 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
当对于代码质量的追求从学校的看的过去就行到了工作的必须精益求精时,我想我们的程序在每一个时刻到底在干什么就显得尤为重要,说白了,就是可观测性,而且是高效的可观测,毕竟线上出问题需要排查时不可能让你GDB进去看一下,那么程序原生的监控框架,采样和动态追踪看起来就是不可缺少的。
性能分析是个很庞杂的领域,祖师爷当属奈飞的brendangregg大哥,这篇文章的起源也是看到了大哥写的一篇文章。以我的水平自然没办法完全梳理清楚这个东西的脉络,但是如果这篇文章能捋清楚在出现哪种情况时使用Off-time分析,如何分析,我想就已经达到了我想让它作为一篇入门文章的心理预期了。
介绍
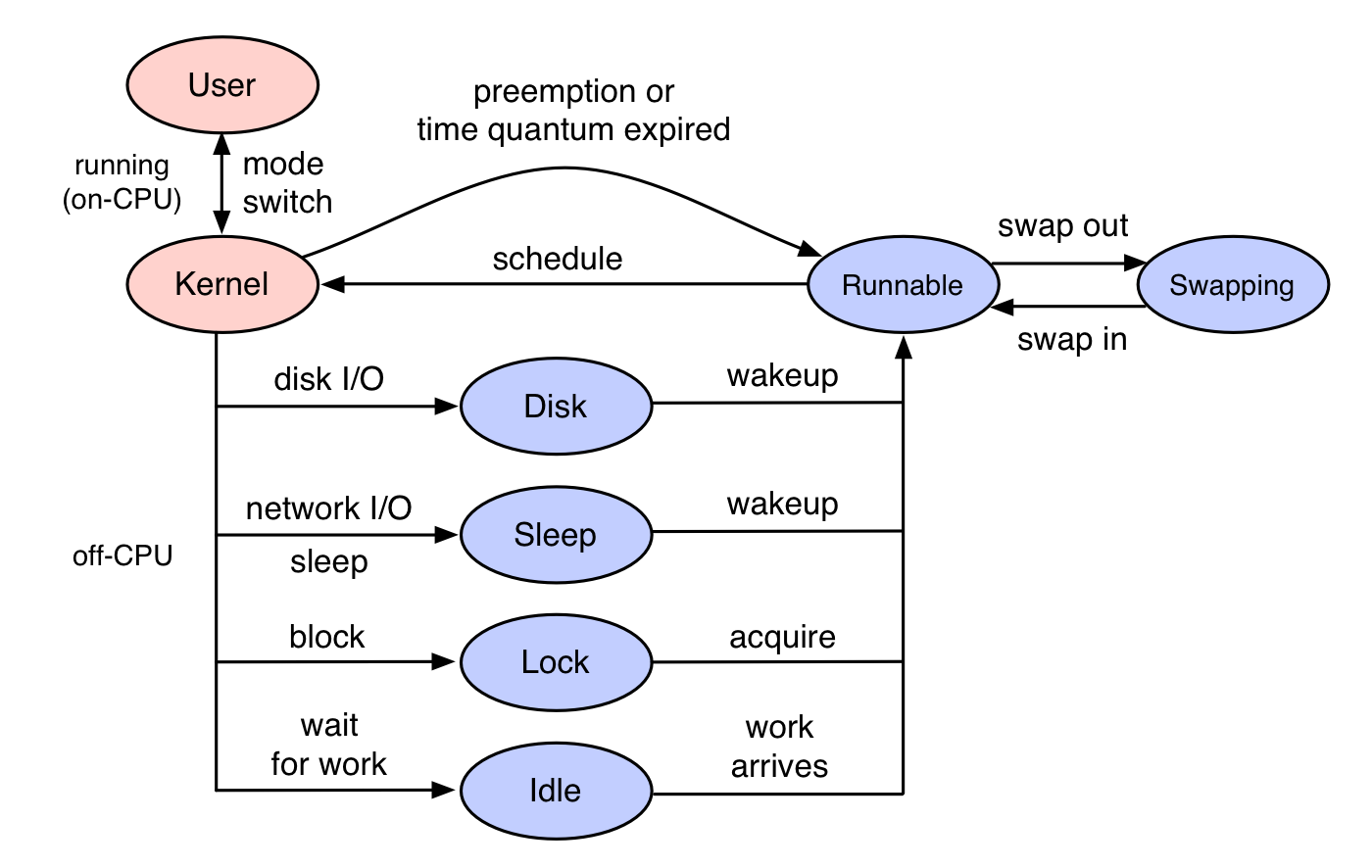
平时我们进行性能分析时使用的大多是On-CPU的分析方法,也就是程序实际在CPU上执行的时间;更年轻一点时也会通过在程序段前后得到时间戳相减获得执行时间,理论来讲后者当然是不准确的,因为程序段可能含有一些系统调用导致上下文切换,或者CPU负载高导致的involuntary context switch,甚至与包括了调度器中的排队时间。话说回来,这些方案都是有局限性的,我们得清楚哪些情况可能导致程序的请求处理能力出现问题,即CPU资源或者IO(网络,磁盘)等资源饱和时(举个例子,还有其他)。On-CPU的分析方式可以帮助我们找到在CPU饱和时出现问题的原因,但是如果是因为IO的话,On-CPU生成的数据意义就不是很大了,最多我们可以用总时间减去实际使用CPU的时间知道是IO出现问题,但是出现了什么问题也没有一点办法,这就是使用Off-CPU分析的原因。
brendangregg大哥对于On-CPU和Off-CPU的解释如下:
On-CPU: where threads are spending time running on-CPU.
Off-CPU: where time is spent waiting while blocked on I/O, locks, timers, paging/swapping, etc.
可能的做法与缺点
事实上在[1]中给出了四种可以做到统计Off-CPU数据的方法,分别是以下四种:
-
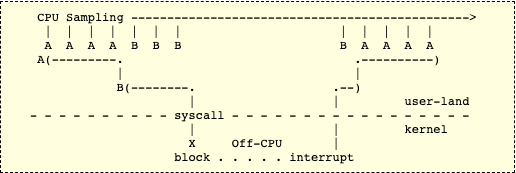
CPU Sampling:相当于每隔一段时钟周期在所有CPU上收集指令地址或者程序堆栈,我们拥有时间和指令,那么当然可以分析出Off-CPU的数据了。
-
