 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
引言
这篇文章的内容是XiyouLinuxGroup一次知识分享的题目,鉴于有一些同学没有参与,我就划水把本来要讲的文档加了一点文字,凑成了一篇博客。因为不是把内容的排列当博客来组织的,所以可能会有一些地方内容比较简略,而且也没有附上相关知识的链接,所以知识点可能比较零碎,希望学弟学妹和其他有兴趣的朋友可以指出不足并提出意见。
介绍
动态追踪技术是一种高级的软件调试技术。它可以帮助你快速定位和解决生产系统中问题。互联网快速发展,软件系统规模越来越大,系统的业务逻辑越来越复杂。慢慢的,我们的程序员丧失了对软件系统的洞察力和掌控力,复杂且庞大的软件使得出现错误的概率大大提升了,这也使得我们解决问题变的越来越困难,一个顽固的错误可能会浪费我们一下午甚至一天的时间,如果错误影响到了业务,团队付出的成本又会再上一步。
很多人处理问题的方法是错误的,一旦软件系统出现问题,很多人立马去搜索对应的case,一般情况下你踩过的坑应该有人已经踩过了,如果你运气比较好的话,能够很快fix掉问题。但是这些热心网友的解决方案不一定适合你,我们的系统产生问题的原因不尽相同。这也意味着不但问题可能没有解决,可能原本的上下文信息还被破坏了。
工具
总是有人定位问题喜欢用一双天真无邪的大眼睛盯着代码一行一行瞅,搭配以printf大法,不是不行,而是不该一上来就这样。这样看似风风火火忙碌一天,实则基本是一点用处也没有。
推动世界进步的总是真正的懒惰者而不是虚假的勤奋者,一堆大佬为了简化定位问题的难度而开发了一堆好用工具,我们应该学习使用这些提高我们的生产力而不是用无谓的努力去感动自己,这也是我写这篇文章初衷的一部分,至当年宛如🪂一样的我自己。
当然还有一些比较常用的工具,使得我们可以迅速的定位问题出在哪里:
30秒排查问题
先搞清楚,以下是一些让我们粗粒度定位问题的工具。
Top/Uptime
- 按F可以出来一个菜单,上下左右选择,空格确定,然后出去top就可以看到多显示了一项
- 按1可以显示所有CPU的负载情况
参考[4]
dmesg -T | tail -n x
OOM,TCP丢弃请求,段错误
参考[5]
vmstat
vmstat把输出分为六个部分
procs:可以看出目前CPU的负载如何,当然Uptime更直观一点memory:基本的内存信息swap:数字比较大基本就是内存出问题了io:磁盘的输入输出次数,单位是Block,可以通过df + tune2fs -l devname | grep Block查看system:中断数和上下文切换数CPU:中的us和sy快速定位问题是On-CPU还是Off-CPU,
我们可以看到这个命令信息很全,但是粒度很粗,导致这个信息基本用处不是很大,但是可以帮助我们五秒之内迅速定位问题的大体原因,这就是下钻分析法的第一步。
当然vmstat有很多很有意思的参数可以使用:
-w:更加人性化的输出,你的内存比较大会导致memory那一行超限-d:详细的磁盘信息-m:显示内核slab分配器的详细数据-n:各种事件的统计
虽然比什么都不加精细一些,但是本质上还是采样的过程,也就是说是一个时间间隔内的统计,这个时间间隔可以指定,直接在vmstat后面加就可以了,下面命令的含义是共执行两次,每次间隔为两秒:
vmstat 2 2
参考[6]
mpstat
可以查看每个CPU的详细信息,执行如下指令:
mpstat -P ALL 1 3
含义是打印所有CPU的细节信息,除了以上命令外还可以执行下面的命令:
mpstat -I CPU #报告每个处理器上每个中断的总数
mpstat -I SUM #中断统计
参考[7][8][9]
pidstat
我个人比较喜欢的一个工具,因为它可以很漂亮的展示出每个进程每种资源的使用情况,这于上面的工具就不太一样了,因为多划分出一个pid的维度去进行观测。
正常粗粒度的查看如下,默认每秒执行一次输出:
pidstat 1
也可以执行更细粒度的操作:
pidstat -u 1 #查看CPU相关的指标
pidstat -r 1 #查看内存相关的指标
pidstat -d 1 #查看IO相关的指标
pidstat -w 1 #查看上下文相关的指标
加上-p可以指定相关的进程号。
参考[10]
iostat
一般执行的命令如下,可以打印详细的IO数据,包括每秒的读写数,合并的读写数,平均的IO等待时间和服务时间,设备繁忙率等等等:
iostat -xz 1
非常实用的一个命令,但是当发现是磁盘的问题当时候就回到Off-CPU当分析了.
参考[11]
iotop可以快速定位出磁盘IO较高的进程,执行iotop -oP
sar
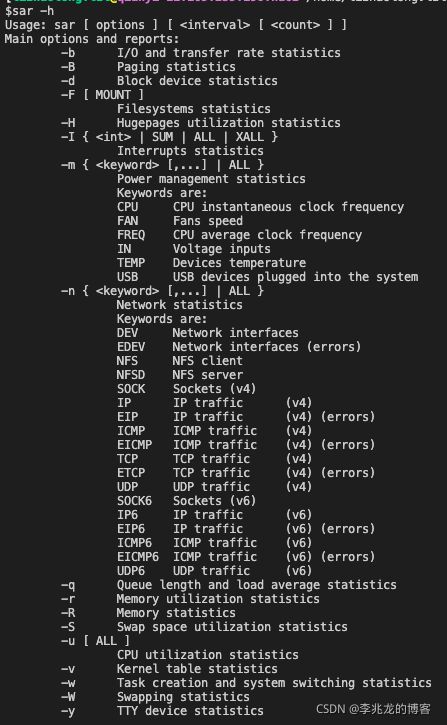
我们可以非常详细的去监测相关的信息,但是这是全机器所有进程的数据,如果想要精细化到每一个进程还是SystemTap或者bpfTrace比较实在。man中记录了每一个数据项的意义。参考[12][13]
出现这个问题时Requested activities not available in file /var/log/sa/sa19 ,参考[14]
原因就是因为sar为了省空间没有保存所有的数据,所以自然拿去分析这部分数据的时候就会保错,所以我们需要配置我们希望检测的数据。
可以进入/etc/sysconfig/sysstat修改其中的SADC_OPTIONS选项,也可以进到/usr/lib64/sa执行sadc命令,参考上面的链接。
细化排错
目前我们熟知高效的处理问题的方案已经非常多了如下:
- gdb
- Electric Fence
- Valgrind
- perf/gperftools
举个使用gperftools的例子:
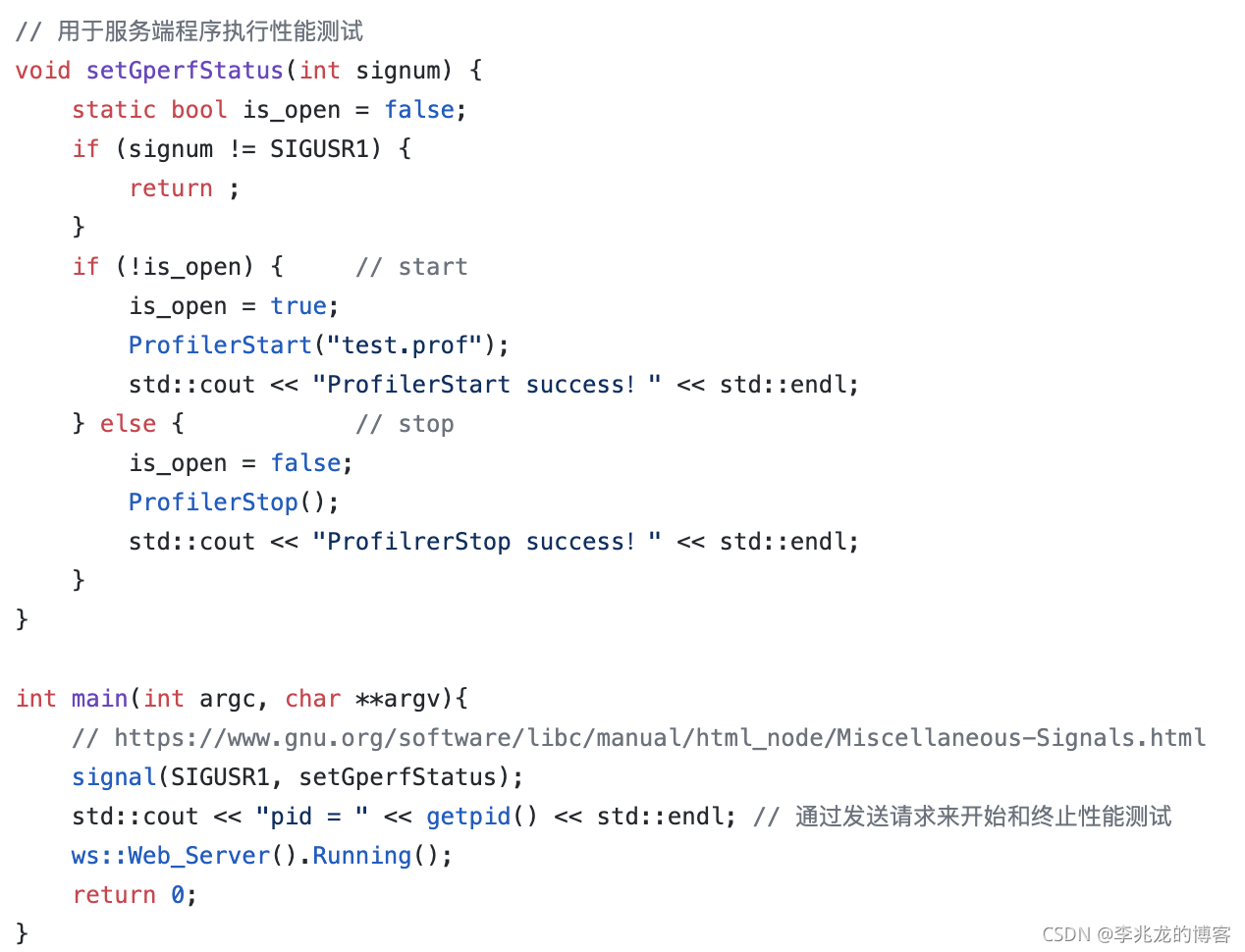
但以上方案都有各自的问题:
- gdb调试多线程时需要指scheduler-locking,这会影响多线程的时序问题
- gperftools测试性能需要改动代码
- Electric Fence和valgrind对于程序性能影响较大,线上环境基本难以使用
而这些大多数时候其实与业务逻辑关系不大,与业务相关时大多数时候解决问题的思路也就是日志和我们内嵌的一些监控工具。
以redis举例:
- info
- memory
- latency
以上工具我们做的都是一个全量统计,最终目的就是为了排错方便。那么是所有我们可能需要的数据都需要去加日志或者在已有的监测框架中加字段吗?
答案是否定的,因为有些数据我们需要全量的记录,因为有效的数据项可能只是一闪即过。但是如果数据本身是可复现的,或者说可复现的数据是有效的,那全量的记录就显得毫无意义了。举个极端的例子:堆栈和出参入参。
动态追踪
这份技术最强大的地方在于它是一个“活体分析技术”。它能完成的功能可以简单的理解为:我们可以完全在线,自由的在我们想要监测的地方插入一段代码,提取我们需要的数据,对性能的影响完全可以接受,且程序不需要重新编译执行重启。这也是很多工程师容易忽略的一点:正在运行的软件系统本身其实就包含了绝大部分的宝贵信息。
目前类似的工具非常多:
- DTrace
- bpfTrace
- ftrace
- bcc
- SystemTap
SystemTap
我们今天主要讨论SystemTap,来看看source.org对于SystemTap的介绍:
SystemTap provides free software (GPL) infrastructure to simplify the gathering of information about the running Linux system. This assists diagnosis of a performance or functional problem. SystemTap eliminates the need for the developer to go through the tedious and disruptive instrument, recompile, install, and reboot sequence that may be otherwise required to collect data.
SystemTap工作步骤:
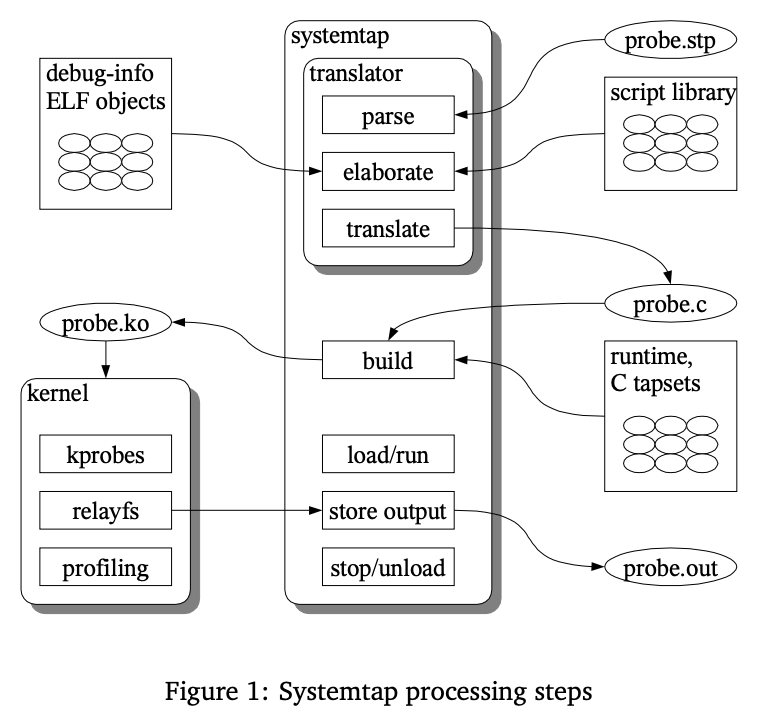
图片引自《Architecture of systemtap: a Linux trace/probe tool》
基于上面的原理图与实际运行的样例,其实可以看出SystemTap工作可以分为五步:
- 解析用户态脚本,建立抽象语法树
- 分析脚本,并解析对于内核/用户态或者任何其他定义的tapsets的符号解析,类似于链接。对内核数据的引用,例如函数参数、局部和全局变量、函数、源位置,都需要解析为实际的运行时地址。通过DWARF调试信息完成此步骤。
- 转化成C语言(可缓存)
- 转化成.ko文件(可缓存)
- 载入内核
下面是一个在线监测内存泄漏的样例:
sudo stap memory_leak.stp -x {
pid} -c a.out
probe begin {
printf("=============begin============\n")
}
//记录内存分配和释放的计数关联数组
global g_mem_ref_tbl
//记录内存分配和释放的调用堆栈关联数组
global g_mem_bt_tbl
probe process("/lib64/libc.so.6").function("__libc_malloc").return, process("/lib64/libc.so.6").function("__libc_calloc").return {
if (target() == pid()) {
if (g_mem_ref_tbl[$return] == 0) {
g_mem_ref_tbl[$return]++
g_mem_bt_tbl[$return] = sprint_ubacktrace()
}
}
}
probe process("/lib64/libc.so.6").function("__libc_free").call {
if (target() == pid()) {
g_mem_ref_tbl[$mem]--
if (g_mem_ref_tbl[$mem] == 0) {
if ($mem != 0) {
//记录上次释放的调用堆栈
g_mem_bt_tbl[$mem] = sprint_ubacktrace()
}
} else if (g_mem_ref_tbl[$mem] < 0 && $mem != 0) {
//如果调用free已经失衡,那就出现了重复释放内存的问题,这里输出当前调用堆栈,以及这个地址上次释放的调用堆栈
printf("============================\n")
printf("g_mem_ref_tbl[%p]\n", $mem)
print_ubacktrace()
printf("last free backtrace:\n%s\n", g_mem_bt_tbl[$mem])
printf("============================\n")
}
}
}
probe end {
//最后输出产生泄漏的内存是在哪里分配的
printf("=============end============\n")
foreach(mem in g_mem_ref_tbl) {
if (g_mem_ref_tbl[mem] > 0) {
printf("%s\n", g_mem_bt_tbl[mem])
}
}
}
kprobes/uprobes原理
- 系统启动时注册中断处理,int3对应的中断处理函数是do_int3
- 注册一个kprobe对象,做一些保存工作。全局使用哈希表存储此结构,索引是监测地址(Radix tree看起来更合适)。
- 保存替换的操作指令
- 覆盖原指令为中断指令
- 当此位置被执行时触发int3中断,基于此地址我们可以找到对应当probe
- 判断是否存在pre_handler的钩子
- 设置单步调试模式(EFLAGS中的TF)
- 执行原指令,执行结束后触发单步调试异常
- 在此逻辑中清除标记位,执行post_handler钩子
- 返回正常逻辑
- 不需要kprobes时原始字节内容被复制回目标地址上
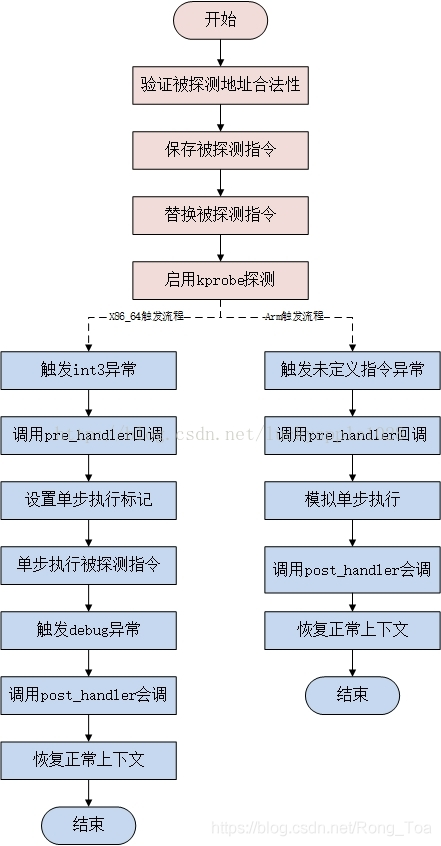
kprobe部分的内核简要源码解析可以参考[1]
kprobes特点与使用限制
- kprobe中可以修改原函数中的数据结构,我们可以基于此来注入错误,kprobe无法区分人为创建的自然发生的错误
不允许探测kprobes.c与do_page_fault以及notifier_call_chain中的数据 - 监测inline函数可能会失败,即无法得到数据
- kprobe handler运行时是关中断的,其中我们不应该调用放弃CPU的函数
- kprobes会避免在处理探测点函数时再次调用另一个探测点的回调函数,当出现这种情况时会添加miss数。
tapsets种类
官网中描述的非常详细[2]
主要分为两个大类:
function::前缀是我们在脚本中可以调用的函数,可以理解为内置函数。probe::前缀是我们可以埋的点,也就是可以在这些地方去进行监测。当然也允许我们自己指定一个可执行文件,静态库,动态库中的符号去监测,甚至可以指定一个文件的行数进行监测。
安全与保护措施
下面内容来源于[3]
The translator asserts certain safety constraints. It ensures that no handler routine can run for too long, allocate memory, perform unsafe operations, or unintentionally interfere with the kernel. Use of script global variables is locked to protect against manipulation by concurrent probe handlers. Use of guru mode constructs such as embedded C (see Section Section 3.5, “Embedded C”) can violate these constraints, leading to a kernel crash or data corruption.
| 选项 | 解释 |
|---|---|
| MAXNESTING | 最大递归层数,默认10 |
| MAXSTRINGLEN | 最长字符串长度,默认128 |
| MAXTRYLOCK | 在声明可能的死锁并跳过probe之前等待全局变量上的锁的最大迭代次数,默认1000 |
| MAXACTION | 任意一个probe中执行的最大语句数,默认1000 |
| MAXMAPENTRIES | 声明数组前未指定长度的话,默认2048 |
| MAXERRORS | 其实是调用error::unknown,exit隐式调用,默认0 |
| MAXSKIPPED | 退出前触发的可重入的probe的最大数目,可以加-t选项查看skipped probes的细节,默认100 |
| MINSTACKSPACE | 探测程序内核堆栈的字节数,默认1024 |
有趣的命令行参数
| 参数 | 作用 |
|---|---|
| -o | 输出文件 |
| -x | pid |
| -c | stap脚本在命令开始时开始,结束时结束 |
| -g | guru模式 |
| -D | 覆盖资源使用的限制 |
| -e | 执行命令行的脚本 |
| -d | 载入module的debuginfo帮助符号解析 |
| -L | 列出所有符合pattern的probe |
| -v | 打印解析载入过程的信息 |
bpfTrace
其原理如下所述:
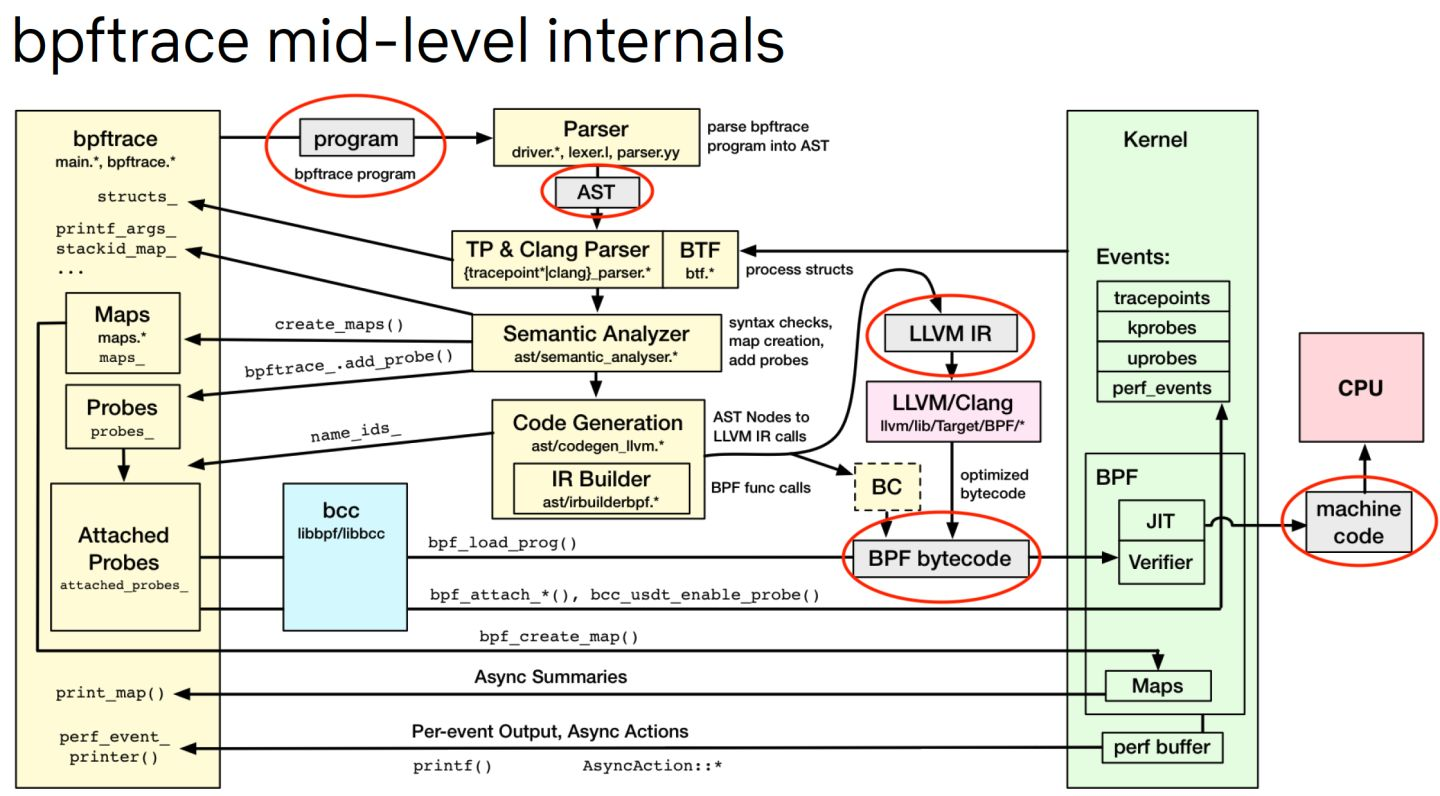

BPF的优势:
- BPF程序会通过验证器的安全性检查,SystemTap因为允许内嵌C语言可能会引起bug
- BPF通过映射区提供丰富的数据结构支持
- 网络领域原子性替代BPF的能力,而内核模块需要卸载和安装
SystemTap优势:
- 可以使用任意的内核函数和内核设施,BPF中只能使用辅助函数
- 理论运行更快,eBPF在内核中需要从一个BPF程序动态编译后执行
共同点:
- 支持USDT(bpfTrace)
总结
时刻清楚使用动态追踪是我们已经定位到了问题具体在哪个位置,如何定位到这个位置也很重要:
除了上面提到的一些工具以外,BCC/bpfTrace已有的脚本我们也可以使用,不必重新造轮子。


参考: