概述
当我们写一条sql执行语句的时候,我们对它的执行计划以及所用到的索引都是自己进行判断的, 大多数时候我们的判断可能是正确的,但偶尔也会有出入,所以我们就要用到explain去查看mysql到底是怎么执行这条sql的。
举个例子
下图是两种表结构:
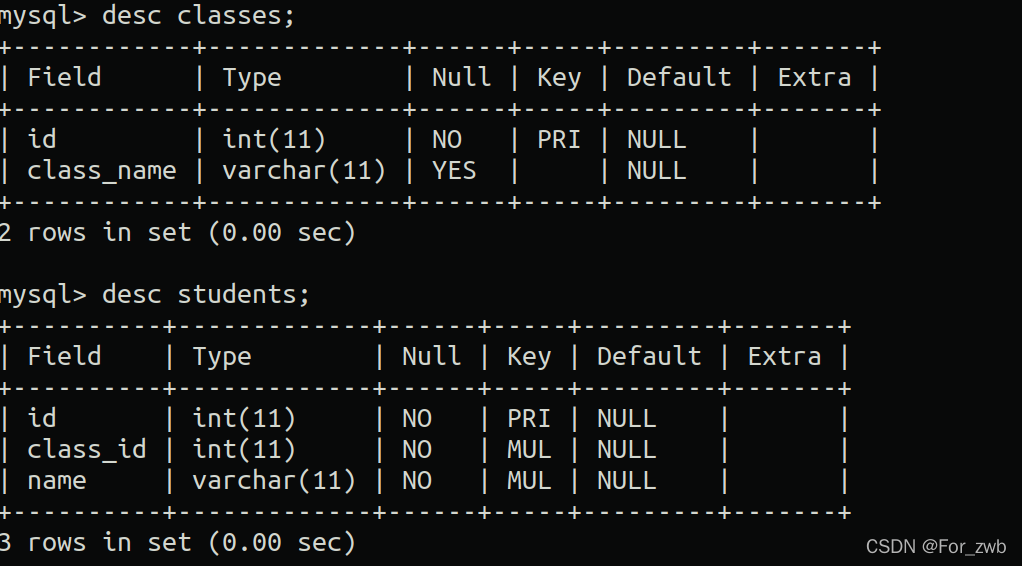
表一 classes,表二 students的数据
我们执行一条联结查询语句:
select name from students join classes on students.class_id=classes.id;
首先我们来自己分析一下这条语句的执行计划:
- 表students 在class_id上有普通索引,表classes在id上有主键索引
- 是内联结 join,驱动表的选择对我们来说没有什么影响。
- 所以最终的执行计划就是走两个表的索引找到匹配的数据,然后再返回name这一字段值。
那真正的执行计划是什么呢? 我们用explain来看一下
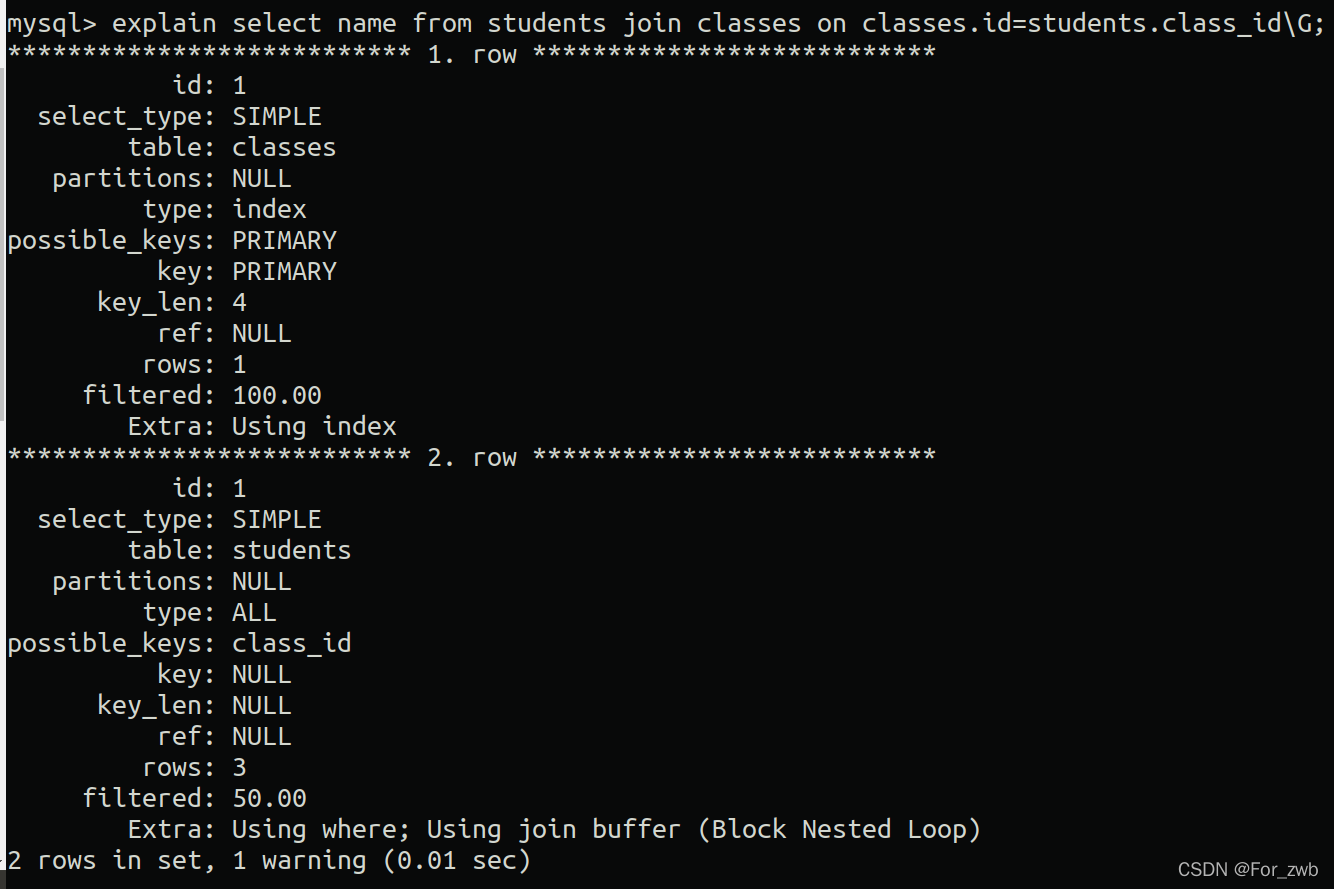
我们发现在students表中没有用到任何索引,而是采用全表扫描的方式来筛选数据。 那思考一下这是为什么呢?
下述是我思考的几个点,也欢迎大家讨论。
- 首先我们查找的字段name在students表中是没有任何索引的,所以查找该表必须回到主键索引上找到数据。如果走普通索引查找,还会有一次回表查询的开销。
- 我们表中的数据非常少,全表扫描性能也不差。
基于以上两点,优化器选择了在students表进行全表扫描。
为了验证我们上述的猜想,我们执行下面这条sql语句来看一下执行计划:
select students.id from students join classes on students.class_id=classes.id;

我们发现这条sql语句的执行计划用到了students表的class_id这个普通索引。为什么呢?
因为我们查找的students.id是主键值,可以用到覆盖索引来直接返回该值,所以优化器认为选择索引是最优的执行计划。那也验证了我们前面sql的猜想。
结论
我们在平常写sql的时候,最好用explain来看一下执行计划,判断是否是最优的sql语句。