Application Tracing:非常裸的一种方案,如果我们想统计整个程序的Off-CPU时间,还想后面找出是哪里出现问题,那就在所有可能出现阻塞的函数上去记录begin和end,然后使用getrusage或者time去获取elapsed time和CPU time就可以知道阻塞了多长时间了。工作量大不说,虽然时间函数不值钱,但也不是这么用的啊。 -
Off-CPU Traving:基于动态追踪的方案,下面详细聊一聊。 -
Off-CPU Sampling:其实还是采样,不过统计结果时只算不在CPU上运行的进程的堆栈。这样我们就可以求出Off-CPU的图谱了,当然有两个周期以内的误差,一般周期选择99HZ(想想为什么,文末解答)。
性能
[1]中对比了Perf和eBPF的性能,
- Using perf to trace every scheduler event caused a 9% drop in throughput while tracing, with occasional 12% drops while the perf.data capture file was flushed to disk. That file ended up 224 Mbytes for 10 seconds of tracing. The file was then post processed by running perf script to do symbol translation, which cost a 13% performance drop (the loss of 1 CPU) for 35 seconds. You could summarize this by saying the 10 second perf trace cost 9-13% overhead for 45 seconds.
- Using eBPF to count stacks in kernel context instead caused a 6% drop in throughput during the 10 second trace, which began with a 13% drop for 1 second as eBPF was initialized, and was followed by 6 seconds of post-processing (symbol resolution of the already-summarized stacks) costing a 13% drop. So a 10 second trace cost 6-13% overhead for 17 seconds. Much better.
