshotWriter* writer, braft::Closure* done) {
// Save current StateMachine in memory and starts a new bthread to avoid
// blocking StateMachine since it's a bit slow to write data to disk file.
SnapshotArg* arg = new SnapshotArg;
arg->fd = _fd;
arg->writer = writer;
arg->done = done;
bthread_t tid;
bthread_start_urgent(&tid, NULL, save_snapshot, arg);
}
// 这里理论来说需要执行真正的磁盘操作, 但是样例嘛,随意就好,只执行了一个fdatasync
static void *save_snapshot(void* arg) {
SnapshotArg* sa = (SnapshotArg*) arg;
std::unique_ptr<SnapshotArg> arg_guard(sa);
// Serialize StateMachine to the snapshot
brpc::ClosureGuard done_guard(sa->done);
std::string snapshot_path = sa->writer->get_path() + "/data";
// Sync buffered data before
int rc = 0;
LOG(INFO) << "Saving snapshot to " << snapshot_path;
for (; (rc = ::fdatasync(sa->fd->fd())) < 0 && errno == EINTR;) {
}
if (rc < 0) {
sa->done->status().set_error(EIO, "Fail to sync fd=%d : %m",
sa->fd->fd());
return NULL;
}
std::string data_path = FLAGS_data_path + "/data";
if (link_overwrite(data_path.c_str(), snapshot_path.c_str()) != 0) {
sa->done->status().set_error(EIO, "Fail to link data : %m");
return NULL;
}
// Snapshot is a set of files in raft. Add the only file into the writer here.
// local协议实现于/braft/src/braft/snapshot.h 中的 LocalSnapshotWriter
if (sa->writer->add_file("data") != 0) {
sa->done->status().set_error(EIO, "Fail to add file to writer");
return NULL;
}
return NULL;
}
local的add_file实现如下:
virtual int add_file(const std::string& filename) {
return add_file(filename, NULL);
}
int LocalSnapshotMetaTable::add_file(const std::string& filename,
const LocalFileMeta& meta) {
Map::value_type value(filename, meta);
std::pair<Map::iterator, bool> ret = _file_map.insert(value);
LOG_IF(WARNING, !ret.second)
<< "file=" << filename << " already exists in snapshot";
return ret.second ? 0 : -1;
}
当Raft数据项被Commit的时候会调用on_apply:
void on_apply(braft::Iterator& iter) {
// 可能一次提交多个数据项,迭代器的设计非常的巧妙
for (; iter.valid(); iter.next()) {
BlockResponse* response = NULL;
// This guard helps invoke iter.done()->Run() asynchronously to
// avoid that callback blocks the StateMachine
braft::AsyncClosureGuard closure_guard(iter.done());
butil::IOBuf data;
off_t offset = 0;
if (iter.done()) {
// 如果存在这样一个闭包的话
// This task is applied by this node, get value from this
// closure to avoid additional parsing.
BlockClosure* c = dynamic_cast<BlockClosure*>(iter.done());
offset = c->request()->offset();
data.swap(*(c->data()));
response = c->response();
} else {
// Have to parse BlockRequest from this log.
uint32_t meta_size = 0;
butil::IOBuf saved_log = iter.data();
// 从saved_log中取出第二个参数长的数据放入第一个参数的指针
saved_log.cutn(&meta_size, sizeof(uint32_t));
// Remember that meta_size is in network order which hould be
// covert to host order
meta_size = butil::NetToHost32(meta_size);
butil::IOBuf meta;
saved_log.cutn(&meta, meta_size);
butil::IOBufAsZeroCopyInputStream wrapper(meta);
BlockRequest request;
// 对应Write中的SerializeToZeroCopyStream
CHECK(request.ParseFromZeroCopyStream(&wrapper));
data.swap(saved_log);
offset = request.offset();
}
const ssize_t nw = braft::file_pwrite(data, _fd->fd(), offset);
if (nw < 0) {
PLOG(ERROR) << "Fail to write to fd=" << _fd->fd();
if (response) {
response->set_success(false);
}
// Let raft run this closure.
closure_guard.release();
// Some disk error occurred, notify raft and never apply any data
// ever after
iter.set_error_and_rollback();
return;
}
if (response) {
response->set_success(true);
}
// The purpose of following logs is to help you understand the way
// this StateMachine works.
// Remove these logs in performance-sensitive servers.
LOG_IF(INFO, FLAGS_log_applied_task)
<< "Write " << data.size() << " bytes"
<< " from offset=" << offset
<< " at log_index=" << iter.index();
}
}
好了基础的准备工作已经全部完成,我们来看看main函数中调用过程:
int main(int argc, char* argv[]) {
// 解析命令行参数,这里的命令行参数来源于shell脚本
GFLAGS_NS::ParseCommandLineFlags(&argc, &argv, true);
butil::AtExitManager exit_manager;
// Braft需要一个Rpc服务
brpc::Server server;
// 创建一个Block服务实体
example::Block block;
// 实现RPC的实体
example::BlockServiceImpl service(&block);
// 对于RPC来说是必须的操作
if (server.AddService(&service,
brpc::SERVER_DOESNT_OWN_SERVICE) != 0) {
LOG(ERROR) << "Fail to add service";
return -1;
}
// 这样的设计可以使得多个raft共享一个RPC服务,
if (braft::add_service(&server, FLAGS_port) != 0) {
LOG(ERROR) << "Fail to add raft service";
return -1;
}
// raft服务开始启动
if (server.Start(FLAGS_port, NULL) != 0) {
LOG(ERROR) << "Fail to start Server";
return -1;
}
// It's ok to start Block
if (block.start() != 0) {
LOG(ERROR) << "Fail to start Block";
return -1;
}
LOG(INFO) << "Block service is running on " << server.listen_address();
while (!brpc::IsAskedToQuit()) {
sleep(1);
}
LOG(INFO) << "Block service is going to quit";
block.shutdown();
server.Stop(0);
block.join();
server.Join();
return 0;
}
这里有一点需要提一下,即为什么这里stop和join需要分开,这里brpc文档中是这样写的:
Stop()不会阻塞,Join()会。分成两个函数的原因在于当多个Server需要退出时,可以先全部Stop再一起Join,如果一个个Stop/Join,可能得花费Server个数倍的等待时间。
源码中的注释是这样的:
Stop() is paired with Join() to stop a server without losing requests. The point of separating them is that you can Stop() multiple servers before Join() them, in which case the total time to Join is time of the slowest Join(). Otherwise you have to Join() them one by one, in which case the total time is sum of all Join().
其实我没能理解为什么,难道一个Server在stop之前另外一个server无法被stop吗?因为好像只有这样两个接口结合在一起并行才没用。
总结
不得不说这是一个非常实用的框架,其实brpc也值得一学,毕竟我觉得这是一个可以称之为国人之光,文档标杆的项目[7]。但是以目前的需求和精力来看学会用和调参已经很不错了,后面有时间了再去学习源码。这里先插个眼[8]。
参考: