文章目录
管道的回顾
进程是具有独立性的—>进程通信的成本比较高—>必须先解决一个问题—>要让不同的进程看到同一份资源(内存文件,内存,队列)【一定是需要OS提供的】----> pipe的本质:是通过子进程继承父进程资源的特性,达到一个目的让不同的进程看到同一份资源
我们通常标识一个文件:路径+文件名(具有唯一性)
命名管道
为了解决匿名管道只能在父子通信,我们就引入了命名管道
命名管道可以在命令行里面弄,也可以在程序里面弄
命令行
mkfifo filename
创建管道文件

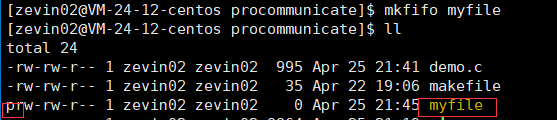
测试
:我们虽然在是同一个文件,但是在不同的进程当中
一个进程中的数据通过管道文件传递到另一个进程





代码中的使用
失败返回-1
在进程中创建一个命名管道文件,他的权限要和掩码进行按位&,我们标准情况下的掩码都是002
- umask(0)
可以将掩码设置成0
我们发现一方发的信息直接就被另一方给收到了
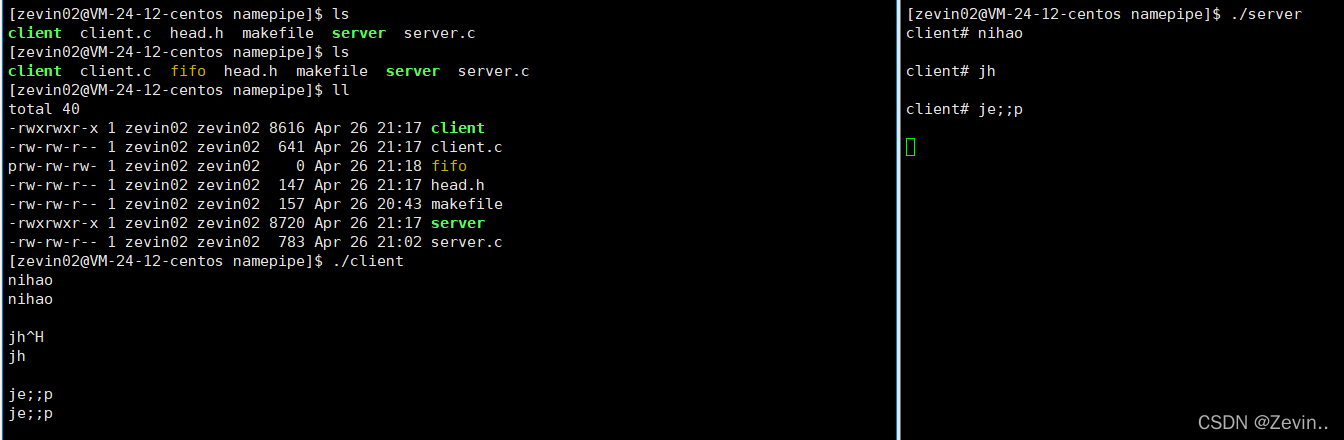
因为命名管道是基于字节流的,所以实际上信息传递的时候,是需要通信双方定制”协议“的,到网络的时候就可以了解 了,今天我们就单纯的进行字符串通信即可
进程间通信的目的:一个进程去控制另一个进程
命名管道的数据不会刷新到磁盘,为了效率

命名管道为什么一定要有名字
为了保证不同进程看到同一个文件(通过文件名来操作)所以命名管道
而匿名管道是通过父子进程的方式,看到同一份资源,所以就不需要名字,来标识同一个资源
client.c
#include"head.h"
int main()
{
//因为fifo已经创建好了,所以我们不用再创建,直接用就行了
int fd=open(MY_FIFO,O_WRONLY);
//把文件打开
if(fd<0)
{
perror("open");
return 2;
}
//业务逻辑,我们再这里进行写入
while(1)
{
printf("请输入: ");//因为没有+\n,为了避免缓冲区的问题
fflush(stdout);//刷新一下缓冲区
char buffer[64]={
0};
ssize_t s=read(0,buffer,sizeof(buffer));//我们要处理掉最后的回车键
//我们从命令行中获取输入,输入到buffer里面
if(s>0)
{
buffer[s]=0;//把最后的\0给吃掉
buffer[s-1]=0;
printf("%s\n",buffer);//读一条就发一下文件里面的内容
write(fd,buffer,strlen(buffer));//传给server
}
}
close(fd);
return 0;
}
server.c
#include"head.h"
int main()
{
umask(0);//把掩码设置为1
if(mkfifo(MY_FIFO,0666)<0)
{
perror("mkfifo");
return 2;
}
//对于管道文件,我们只需要进行文件操作即可
int fd=open(MY_FIFO,O_RDONLY,0666);
//我们让他执行读操作
if(fd<0)
{
perror("open");
return 1;
}
//执行业务逻辑
while(1)
{
char buffer[64]={
0};
//我们每个5秒才从缓冲区里面读进来
sleep(5);
ssize_t s=read(fd,buffer,sizeof(buffer));//我们对fd文件进行读取,client通过管道对fd这个文件进行写入,我们在通过这个进行读取
if(s>0)
{
//读取结束了,buffer里面就是我们需要的字符串,我们用client去控制server让他去进行操作
if(strcmp(buffer,"show")==0)
{
if(fork()==0)
{
//子进程
execlp("ls","ls","-a",NULL);//程序替换
exit(1);//如果执行失败我们就可以把退出码设置为1
}
waitpid(-1,NULL,0);//父进程执行等待
}
if(strcmp(buffer,"sl")==0)
{
if(fork()==0)
{
//子进程
execlp("sl","sl",NULL);//程序替换
exit(1);//如果执行失败我们就可以把退出码设置为1
}
waitpid(-1,NULL,0);//父进程执行等待
}
buffer[s]=0;
printf("client# %s\n",buffer);
}
else if(s==0)//我们发现client的结束的时候,文件读写结束了,就会被不断的刷屏了
{
printf("client quit....\n");
}
else
{
perror("read");
break;
}
}
close(fd);
return 0;
}
System V标准进行通信方式
在OS层面上,专门为进程间通信设计的一个方案,要不要给用户用,以什么方式给用户用?
肯定要给用户用,
OS不相信任何用户,给用户提供功能的时候,采用系统调用!
System V进程间通信,一定会存在专门原来通信的接口(system call)
所以就需要有个人组织机构来定制标准,就要有人来定制标准,在同一主机上的通信方案: system V
system V
- 共享内存
- 消息队列
- 信号量
共享内存
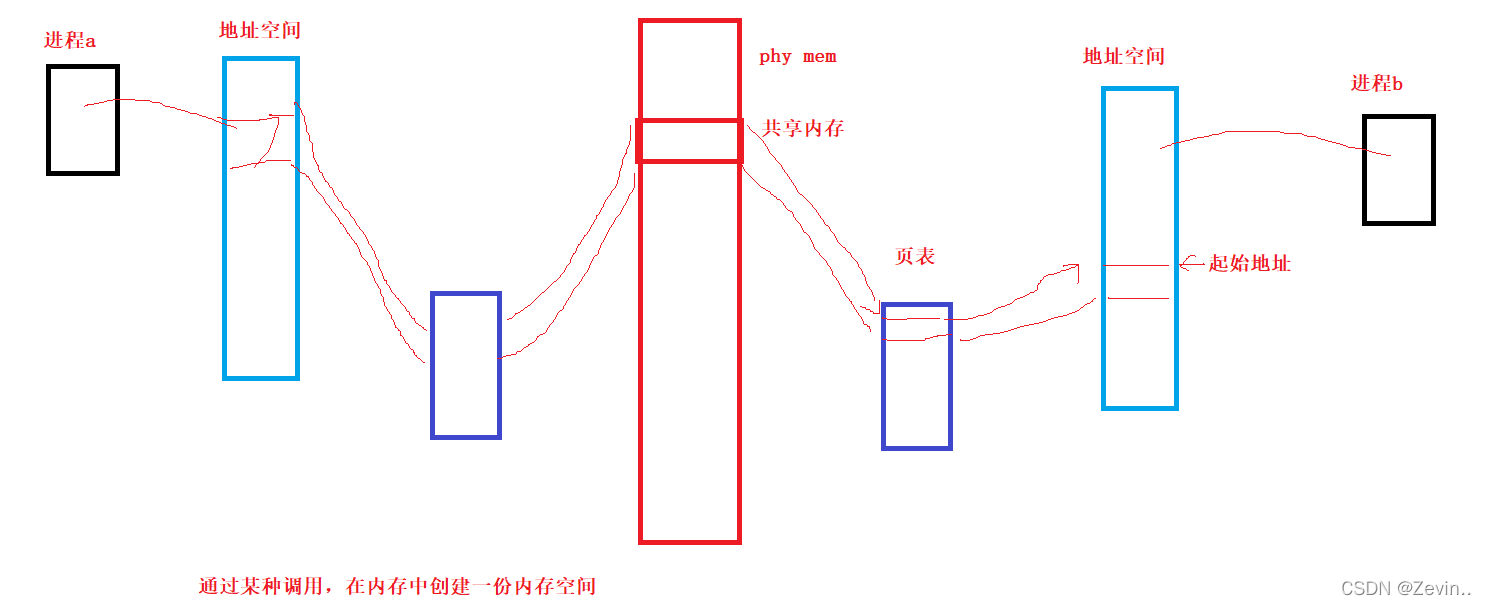

准备工作:
- OS 内存可不可能存在多个进程,同时使用不同的共享内存来通信??
可能—> 共享内存在系统中你可能有多份!—》操作系统也要管理这些共享内存,—》如何管理这些共享内存呢?—》先描述再组织(一定要有内核数据结构) - 怎么保证两个或两个以上的进程会看到同一个共享内存,(共享内存一定要有一定的标识唯一的ID),方便让不同的进程就能识别同一个共享内存的资源!!
这个ID在哪里呢,这个id就在描述的结构体里面
shmget
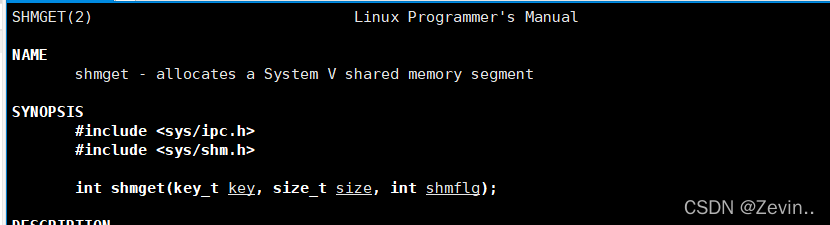
失败返回-1
创建共享内存段
- size:创建这共享内存的大小(我们一般建议是4KB的整数倍),共享内存在内核当中申请的基本单位是页,内存页(4KB)
如果我申请来了4097个字节>4KB,所以内核会向上取整,变成8KB,我们就给你4097,但是操作系统是按照4096*2的方式给你的
- shmflg:标记选项

-
IPC_CREAT:创建一个新的共享内存段,如果单独使用IPC_CREAT,或者flag为0,创建一个共享内存,如果创建的共享内存已经存在,则直接返回当前已经存在的共享内存(不存在则创建,存在就获取一个),(基本不会空手而归)
-
IPC_EXCL:一般不会单独使用的,IPC_CREAT|IPC_EXCL这两个单独使用的才有意义
如果不存在共享内存则创建,如果已经存在了共享内存,则返回出错!(意义在于,如果调用成功,得到的一定是一个最新的,没有被人使用的共享内存!) -
key:为了保证看到的是唯一的标识符,目的是为了让不同的进程来识别的,本质是可以用这标识符让不同的进程看到同一份资源:先让不同的进程看到同一个ID,
用ftok来操作
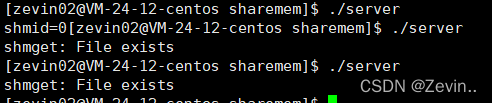
./server进程执行结束,该进程曾经创建的共享内存没有被释放,
第二次运行的时候发现他说文件已经存在(创建共享内存失败)
system V 的IPC 资源,生命周期是随内核的(只能通过程序员使用命令或者系统调用来释放,或者OS 重启)
于文件不同:文件只要和他相关的进程退出的话,那么这个文件所对应的资源也都全部被释放掉
ipc
ipcs
命令行中可以查看共享内存,消息队列,信号量
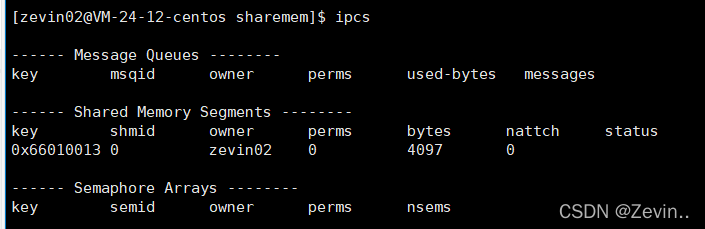
ipcs -m//只查看共享内存

ipcrm
把共享空间给删除掉
ipcrm -m shmid
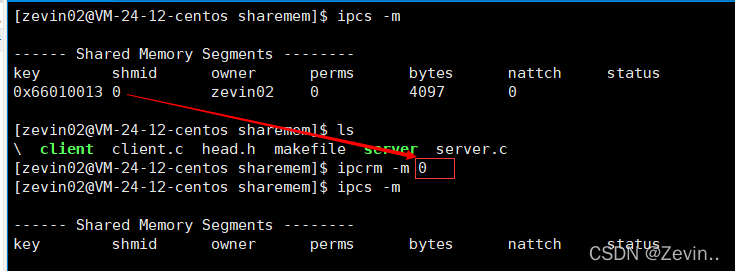
key和shmid
- key:只是用来在系统层面进行标识唯一性的,不能原来管理共享内存
- shmid:是OS 给用户返回的id,用来在用户层对共享内存进行管理
shmid相当于fd,而key相当于文件的地址
命令行是属于用户层:所以肯定是使用shmid
ftok
先调用ftok,获得key值,传给shmget
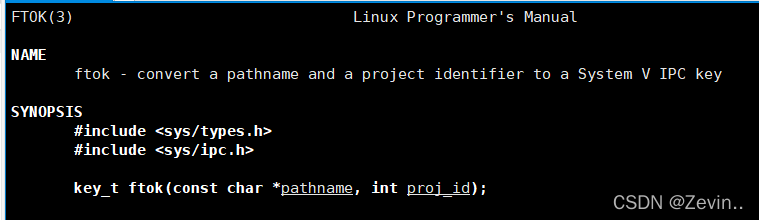
pathname :我们自定义的路径名
proj_id:我们自定义的项目id
失败了就返回-1
如我们的路径名“./temp”
项目id:0行66
这数字是什么不重要,只要保证唯一性就可以了
怎么保证不同的进程看到的是同一个共享内存?只要我们形成key的算法+原始数据是一样 的,。形成同一个id
这里的key就是会设置进内核的关于shm的内核中的数据结构中
shmctl
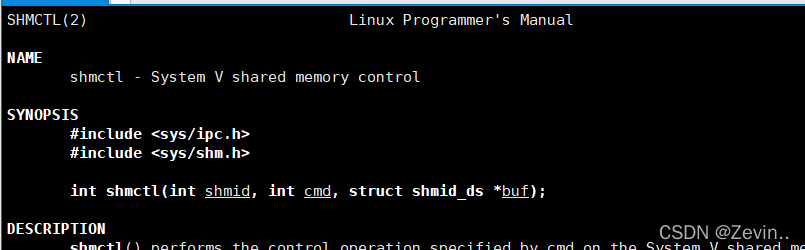
成功返回0,
shmid:就是我们shmget里面创建获得的id
cmd:IPC_RMID,把这段给销毁掉

buf:
struct shmid_ds,共享内存的结构体


shmid也是数组下标
控制共享内存(我们只了解删除)
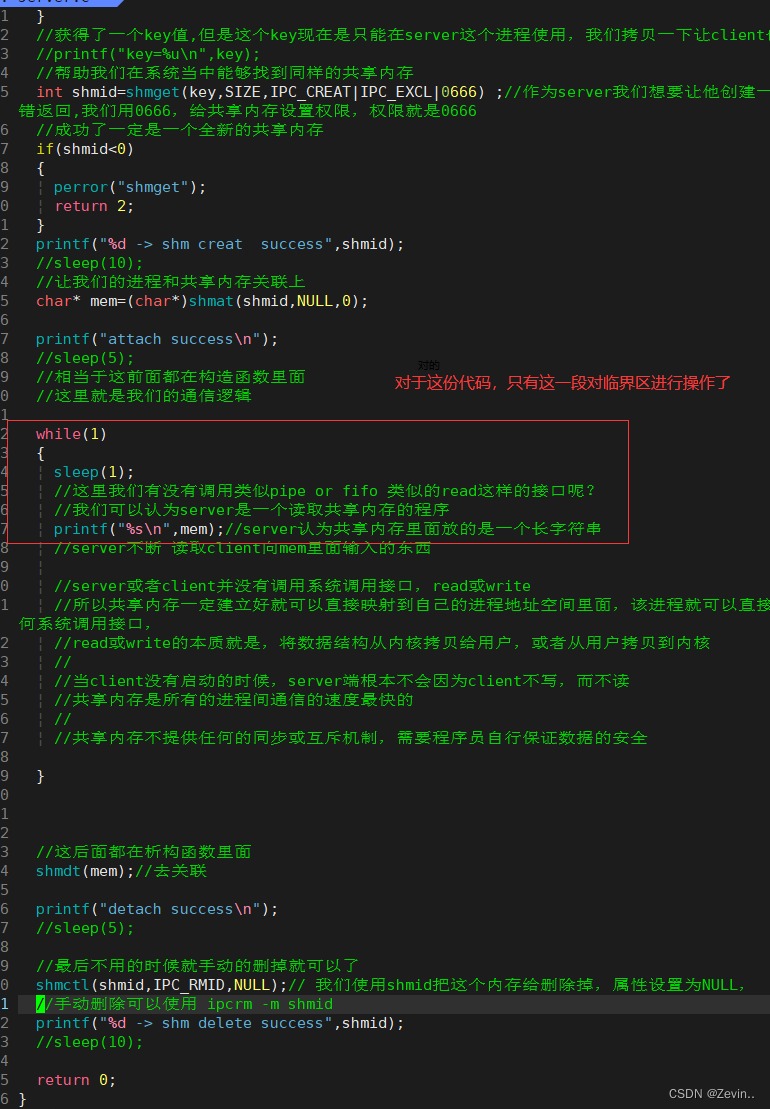
shmat shmdt
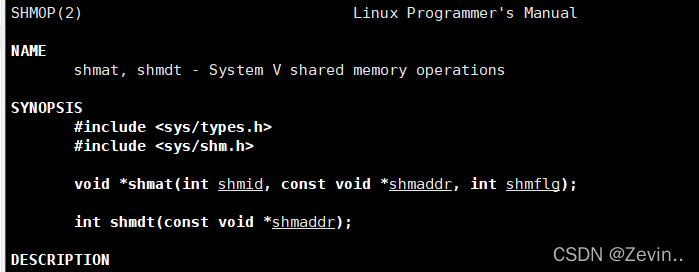
return:成功就返回那个共享空间段的地址(虚拟地址:我们程序员看到的地址都是虚拟地址,不可以看到物理地址),失败的话就返回-1
如malloc,返回的空间也都是虚拟的,相当于平白无故多了一个空间

attach:把我们调用的继承和共享内存关联起来
关联和去关联
- shmid:来表示一个共享内存,
- shmaddr:我们要挂接的时候,我们想要把它挂接到我的地址空间的什么地方去,但是我们一般不关心不清楚,所以我们就直接设置为NULL,就可以了
- shmflag:我们也直接设置为0就可以了
shmdt:去关联,并不是释放共享内存,而是取消当前进程和共享内存的关系,(和页表构建映射关系的页表项删掉)返回值不重要
参数是我们关联后的返回值
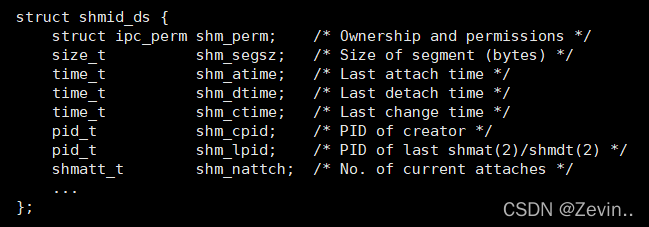
struct shmid_ds
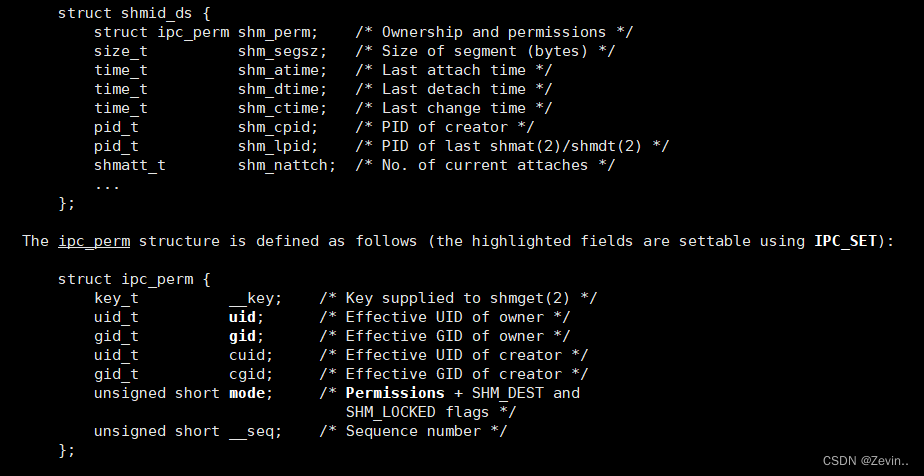
shmid_ds:权限,内存段的大小,上一次挂接的时间,上一次取消挂接的时间,创建者的pid,一共有多少个挂接
ipc_perm里面还有很多的uid,,同时还有key,我们可以根据key值找到对应的消息队列
消息队列和这个也是类似的,
- 我们会发现消息队列,信号量,共享内存,的接口类似
- 数据结构的第一个结构类型是完全一样的(struct ipc_perm)
结论:所有的ipc资源都是通过数组组织起来的,
所有的System V 标准的IPC 资源,XXid_ds结构体的第一个成员都是ipc_perm(这个是一样的,)
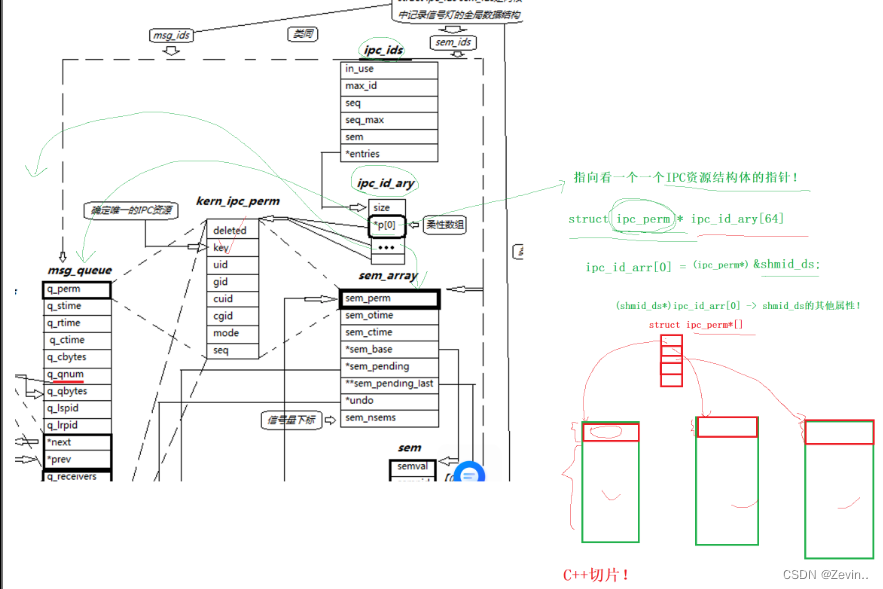
这些数组可以给我们指向不同的结构体,使用数组的下标
指向一个一个IPC资源的结构体指针
struct ipc_perm* ipc_id_arry[64]
ipc_id_arry[0]=(ipc_perm)&shmid_ds;我们通过强转,
当我们需要使用第一个资源的时候不需要强转,当我们使用其他资源的时候就需要强转
(shmid_ds*)ipc_id_arry[0]->shmid_ds的其他属性
相当于c++的切片功能
信号量
临界资源
所有可以被多个执行流同时访问的资源就是临界资源,
例如:
多进程启动后同时向显示器打印,这个显示器就是所谓的临界资源
而我们在学习进程间通信的时候,管道,共享内存,消息队列等,不同的进程能够同时访问
共享内存是最典型的共享资源
所以凡是进程间通信,必定需要引入可以被多个进程看见的资源(通信需要),这一份资源就变成了临界资源,同时,也引入一个新的问题:临界资源的问题
但是我们在进程中定义一个全局变量,之后fork子进程,但是这个全局变量不是临界资源,因为子进程如果对这个数据进程修改的话,会发生写实拷贝
临界区
进程的代码可以很多的,其中用来访问临界资源的代码叫做临界区
类似显示器:
显示器叫做临界资源,在显示器中printf叫做临界区
原子性
一件事情要么不做,要么就做完,没有中间态,就叫做原子性
非原子性:有中间过程
比如学习,要么啥也不学,要么就考第一名,
//在多进程中,定义了一个全局变量
int cout=100;//
//多进程=父+子
cout--; cout--;//父子都-
父和子对于cout处理不同
这里的cout不是原子的,cout是为了保护临界资源的
每个人想要进入电影院,必须要先看到cout,
cout本身就是也是临界资源的
所以信号本身就是临界资源的,
互斥
在任意时刻只能允许一个执行流进入临界资源,执行他的临界区
sem=1//临界资源只有一份
if(sem>0)
sem--;//进入--
else if(sem<=0)
{
//等待,进入临界区执行
}
sem++;//出去++
只有0和1就叫做2元信号量
什么是信号量
管道,匿名or命名,共享内存,消息队列,都是以传输数据为目的的!
信号量不是以传输数据为目的的!通过共享内存“资源的方式”,来达到多个进程的同步和互斥的目的!
信号量的本质:
是一个计数器,类似 int count :衡量临界资源的中资源的数目的
- 在电影院的某一个放映厅也是一个临界资源!可以被不同的人访问,我们在进去的时候别人也可以进去,
- 并不是我们坐在这个位置上,这个位置才属于我们,在外面买到票的时候,这座位就已经属于我们了,
- 而买票的本质:对临界资源的预定机制
一个放映厅最怕什么?一共有100个座位,卖了110张票,所以最多只能买100张票,---------用信号量来约束这行为
信号量本身一个临界资源
所以信号量的p操作和delete操作就是必须保证是原子的
int count=100;
cout--;//一个人买走了一张票
//愉快的看电影
cout++;//访问电影院的人出去了,
信号量的伪代码
if(cout>0)
cout--;
else
{
//等待
}
cout++;