文章目录
12 | 有一亿个 keys 要统计,应该用哪种集合?
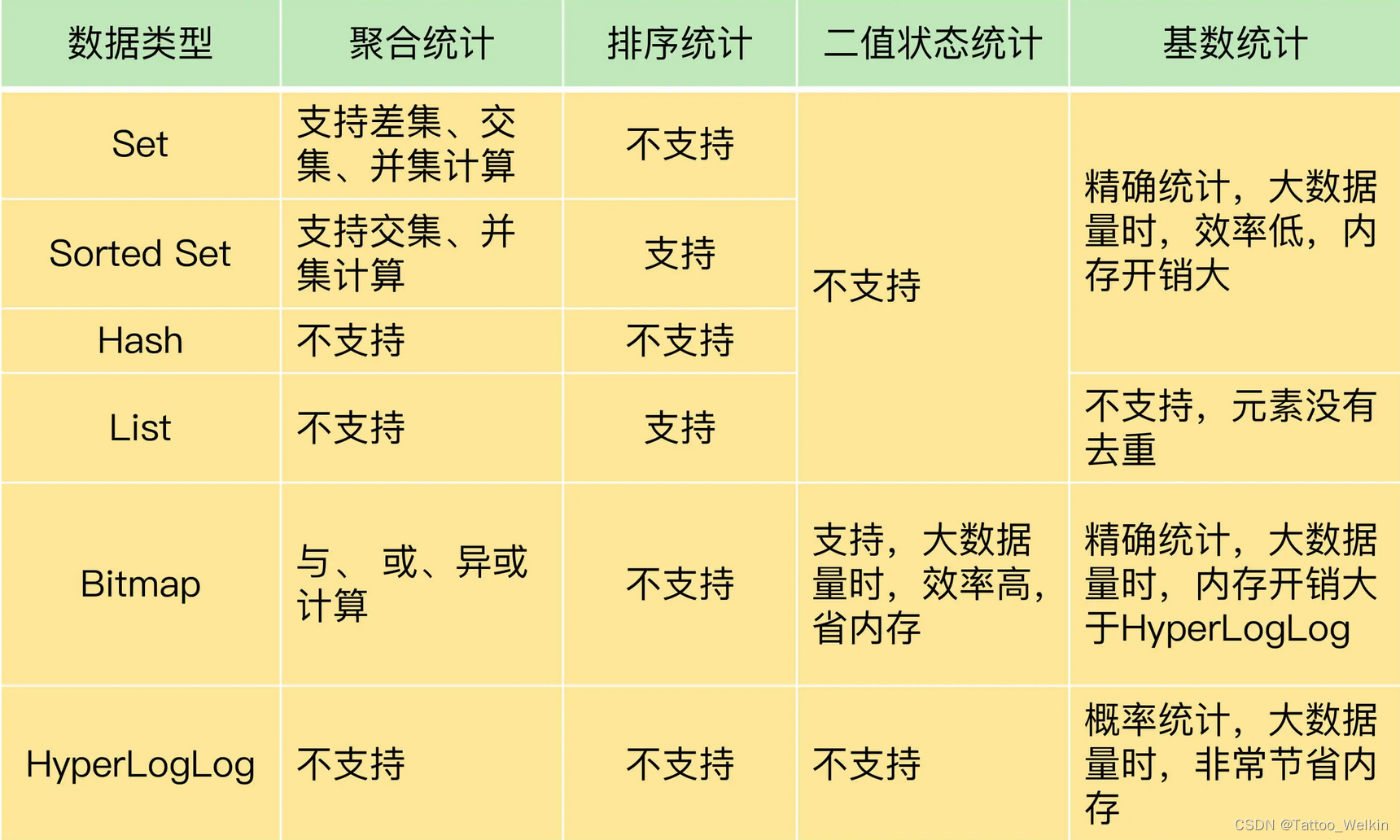
聚合统计
- 当你需要对多个集合进行聚合计算时,Set 类型会是一个非常不错的选择。不过,我要提醒你一下,这里有一个潜在的风险。
- Set 的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致 Redis 实例阻塞。所以,我给你分享一个小建议:你可以从主从集群中选择一个从库,让它专门负责聚合计算,或者是把数据读取到客户端,在客户端来完成聚合统计,这样就可以规避阻塞主库实例和其他从库实例的风险了。
排序统计
场景:
- 抖音的评论需要按照时间戳来排序展示。
- List 集合:按照元素进入 List 的顺序进行排序的。(不好,因为本身进入的顺序可能就会产生颠倒黑白)
- Sorted Set:根据元素的权重来排序
在面对需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,建议你优先考虑使用 Sorted Set。
二值状态统计
指集合元素的取值就只有 0 和 1 两种。在签到打卡的场景中,我们只用记录签到(1)或未签到(0),所以它就是非常典型的二值状态。
bitmap :位图
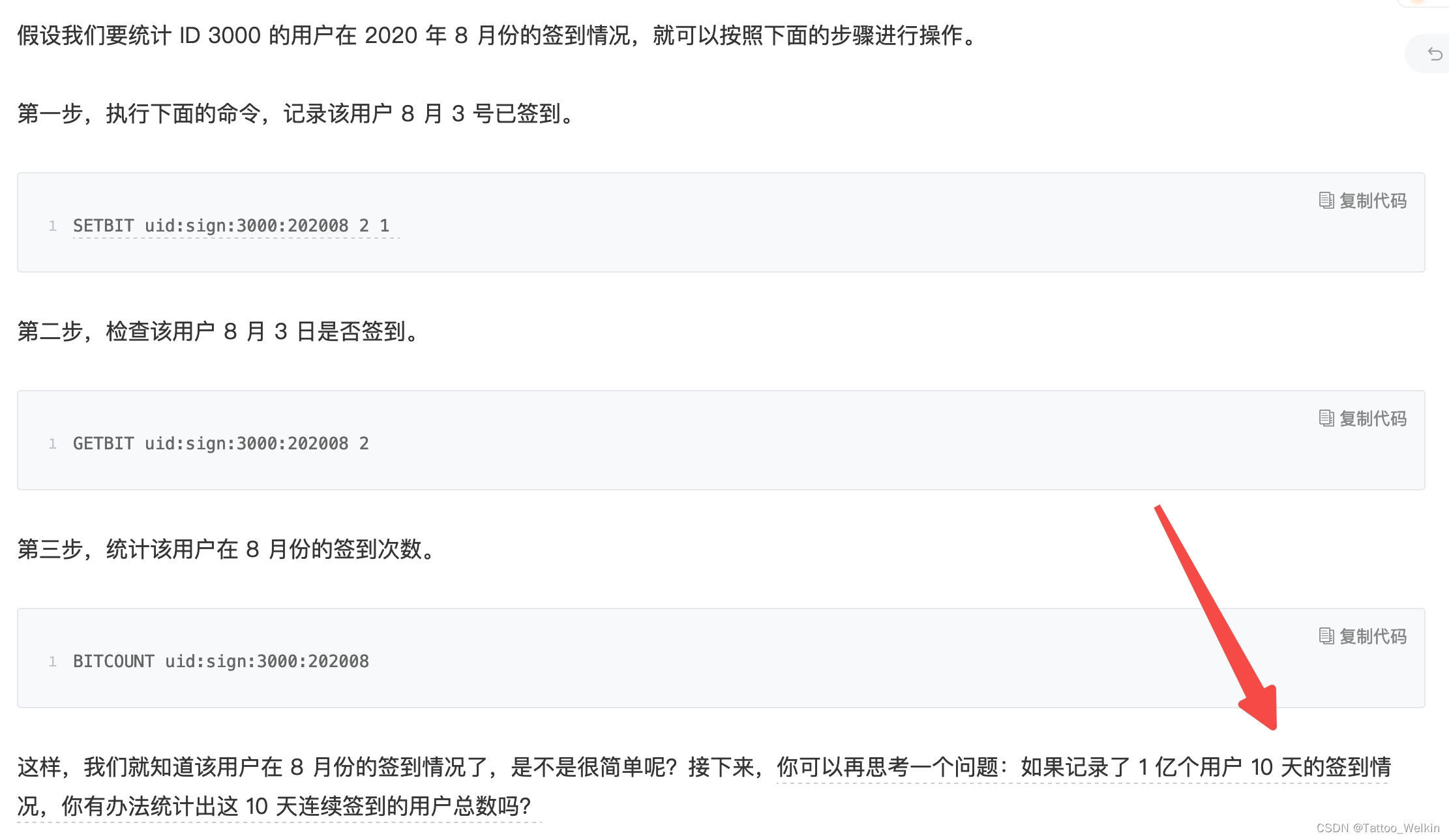
箭头所指的问题很有意思:我们以每天的日期为 key ,将一亿个用户按照一定的顺序使用 bitmap 记录签到情况,那么就会有 10 个 bitmap ,然后我们将这十个bitmap 做 与 运算即可得到相应的用户。
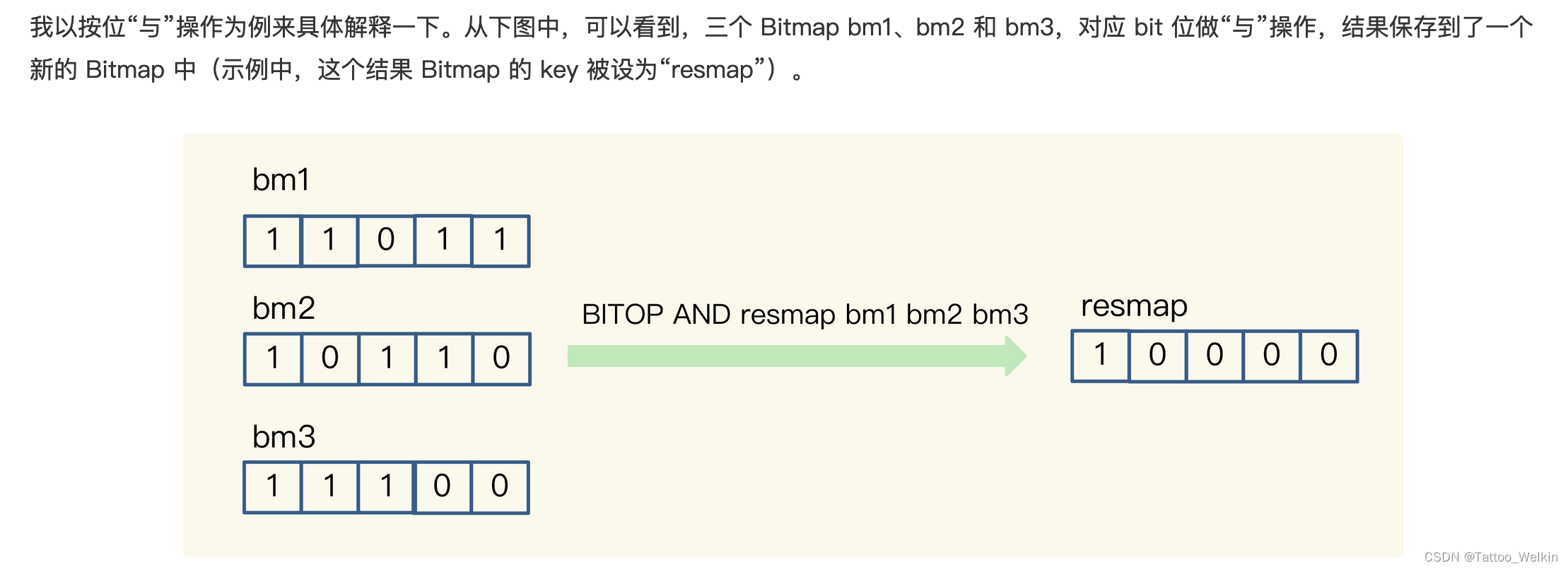
具体原理如图:(其实就是利用了 与运算 的特征)
基数统计
基数统计是指统计一个集合中不重复的元素个数。比如:统计网页的 UV。
网页 UV 的统计有个独特的地方,就是需要去重,一个用户一天内的多次访问只能算作一次。在 Redis 的集合类型中,Set 类型默认支持去重,所以看到有去重需求时,我们可能第一时间就会想到用 Set 类型。
HyperLogLog 是一种用于统计基数的数据集合类型,它的最大优势就在于,当集合元素数量非常多时,它计算基数所需的空间总是固定的,而且还很小。
在 Redis 中,每个 HyperLogLog 只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数。你看,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。
HyperLogLog 的统计规则是基于概率完成的(伯努力实验),所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。这也就意味着,你使用 HyperLogLog 统计的 UV 是 100 万,但实际的 UV 可能是 101 万。虽然误差率不算大,但是,如果你需要精确统计结果的话,最好还是继续用 Set 或 Hash 类型。
HyperLogLog 的内部实现(TODO)
13 | GEO是什么?还可以定义新的数据类型吗?
- 5 大基本数据类型:String、List、Hash、Set 和 Sorted Set。
- 三种拓展类型:bitmap、HyperLogLog、GEO
面向 LBS 应用的 GEO 数据类型
GeoHash 的编码方法
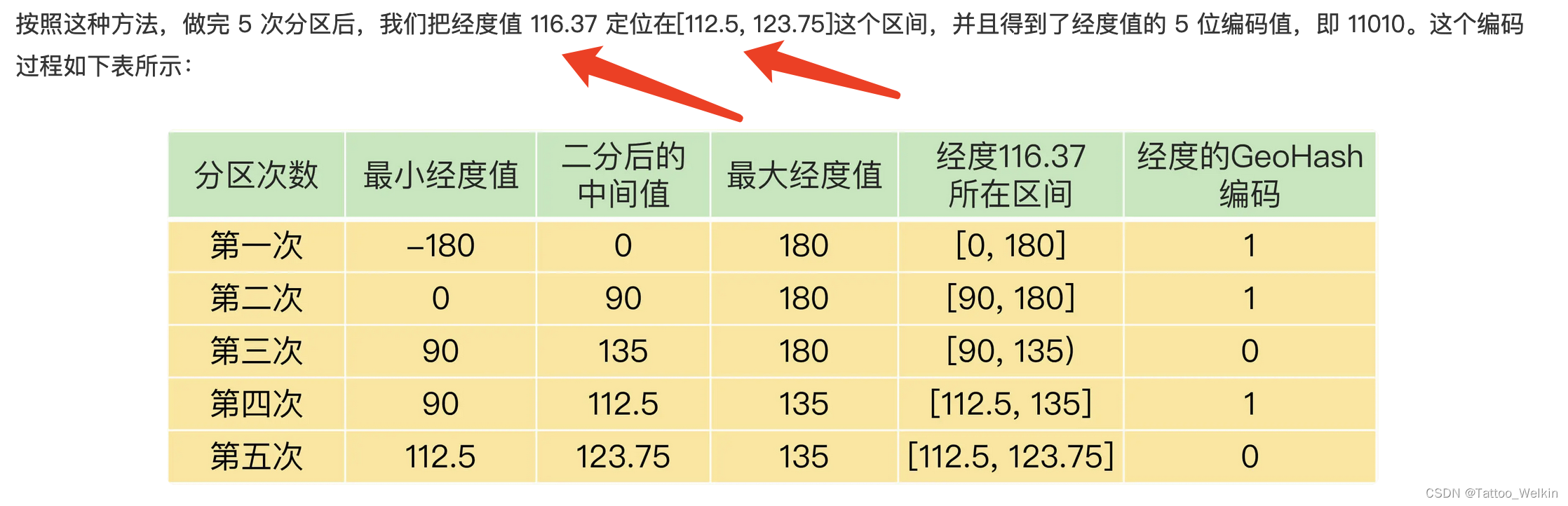
GeoHash 编码类似二分查找,但是我们不一定要找到具体的元素,找出元素所在的区间即可。假如我们的地理范围从-180到180。目标值是120,第一次二分是-180~0和0~180。那么目标值就在右边,这时可以用一个bit表示,比如1。后面依次类推,二分的次数可以自己定,最终会根据二分的结果形成一个二进制串,比如11001。
当然,使用 GeoHash 编码后,我们相当于把整个地理空间划分成了一个个方格,每个方格对应了 GeoHash 中的一个分区。
举个例子。我们把经度区间 [-180,180] 做一次二分区,把纬度区间[-90,90]做一次二分区,就会得到 4 个分区。我们来看下它们的经度和纬度范围以及对应的 GeoHash 组合编码。
- 分区一:[-180,0) 和[-90,0),编码 00;
- 分区二:[-180,0) 和[0,90],编码 01;
- 分区三:[0,180]和[-90,0),编码 10;
- 分区四:[0,180]和[0,90],编码 11。

所以,我们使用 Sorted Set 范围查询得到的相近编码值,在实际的地理空间上,也是相邻的方格,这就可以实现 LBS 应用“搜索附近的人或物”的功能了。
如何自定义数据类型?

具体实施步骤如下:

14 | 如何在Redis中保存时间序列数据?
- 写的特征是:(1)高并发 (2)不会更新
- 读的特征是:(1)单条记录的查询 (2)范围查询 (3)对某个时间范围内的数据做聚合计算
针对时间序列数据的“写要快”,Redis 的高性能写特性直接就可以满足了;而针对“查询模式多”,也就是要支持单点查询、范围查询和聚合计算,Redis 提供了保存时间序列数据的两种方案,分别可以基于 Hash 和 Sorted Set 实现,以及基于 RedisTimeSeries 模块实现。
基于 Hash 和 Sorted Set 保存时间序列数据

Hash 的数据结构不具备排序,所以实现范围查询,就比较困难。
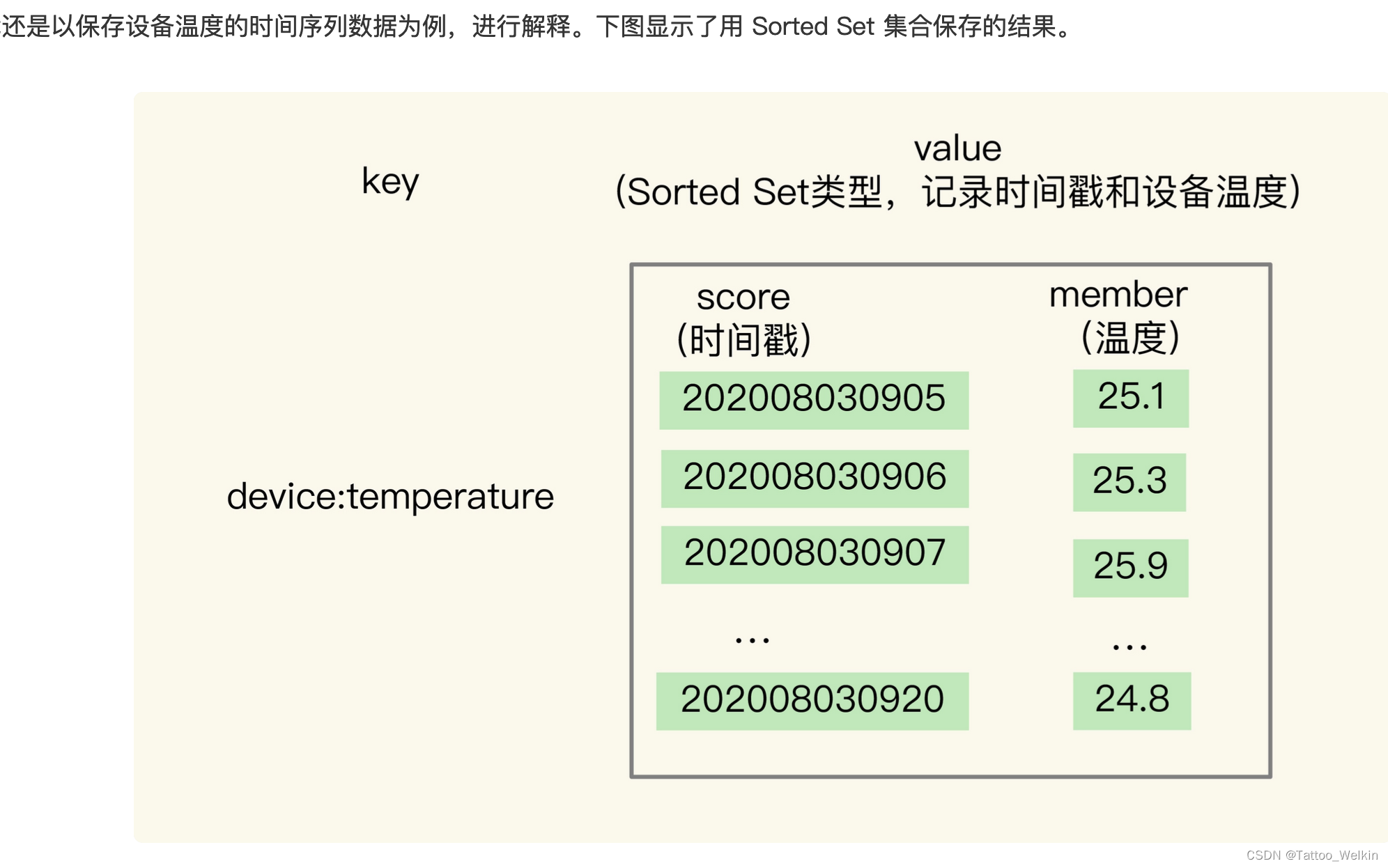
当然,如果使用 Sorted Set 就会如上所示,把时间戳作为 Sorted Set 集合的元素分数,把时间点上记录的数据作为元素本身。很好进行范围查询,因为可以根据 时间戳 权重来 排序嘛。但是 Sorted Set 是没有根据 Key 快速索取 Value 的特性的。所以我们将其组合起来使用。但是我们又会面临一个新的问题,也就是我们要解答的第二个问题:如何保证写入 Hash 和 Sorted Set 是一个原子性的操作呢?
使用 MUTLI 和 EXEC 命令保证了 Redis 能原子性地把数据保存到 Hash 和 Sorted Set 中。
接下来,我们需要继续解决第三个问题:如何对时间序列数据进行聚合计算?
自己来实现的话,自然就是:先根据 Sorted Set 取到数据,然后自己聚合进行计算。
像这种情况就只能使用:RedisTimeSeries
基于 RedisTimeSeries 模块保存时间序列数据
如果我们只需要进行单个时间点查询或是对某个时间范围查询的话,适合使用 Hash 和 Sorted Set 的组合,它们都是 Redis 的内在数据结构,性能好,稳定性高。但是,如果我们需要进行大量的聚合计算(每 3 分钟统计一下各个设备的温度状态,一旦设备温度超出了设定的阈值,就要进行报警。这是一个典型的聚合计算场景),同时网络带宽条件不是太好时,Hash 和 Sorted Set 的组合就不太适合了。此时,使用 RedisTimeSeries 就更加合适一些。
RedisTimeSeries 是 Redis 的一个扩展模块。它专门面向时间序列数据提供了数据类型和访问接口,并且支持在 Redis 实例上直接对数据进行按时间范围的聚合计算。
假设我们需要每 3 分钟计算一次的所有设备各指标的最大值,每个设备每 15 秒记录一个指标值,1 分钟就会记录 4 个值,3 分钟就会有 12 个值。我们要统计的设备指标数量有 33 个,所以,单个设备每 3 分钟记录的指标数据有将近 400 个(33 * 12 = 396),而设备总数量有 1 万台,这样一来,每 3 分钟就有将近 400 万条(396 * 1 万 = 396 万)数据需要在客户端和 Redis 实例间进行传输。
而使用了 RedisTimeSeries 数据的传输就会是:
以每 3 分钟算一次最大值为例。在 Redis 实例上直接聚合计算,那么,对于单个设备的一个指标值来说,每 3 分钟记录的 12 条数据可以聚合计算成一个值,单个设备每 3 分钟也就只有 33 个聚合值需要传输,1 万台设备也只有 33 万条数据。数据量大约是在客户端做聚合计算的十分之一,很显然,可以减少大量数据传输对 Redis 实例网络的性能影响。
缺点
RedisTimeSeries 的底层数据结构使用了链表,它的范围查询的复杂度是 O(N) 级别的,同时,它的 TS.GET 查询只能返回最新的数据,没有办法像第一种方案的 Hash 类型一样,可以返回任一时间点的数据。
15 | 消息队列的考验:Redis 有哪些解决方案?
具体有两种实现方式:
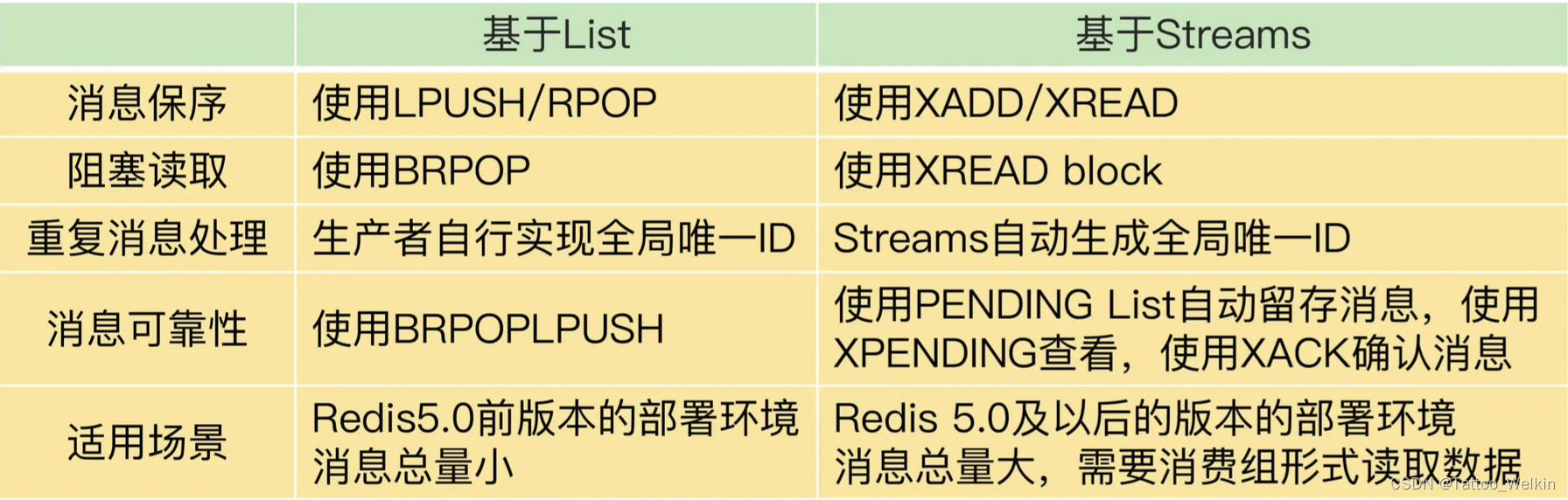
关于 Redis 是否适合做消息队列,业界一直是有争论的。很多人认为,要使用消息队列,就应该采用 Kafka、RabbitMQ 这些专门面向消息队列场景的软件,而 Redis 更加适合做缓存。
Redis 是一个非常轻量级的键值数据库,部署一个 Redis 实例就是启动一个进程,部署 Redis 集群,也就是部署多个 Redis 实例。而 Kafka、RabbitMQ 部署时,涉及额外的组件,例如 Kafka 的运行就需要再部署 ZooKeeper。相比 Redis 来说,Kafka 和 RabbitMQ 一般被认为是重量级的消息队列。
所以,关于是否用 Redis 做消息队列的问题,不能一概而论,我们需要考虑业务层面的数据体量,以及 对性能、可靠性、可扩展性 的需求。如果分布式系统中的组件消息通信量不大且对于丢数据并不敏感,那么,Redis 只需要使用有限的内存空间就能满足消息存储的需求,而且,Redis 的高性能特性能支持快速的消息读写,不失为消息队列的一个好的解决方案。
影响 Redis 性能的操作有哪些?
- Redis 内部的阻塞式操作;
- CPU 核和 NUMA 架构的影响;
- Redis 关键系统配置;
- Redis 内存碎片;
- Redis 缓冲区。
16 | 异步机制:如何避免单线程模型的阻塞?(即 影响 Redis 性能的操作之 Redis 内部的阻塞式操作,共有 5 种)
1. 和客户端交互时的阻塞点
键值对的增删改查操作是 Redis 和客户端交互的主要部分,也是 Redis 主线程执行的主要任务。所以,复杂度高的增删改查操作肯定会阻塞 Redis。比如:
(1)集合全量查询和聚合操作以及
(2)bigKey 删除/删除大量数据的操作
(3)清空数据库时
删除操作是因为:OS 需要对空闲的 page 进行管理
2. 和磁盘交互时的阻塞点
(1)AOF 日志同步写
3. 主从节点交互时的阻塞点
(1)RDB 文件的加载
4. 切片集群实例交互时的阻塞点
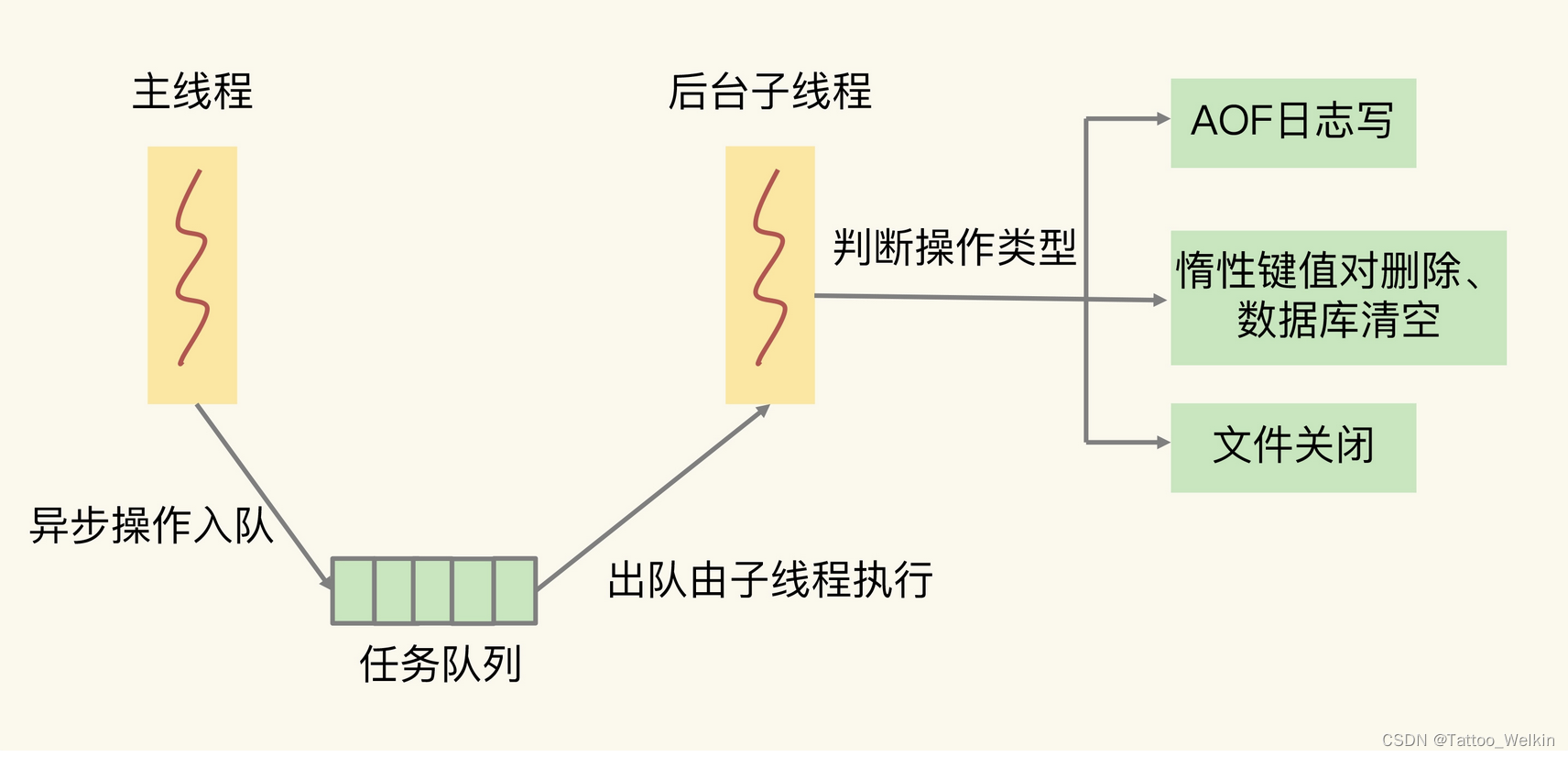
在上述 5 大阻塞点中,bigkey 删除、清空数据库、AOF 日志同步写不属于关键路径操作,可以使用 异步子线程机制来完成。Redis 在运行时会创建三个子线程,主线程会通过一个任务队列和三个子线程进行交互。子线程会根据任务的具体类型,来执行相应的异步操作。如下图所示:
17 | 为什么CPU结构也会影响Redis的性能?(即 影响 Redis 性能的操作之 CPU 核和 NUMA 架构的影响)
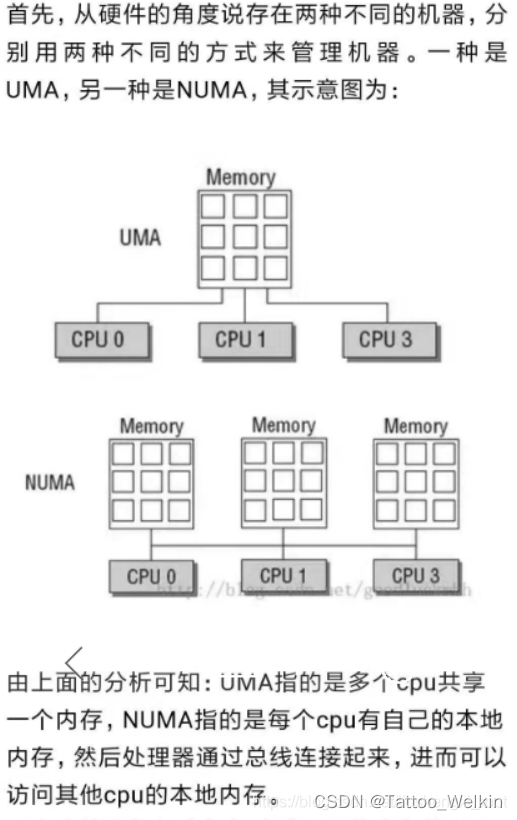
在多 CPU 架构上,应用程序可以在不同的处理器上运行。Redis 可以先在 CPU 1 上运行一段时间,然后再被调度到 CPU 2 上运行。
但是,有个地方需要你注意一下:如果应用程序先在一个 CPU 上运行,并且把数据保存到了内存,然后被调度到另一个 CPU 上运行,此时,应用程序再进行本地内存访问时,就需要访问之前 CPU 上连接的本地内存,这种访问属于远端内存访问。和访问 CPU 直接连接的本地内存相比,远端内存访问会增加应用程序的延迟。
CPU 多核对 Redis 性能的影响
如果在 CPU 多核场景下,Redis 实例被频繁调度到不同 CPU 核上运行的话,那么,对 Redis 实例的请求处理时间影响就更大了。每调度一次,一些请求就会受到运行时信息、指令和数据重新加载过程的影响,这就会导致某些请求的延迟明显高于其他请求。
在一个 CPU 核上运行时,应用程序需要记录自身使用的软硬件资源信息(例如栈指针、CPU 核的寄存器值等),我们把这些信息称为运行时信息。同时,应用程序访问最频繁的指令和数据还会被缓存到 L1、L2 缓存上,以便提升执行速度。
因此就需要将:Redis 实例和 CPU 核绑定,使用 taskset 命令
绑核的风险和解决方案
当我们把 Redis 实例绑到一个 CPU 核上时,就会导致子进程、后台线程和 Redis 主线程竞争 CPU 资源,一旦子进程或后台线程占用 CPU 时,主线程就会被阻塞,导致 Redis 请求延迟增加。
针对这种情况,有两种解决方案,分别是一个 Redis 实例对应绑一个物理核和优化 Redis 源码。
一个 Redis 实例对应绑一个物理核(略)
优化 Redis 源码
把子进程和后台线程绑到不同的 CPU 核上。
18 | 波动的响应延迟:如何应对变慢的Redis?(上)
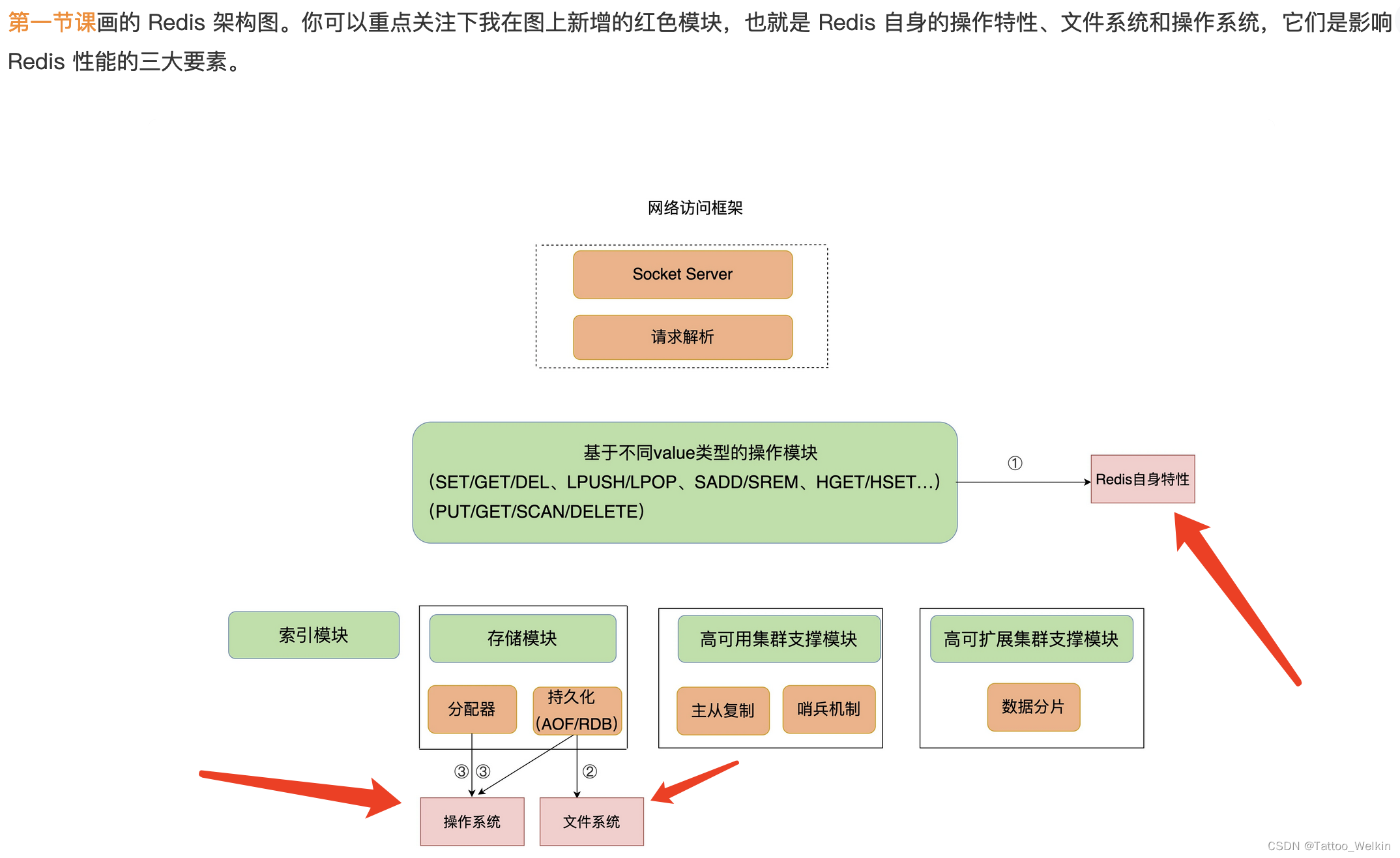
Redis 自身操作特性的影响
1. 慢查询命令
解决:
- Redis 日志
- latency monitor 工具
如果的确有大量的慢查询命令,有两种处理方式:
- 用其他高效命令代替。比如说,如果你需要返回一个 SET 中的所有成员时,不要使用 SMEMBERS 命令,而是要使用 SSCAN 多次迭代返回,避免一次返回大量数据,造成线程阻塞。
- 当你需要执行排序、交集、并集操作时,可以在客户端完成,而不要用 SORT、SUNION、SINTER 这些命令,以免拖慢 Redis 实例。
- KEYS 命令需要遍历存储的键值对,所以操作延时高。如果你不了解它的实现而使用了它,就会导致 Redis 性能变慢。所以,KEYS 命令一般不被建议用于生产环境中。
2. 过期 key 操作
设置 key 过期时间时,是否使用了相同的 UNIX 时间戳,有没有使用 EXPIRE 命令给批量的 key 设置相同的过期秒数。因为,这都会造成大量 key 在同一时间过期,导致性能变慢。
文件系统的影响

AOF 回写的策略影响。
操作系统的影响(操作系统的内存 swap && 内存大页)
Linux 内核从 2.6.38 开始支持内存大页机制,该机制支持 2MB 大小的内存页分配,而常规的内存页分配是按 4KB 的粒度来执行的。
系统的设计通常是一个取舍过程,我们称之为 trade-off
虽然内存大页可以给 Redis 带来内存分配方面的收益,但是,不要忘了,Redis 为了提供数据可靠性保证,需要将数据做持久化保存。这个写入过程由额外的线程执行,所以,此时,Redis 主线程仍然可以接收客户端写请求。客户端的写请求可能会修改正在进行持久化的数据。在这一过程中,Redis 就会采用写时复制机制,也就是说,一旦有数据要被修改,Redis 并不会直接修改内存中的数据,而是将这些数据拷贝一份,然后再进行修改。
如果采用了内存大页,那么,即使客户端请求只修改 100B 的数据,Redis 也需要拷贝 2MB 的大页。相反,如果是常规内存页机制,只用拷贝 4KB。两者相比,你可以看到,当客户端请求修改或新写入数据较多时,内存大页机制将导致大量的拷贝,这就会影响 Redis 正常的访存操作,最终导致性能变慢。
cat /sys/kernel/mm/transparent_hugepage/enabled
如果执行结果是 always,就表明内存大页机制被启动了;如果是 never, 就表示,内存大页机制被禁止。