引言
最近正在疯狂补技术债,以及疯狂赶项目…大一大二摸的鱼终归是要还的,也奉劝大家少摸鱼,不然临近找工作可能就会像我一样焦虑。
在写C++项目中,碰到一个非常古怪的问题,当我像往常一样引入一个头文件时,vscode居然给我报红了(我在vscode中使用的是clangd插件):
 当时就觉得非常震惊,我从未没碰到过只是include一个头文件,居然会报错的情况,当我以为是插件的问题,像往常一样
当时就觉得非常震惊,我从未没碰到过只是include一个头文件,居然会报错的情况,当我以为是插件的问题,像往常一样mkdir build && cd build && cmake .. && make时,gcc也给出了一大堆诸如‘xxx’ does not name a type; did you mean ‘xxx’?、‘xxx’ was not declared in this scope、class ‘xxx::xxx’ does not have any field named ‘xxx’这种显然是未定义才会有这种“简单”的报错。百度和Google给出的信息也很少。
经过思考和搜索,我发现这就是头文件递归包含的问题,在这个项目的一小个模块中,头文件的引用顺序如下:
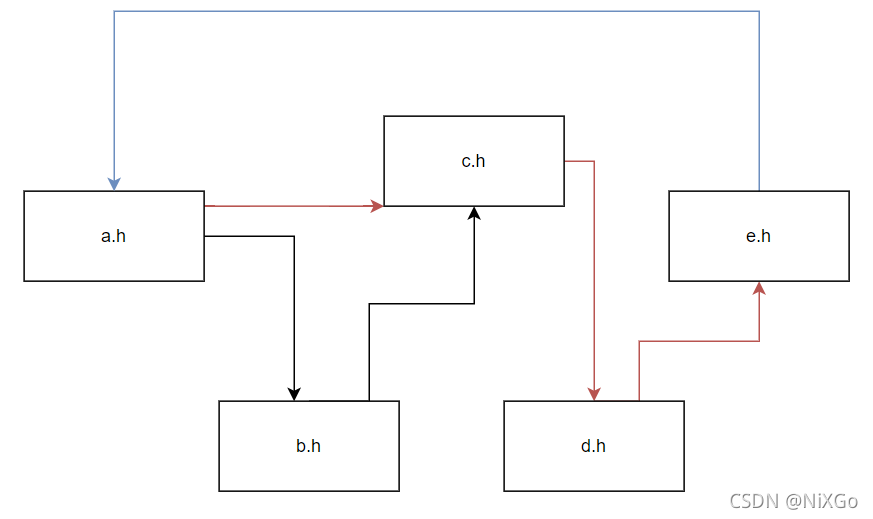 可以看到,蓝色和红色的包含顺序成为了一个闭环,造成了头文件的递归包含,如果是两个头文件成环,那么也叫做头文件互相包含问题。
可以看到,蓝色和红色的包含顺序成为了一个闭环,造成了头文件的递归包含,如果是两个头文件成环,那么也叫做头文件互相包含问题。
下面请大家跟着我来探讨这个问题的成因,以及解决方案。
初始版本
最基本的,我们肯定知道,C/C++语言是头文件和源文件分离的,这样能够有效的防止重复定义,也简化了编译依赖,并且我们也可以把我们的代码编译为动态库或者静态库供他人使用,一定程度上也是一种安全性的提升,著名的pimpl就是基于此实现的。
我们假设有一个工具类A,带有对应的.h和.cc文件,还有一个main.cc调用它,那么大概长下面这个样子:
- a.h
class A {
public:
void SomeMemberFunc();
};
- a.cc
#include "a.h"
void A::SomeMemberFunc() {
// Very long and not suitable for inline functions
}
- main.cc
#include "a.h"
int main(int argc, char *argv[]) {
A().SomeMemberFunc();
return 0;
}
编译成功:
➜ v1 git:(master) ✗ g++ main.cc a.cc
➜ v1 git:(master) ✗ ./a.out
头文件守卫
C/C+允许嵌套包含,但不允许递归包含。嵌套包含就是:a.h包含b.h,b.h包含c.h,等等。
方便起见,我加了一个b.h(其中包含了a.h),在初始版本的情况下,这样则会报错:
➜ v2 git:(master) ✗ g++ main.cc a.cc
In file included from b.h:1,
from main.cc:2:
a.h:1:7: error: redefinition of ‘class A’
1 | class A {
| ^
In file included from main.cc:1:
a.h:1:7: note: previous definition of ‘class A’
1 | class A {
| ^
➜ v2 git:(master) ✗
解决方案是#pragma once或者#ifndef #define #endif,相信大家都用过。区别是前者依赖于编译器,后者可移植性更好,但宏名我们需要自己控制,一般用后者更多。
加上它后,编译错误消失:
➜ v3 git:(master) ✗ g++ main.cc a.cc
➜ v3 git:(master) ✗
递归包含会怎么样
虽然说,项目如果出现了递归包含,可能代表代码逻辑错误,但是有的场景确实需要,也难以避免,我们来模拟一下这种场景。
我们有两个类的头文件,a.h代表class A,b.h代表class B,class A和class B中各有一个对方的实例,main.cc只是简单包含它们,并创建各自class的对象。
如下:
- a.h
#ifndef A_H_
#define A_H_
#include "b.h"
class A {
B b;
};
#endif // !A_H_
- b.h
#ifndef B_H_
#define B_H_
#include "a.h"
class B {
A a;
};
#endif // !B_H_
- main.cc
#include "a.h"
#include "b.h"
int main(int argc, char *argv[]) {
A();
B();
return 0;
}
注意上面两个头文件的头文件守卫都好着,但是编译却出错了:
➜ v4 git:(master) ✗ g++ main.cc
In file included from a.h:4,
from main.cc:1:
b.h:7:3: error: ‘A’ does not name a type
7 | A a;
| ^
为什么会出错
先说结论,正是因为头文件守卫的存在,导致class B在声明时,编译器并不知道class A是啥。
直接看预处理后的结果,具体怎么来的交给大家去想:
➜ v4 git:(master) g++ -E main.cc
# 1 "main.cc"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 1 "<command-line>" 2
# 1 "main.cc"
# 1 "a.h" 1
# 1 "b.h" 1
# 1 "a.h" 1
# 5 "b.h" 2
class B {
A a;
};
# 5 "a.h" 2
class A {
B b;
};
# 2 "main.cc" 2
int main(int argc, char *argv[]) {
A();
B();
return 0;
}
难怪我的项目一编译也是各种类型不存在的错误,这样一来问题就明了了。
前置声明是什么
引用Google C++风格指南中的一些话:
- 定义:所谓「前置声明」(forward declaration)是类、函数和模板的纯粹声明,没伴随着其定义.
- 优点:
- 前置声明能够节省编译时间,多余的 #include 会迫使编译器展开更多的文件,处理更多的输入。
- 前置声明能够节省不必要的重新编译的时间。 #include 使代码因为头文件中无关的改动而被重新编译多次。
- 缺点:
- 前置声明隐藏了依赖关系,头文件改动时,用户的代码会跳过必要的重新编译过程。
- 前置声明可能会被库的后续更改所破坏。前置声明函数或模板有时会妨碍头文件开发者变动其 API. 例如扩大形参类型,加个自带默认参数的模板形参等等。
- 前置声明来自命名空间 std:: 的 symbol 时,其行为未定义。
- 很难判断什么时候该用前置声明,什么时候该用 #include 。极端情况下,用前置声明代替 #include 甚至都会暗暗地改变代码的含义:
// b.h:
struct B {
};
struct D : B {
};
// good_user.cc:
#include "b.h"
void f(B*);
void f(void*);
void test(D* x) {
f(x); } // calls f(B*)
- 如果 #include 被 B 和 D 的前置声明替代, test() 就会调用 f(void*) .
- 前置声明了不少来自头文件的 symbol 时,就会比单单一行的 include 冗长。
- 仅仅为了能前置声明而重构代码(比如用指针成员代替对象成员)会使代码变得更慢更复杂.
- 结论:
- 尽量避免前置声明那些定义在其他项目中的实体.
- 函数:总是使用 #include.
- 类模板:优先使用 #include.
如何解决递归包含问题
经过上一小节的了解,我们了解到,前置声明是解决问题的答案。尽管人家Google建议我们不要使用,但毕竟这也是没有办法的办法,人也说了,类模板优先使用#include,但没说不能使用。
在我看来,最直接的缺点是,使用了前置声明,我们就只能在头文件中声明对象的指针或引用,这是不完全类型,所以我们也无法使用其成员,毕竟编译器实例化某个类型时,需要知道对象的确切大小,这对一些特殊的关系,比如Composition组合关系来讲是不好处理的。
我们在a.h中前置声明了class B,并将class A中的成员变量b改成一个指针,最后删掉#include "b.h"来打破这个递归包含关系,代码如下:
编译也顺利通过:
➜ v5 git:(master) ✗ g++ main.cc
利用前置声明,我找到了项目中某个Aggregation聚合关系的类(不需要我在头文件声明类的实体),相当于打断了这个包含关系环,如下:
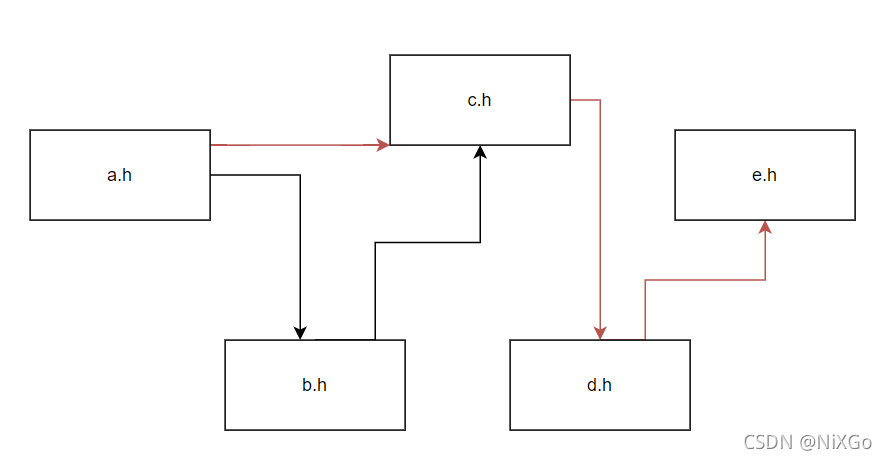 这个问题到此就解决了,虽说解决方案有一定侵入性,但我觉得问题出现的本质应该是由语言特性和代码架构决定的,前置声明算是一种小小的解决办法吧。
这个问题到此就解决了,虽说解决方案有一定侵入性,但我觉得问题出现的本质应该是由语言特性和代码架构决定的,前置声明算是一种小小的解决办法吧。
参考
Google C++风格指南
c++ header files including each other mutually - Stack Overflow
博客中用到的代码我放在了我个人的GitHub中,读者们可以动手尝试一下。