可以看到eBPF的性能要高一截,其实也很好理解。perf中在采样进行时每触发一次,对应的perf_event就会向自己的ring_buffer中写入数据,这些数据会全部写入用户态然后执行解析(mmap),而且因为perf是取全部进程的的堆栈进行分析,这显然是一个线性的增长。相比之下eBPF在内核态中就可以完成所有的数据过滤,传递给用户态的全部都是有效的,而且获取的堆栈信息也全部都是有效的。
例子
bcc中已经有了Off-CPU分析的工具,但是为了搞懂原理,我们使用SystemTap脚本来做一个Off-CPU分析。在这之前我们先看看time命令和cpudist工具。
time命令可以帮助察觉到当前的Off-CPU时间总数,让我们察觉到是哪里出现问题(当然不太好用,没办法做到动态),time命令文档中的解释是这样的:
The time command runs the specified program command with the given arguments. When command finishes, time writes a message to standard error giving timing statistics about this program run. These statistics consist of (i) the elapsed real time between invocation and termination, (ii) the user CPU time (the sum of the tms_utime and tms_cutime values in a struct tms as returned by times(2)), and (iii) the system CPU time (the sum of the tms_stime and tms_cstime values in a struct tms as returned by times(2)).
显然根据i != ii + iii,因为存在Off-CPU时间。根据差值我们可以知道程序可能有一个阻塞点。但是只是知道,没办法找到具体是哪里,而且差值可能是多个事件的总和,我们也没办法看到一个阻塞时延分布:
cpudist工具可以帮助我们看到Off-CPU事件时延的分布,允许指定线程和进程号:
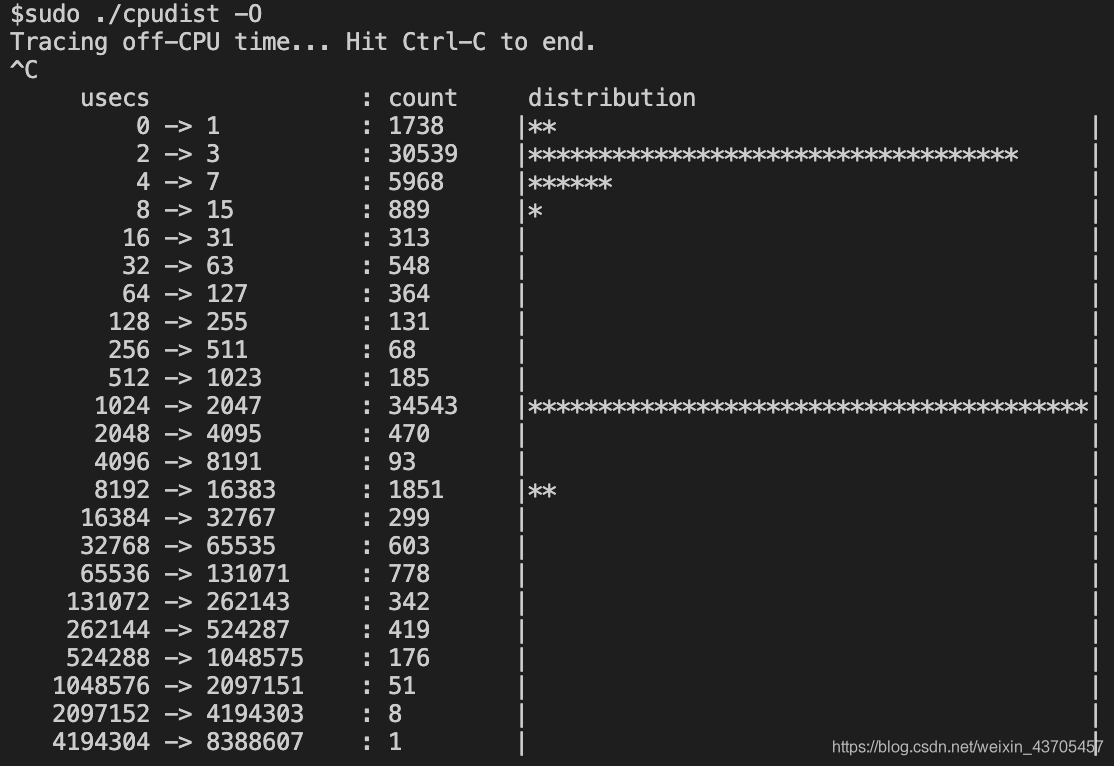
但是我们发现还有一个问题,就是虽然分析出了Off-CPU,但是如何再深入的排错呢?答案就是动态追踪,下面是一个SystemTap的代码:
global totalTime, times, execnames, switches, userStack, kernelStack
probe kernel.function("finish_task_switch") {
switches ++
now = get_cycles()
times[$prev->pid] = now
if (!times[pid()]) {
next
}
execnames[pid()] = execname() # remember name of pid
userStack[pid()] = sprint_ubacktrace()
kernelStack[pid()] = sprint_backtrace()
totalTime[pid()] = now - times[pid()]
times[pid()] = 0
}
probe timer.ms(3000) {
printf ("\n%5s %20s %10s (%d switches)\n",
"pid", "execname", "cycles", switches);
foreach ([pid] in times-) # sort in decreasing order of cycle-count
if (totalTime[pid] > 0 && pid == target())
printf ("%d %20s %10d\n%s\n------------------------\n%s\n", pid, execnames[pid], totalTime[pid], userStack[pid], kernelStack[pid]);
delete times
switches = 0
}
probe begin {
printf("strart-----------------")
}
这里的精髓其实就是对于finish_task_switch的监控,这个函数在3.10版本的内核的定义是这样的:
static void finish_task_switch(struct rq *rq, struct task_struct *prev)
在这个函数运行是prev是上一个任务,而目前正在跑的已经是新任务了(刚刚恢复),我们利用这一点在每次切换时记录prev的时间,这个时候prev被切换出去了,然后等prev被切换回来,也就是执行finish_task_switch时计算差值,这就可以较为精确的记录所有的数据,而且我们可以记录用户栈和内核栈,这样就可以很好的排查问题。
起一个redis实例,然后跟踪这个redis实例,可以得到如下输出:
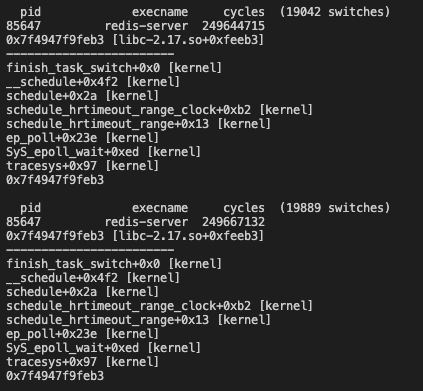
内核栈可以很容易的看出在epoll_wait的时候实例阻塞,几乎所有的切换都是由于epoll_wait,所以至少可以推断出当前的CPU不饱和。我们还看到用户栈没打出来。
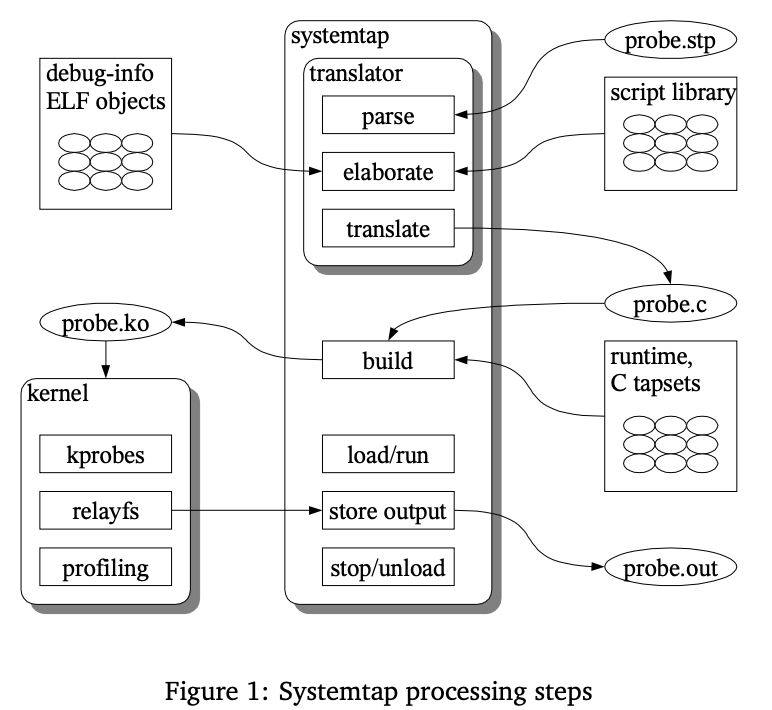
Systemtap第二步会执行符号解析,这里的原因没有载入用户态符号,所以我们应该加入-d选项载入用户态符号,即执行如下指令:
sudo stap off_cpu.stp -x <pid> -d /home/lizhaolong.lzl/redis-6.2.5/src/redis-server -d /usr/lib64/libc-2.17.so -d kernel
还有一点,redis在编译的时候最好加上-fno-omit-frame-pointer和-g,含义分别为取消栈帧中优化EBP(得到栈帧)和加入调试符号,即执行:
make -j REDIS_CFLAGS="-fno-omit-frame-pointer" REDIS_CFLAGS="-g"
这样我们就看到了全部的数据:
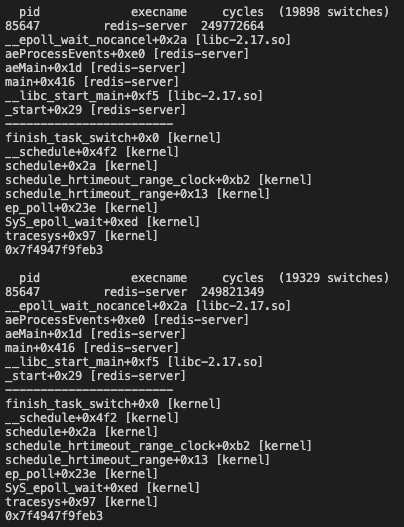
当然中间可能会报缺少某些模块的符号信息,后面跟-d就可以了。
至此,我们就可以在出现线程阻塞时分析出到底是什么原因导致了阻塞,当然SystemTap可以做,bpfTrace当然也可以做。两者在功能上我认为除了原子BPF程序的替换可以保证服务不中断以外Stap无法替代以外其实其他差不多。
缺陷
显然我们我们基于finish_task_switch统计Off-CPU数据最大的问题在于统计的数据并不全是阻塞的时间,还有处于调度器上的时间,因为当进程处于TASK_RUNNING时其实已经已经不在阻塞了,但是finish_task_switch计算的是实际被调度时的时间,所以其实中间还差一个调度器的时间,不过有兴趣可以在插入调度器时再记录加一个probe。
其次就是上下文切换不一定发生在我们上面描述的那些场景里,当CPU饱和或者进程时间片分配结束时,也会发生调度,这在我们分析Off-CPU时是没有意义的,因为这种进程的状态不会转化为TASK_UNINTERRUPTIBLE|TASK_INTERRUPTIBLE|TASK_KILLABLE,只会重新加入调度器,所以我们可以使用在SystemTap中的task_state函数,把prev中状态为TASK_RUNNING的进程全部去掉。
方法论
一个服务出现慢查询下迅速定位问题代码:
- top查看CPU负载
- 高的话分析On-CPU,低的话分析Off-CPU
- 跑cpudist查看是否是Off-CPU的问题
- 跑bcc-offcputime/Systemtap查找出现问题的堆栈
- 可以用动态追踪更加细化的分析到底是内核哪里出现问题(磁盘,网络,内存,锁)(Off-CPU过高基本是内核/资源的问题)
- 如果是On-CPU的话就从日志出发进行排错了。
总结
强大的动态追踪工具,就像一个X光一样审视着我们的代码
参考: