DIN模型(Deep Interest Network)
DIN模型是阿里妈妈团队提出的CTR预估模型,虽然是几年前提出的,但是现在应用仍比较广泛。
原论文地址:Deep Interest Network for Click-Through Rate Prediction
对论文的核心总结:利用用户历史行为序列信息,使用类似Attetion的机制动态构建用户兴趣embeeding,使得模型能够捕获用户的兴趣。
该论文的主要贡献:
- 提出DIN模型,利用用户兴趣信息进行建模。
- 提出mini-batch aware regularization,MBA正则化,简化版L2正则,避免模型过拟合的同时,减少计算量,加快模型训练
- data adaptive activation function,数据自适应激活函数Dice。该激活函数可以根据数据的实际分布来动态调整系数。
模型结构
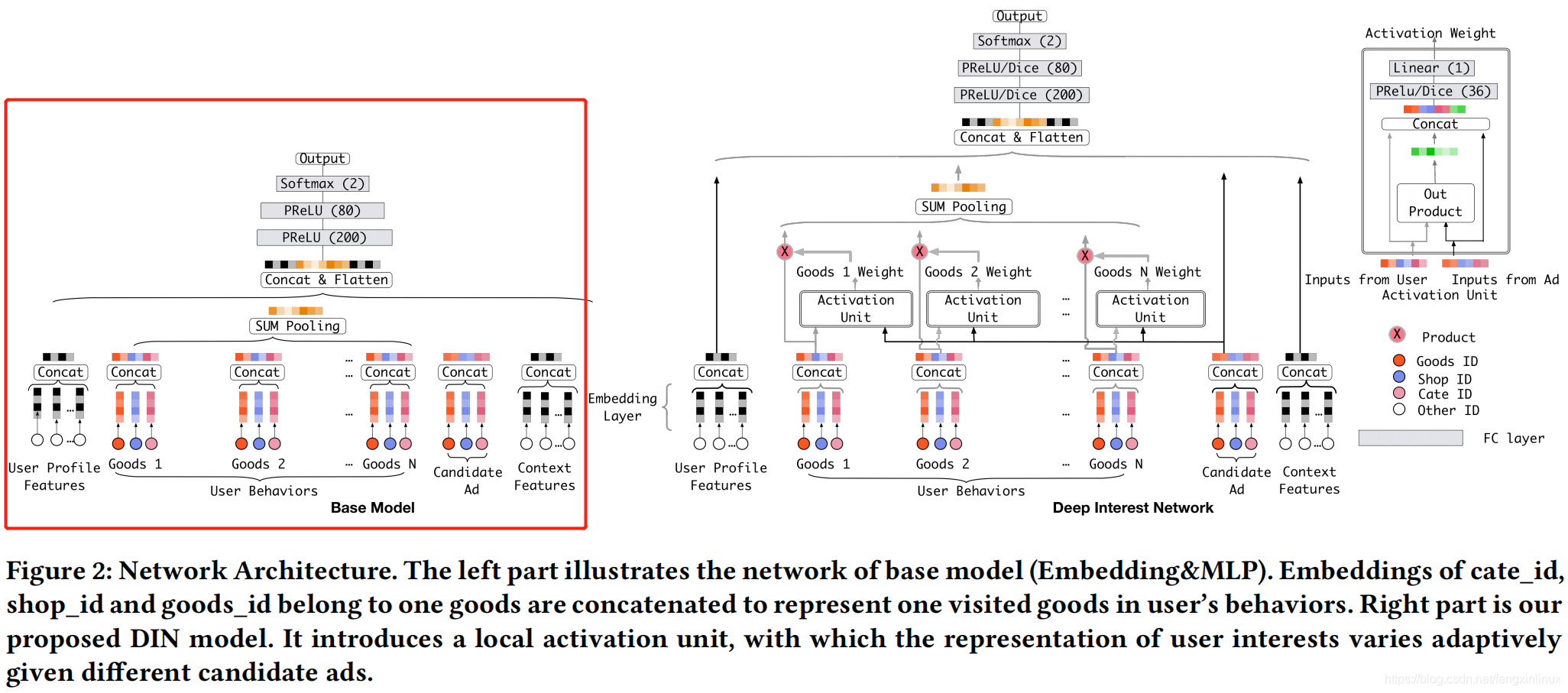
上图中,左边部分是Base模型,用来与DIN模型进行对比。可以看出,DIN的主要区别就在于对用户历史行为序列的处理,其实就是动态加权sum pooling的操作。所以,该模型的核心也就在于Activation Weight这个模块。
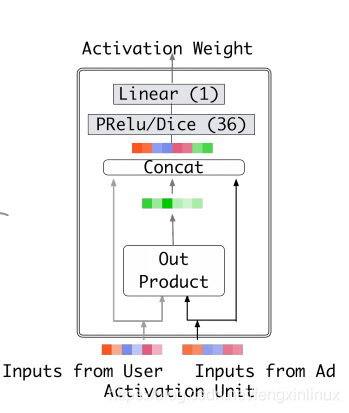
Activation Weight这个模块类似于门控机制,用来输出当前用户历史行为中每个商品对应的权重。
类似于Attention机制,该层的输入为当前商品的embedding以及广告对应的embedding,然后这两个embedding进行外积,得到一个结合的embedding,再将结合的embedding与商品、广告embedding进行拼接,最终拼接好的embedding进行全连接变化,输出权重值。
值得注意的是,该模块与传统的Attetnion机制不同,这里未使用softamax对打分进行归一化,这样做是为了更好区别兴趣程度,使得权重间的值差距更大。
得到用户历史行为embedding后,再与广告侧、上下文侧和用户侧的特征embedding进行拼接,经过多层的Dense变化,输出最终的CTR预测概率。
MBA 正则化
传统的L2正则化会对所有参数进行计算,这对于广告这种具有大规模稀疏特征的应用场景来说,会增加很大的计算开销。故作者提出改进版的L2正则化,在避免模型过拟合的同时,也加快了模型的训练速度,减少了计算开销。
传统的L2正则化公式,可以在mini-batch的训练方式中,等价转化为下面的公式:
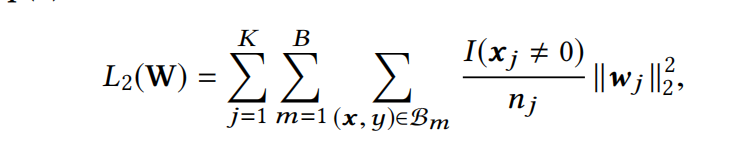
其中 n j n_j nj表示该特征j在总样本中出现的次数, I I I为指示函数,表明在当前batch的训练样本中,是否出现特征 j j j。
为了减少计算量,作者进行了以下的化简:

α m j α_{mj} αmj表示当前batch中,该特征 j j j是否出现过。即,对于每一批batch样本进行训练时,只对该batch中,出现过的特征对应的参数进行正则化,且与该特征在总样本中出现的次数相关。如该特征在数据中出现很多次数,则减少对该特征参数的惩罚力度。
数据自适应激活函数
Data Adaptive Activation Function
PReLU激活函数如下图所示:
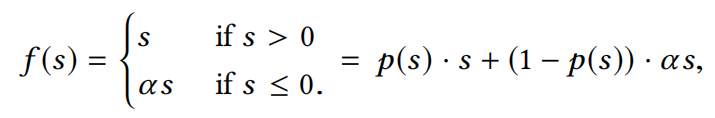
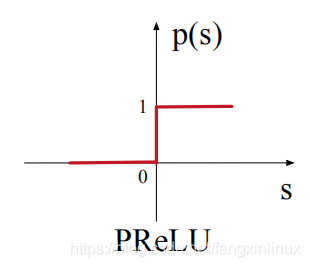
PReLU激活函数在0点处进行了强修正,rectified point固定为0,这在每一层的输入分布发生变化时是不适用的,所以文章对该激活函数机型了改进,平滑了rectified point附近曲线的同时,激活函数会根据每层输入数据的分布来自适应调整rectified point的位置。
DIEN模型(Deep Interest Evolution Network for Click-Through Rate Prediction)
原论文地址:Deep Interest Evolution Network for Click-Through Rate Prediction
DIEN模型是DIN模型的改进版本。已经有的DIN模型,它强调用户兴趣是多样的,并使用基于注意力模型来捕获目标项目的相对兴趣。但是用户的兴趣是不断进化的,而DIN抽取的用户兴趣之间是独立无关联的,没有捕获到兴趣的动态进化性。但是在电商推荐的场景下,用户的兴趣是不断变化的,故提出DIEN模型来捕获与目标商品相关商品的兴趣发展路径。DIEN最大的特点是不但要找到用户的interest,还要抓住用户interest的进化过程。
该文的主要贡献:
- DIEN关注兴趣演化的过程,并提出了新的网络结构来建模兴趣进化的过程。
- 设计了兴趣抽取层,并通过计算一个辅助loss,来提升兴趣表达的准确性。
- 设计了兴趣进化层,来更加准确的表达用户兴趣的动态变化性。
模型结构
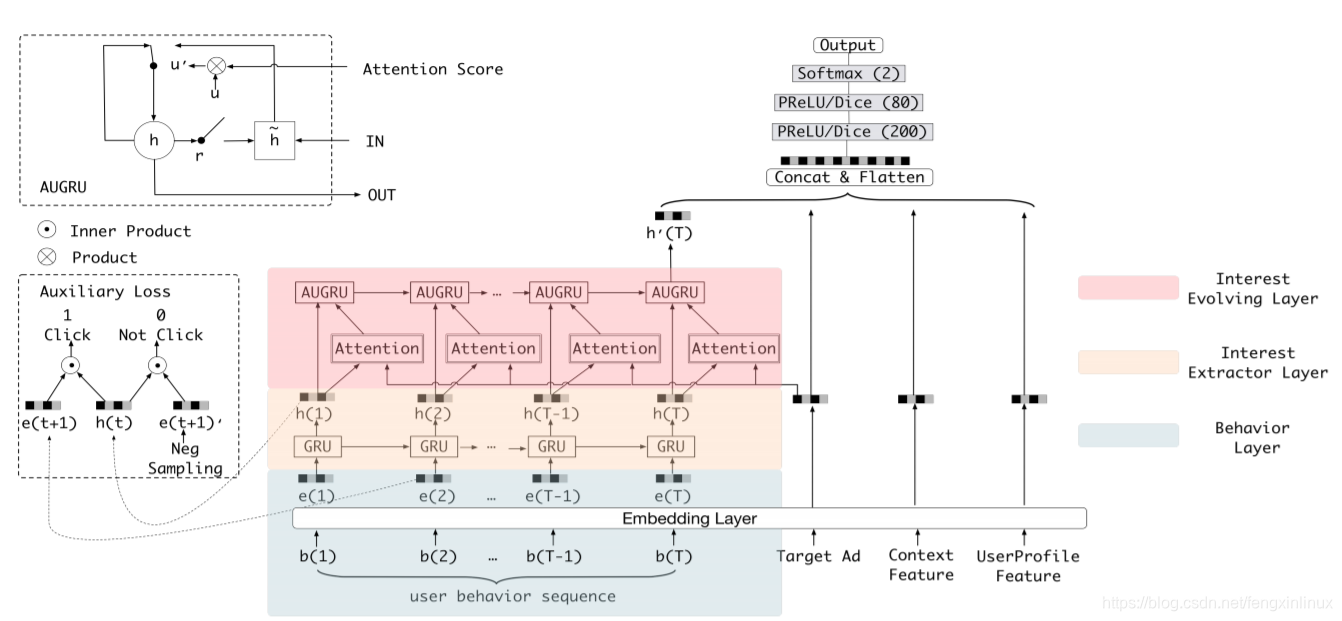
与DIN模型类似,DIEN的区别主要表现在对用户历史行为序列的embedding构建。
用户历史行为序列的embedding构建要经过三层:1.Dense embedding 2.兴趣抽取层 3.兴趣进化层
第一层其实就是一个Dense层,对商品进行embedding。
兴趣抽取层
与DIN相比,DIEN这一层引入了序列模型,因为上一时刻的行为,对下一刻的行为起重要决定作用,故引用序列模型会更好的表示用户的隐式兴趣。论文认为GRU比LSTM训练更快,故采用了GRU。
GRU输出h(t)如下所示:
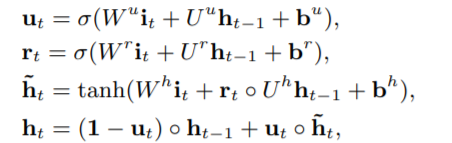
这里可以认为 h t h_t ht是用户的初步兴趣表示,每一步的兴趣状态会直接引导下一步的行为,为了更好地表达用户的兴趣,作者引入了辅助loss。
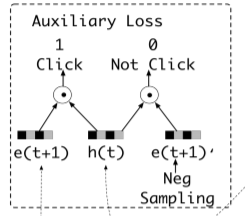
利用真实的下一个行为作为正样本,随机从行为序列中负采样得到负样本。用户下一时刻真实的行为 e t + 1 e_{t+1} et+1作为正例,负采样得到的行为作为负例 e t + 1 ′ e_{t+1}' et+1′,分别与抽取出的兴趣 h t h_t ht结合输入到设计的辅助网络中。
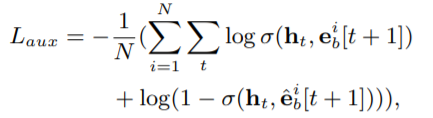
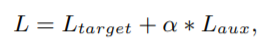
辅助Loss的好处:
- 更好的表达用户兴趣
- 类似引入多目标,增加辅助函数只增加了线下训练的成本,但并没增加线上serving时间。
兴趣进化层
随着外部环境和内部认知的变化,用户兴趣也不断变化。
兴趣在进化时,有两个特征:
- 多样性:兴趣漂移
- 独立性:虽然兴趣可能相互影响,但每种兴趣都有自己不断发展的过程
在兴趣抽取阶段,已经获取了用户的隐式兴趣表达,为了分析用户兴趣演化的特性,作者结合attention机制和GRU序列学习的能力去建模用户兴趣的演化。局部attention可以加强相关兴趣的影响,并减弱兴趣偏移的影响。
在attention阶段,使用的计算方式为:
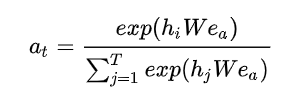
文章介绍几种将注意力机制和GRU结合起来模拟兴趣进化过程的算法:
GRU with attentional input (AIGRU)
这种方式将attention直接作用于输入,无需修改GRU的结构:
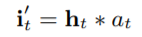
在AIGRU中,注意力得分可以降低较少相关兴趣的规模。 理想情况下,较少相关兴趣的输入值可以减少到零。但是,AIGRU有一定局限性, 因为即使零输入也可以改变GRU的隐藏状态。
Attention based GRU(AGRU)
这种方式需要修改GRU的结构,此时hidden state的输出变为:
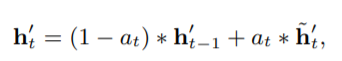
原来公式为:
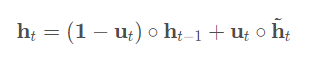
AGRU使用Attention score来代替GRU的 u t u_t ut(更新门),AGRU利用Attention score直接控制隐藏状态的更新。 并且在兴趣变化期间削弱了相关兴趣减少的影响。但是它使用标量(注意力分数 a t a_t at )来替换矢量(更新门 u t u_t ut),这忽略了不同维度之间的重要性差异。
GRU with attentional update gate (AUGRU)
因为前面几种方式都有不同的缺陷,所以又提出了一种更好的:
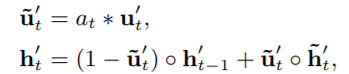
DIEN使用AUGRU。得到兴趣进化embedding后,将其连接其它的信息(广告侧特征、上下文信息等等)并最后送入MLP进行最终CTR预测。