文件I/O---->缓冲
文件IO的内核缓冲:缓冲区高速缓存
read()和write()系统调用在操作磁盘文件时不会直接发起磁盘访问,而是在用户缓冲区与内核缓冲区高速缓存之间复制数据
例如: 如下调用将3个字节的数据从用户空间传递到内核空间的缓冲区中:
write(fd,"asd",3);
write()随即返回. 在后续的某个时刻,内核会将缓冲区的数据写入(刷新)至磁盘.可以说 系统调用与磁盘操作并不同步,如果在此期间,另一进程试图读取该文件的这几个字节,那么内核将自动从缓冲区高速缓存中提供这些数据,而不是从文件中(读取过期的内容)
与此同理,对输入而言,内核从磁盘中读取数据并存储到内核缓冲区中。read()调用将从该缓冲区中读取数据,直至把缓冲区中的数据取完,这时,内核会将文件的下一段内容读入缓冲区高速缓存(对于序列化的文件访问,内核通常会尝试执行预读,以确保在需要之前就将文件的下一数据块读入缓冲区高速缓存中)
采用这一设计,意在使 read()和 write()调用的操作更为快速,因为它们不需要等待(缓慢的)磁盘操作
Linux内核对缓冲区的大小没有固定的上限,其仅受限于两个因素:可用于的物理内存 以及出于其他目的对物理内存的需求. 若可用内存不足,内核会将一些修改过后的缓存区高速缓存页刷新到磁盘,并释放其供系统重用;
缓冲区大小对IO系统调用性能的影响
当传输总量相同时 缓冲区大小为 1 字节时,需要调用 read()和 write()1亿次,缓冲区大小为 4096 个字节时,需要调用 read()和 write() 24000 次左右,几乎达到最优性能。设置再超过这个值,对性能的提升就不显著了,这是因为与在用户空间和内核空间之间复制数据以及执行实际磁盘 I/O 所花费的时间相比,read()和 write() 系统调用的成本就显得微不足道了
总之,如果与文件发生大量的数据传输,通过采用大块空间缓冲数据,以及执行更少的系统调用,可以极大地提高 I / O 性能。
stdio库的缓冲
简介
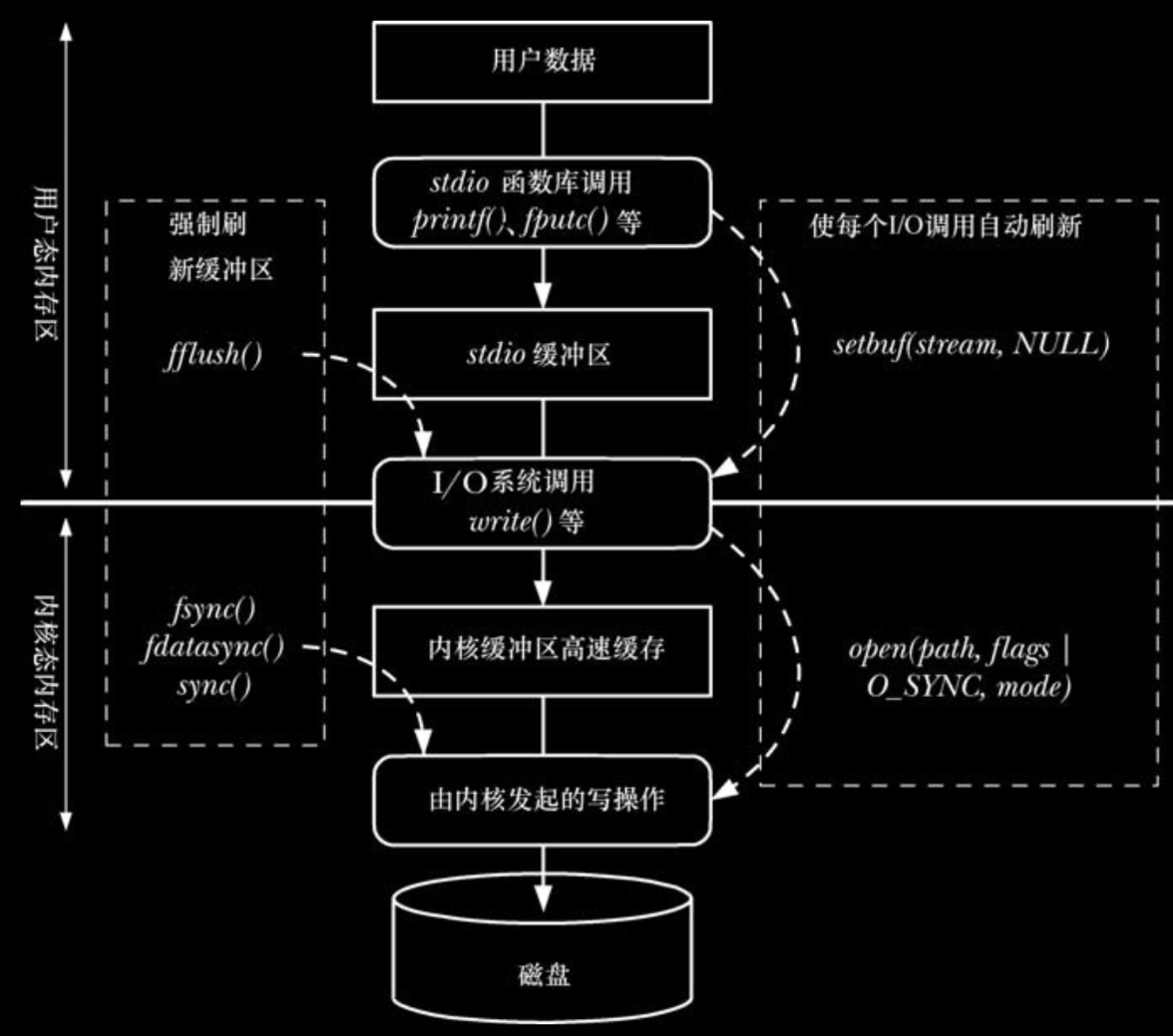
当操作磁盘文件时,缓冲大块数据以减少系统调用,C 语言函数库的 I/O 函数(比如,fprintf()、fscanf()、fgets()、fputs()、fputc()、fgetc())正是这么做的。因此,使用 stdio 库可以使编程者免于自行处理对数据的缓冲,无论是调用 write()来输出,还是调用 read()来输入。
设置一个stdio流的缓冲模式
setvbuf()函数:
调用setvbuf()函数,可以控制stdio库使用的缓冲的形式.
#include <stdio.h>
int setvbuf(FILE * stream,char *buf,int mode,size_t size);
!!setvbuf() 出错时返回非 0 值 **(而不一定是−1)**。
参数 stream 标识将要修改哪个文件流的缓冲。打开流后,必须在调用任何其他 stdio 函数之前先调用 setvbuf()。setvbuf()调用将影响后续在指定流上进行的所有 stdio 操作。
参数buf和size则针对参数stream要使用的缓冲区,指定的参数有如下两种方式.
- 如果参数buf不为NULL,那么指向size大小的内存块将作为stream的缓冲区.(其应为malloc()或类似函数在堆区或静态变量区分配的一块空间,而不应是分配在栈上的函数本地变量。否则,函数返回时将销毁其栈帧,从而导致混乱)
- 若buf为NULL,那么stdio库会为stream自动分配一个缓冲区,该场景下会忽略size参数
- 参数mode指定了缓冲类型,并具有下列值之一
- _IONBF
不对 I/O 进行缓冲。每个 stdio 库函数将立即调用 write()或者 read(),并且忽略 buf 和 size参数,可以分别指定两个参数为 NULL 和 0。stderr 默认属于这一类型,从而保证错误能立即输出。 - _IOLBF
采用行缓冲 I/O。指代终端设备的流默认属于这一类型。对于输出流,在输出一个换行符(除非缓冲区已经填满)前将缓冲数据。对于输入流,每次读取一行数据。 - _IOFBF
采用全缓冲 I/O。单次读、写数据(通过 read()或 write()系统调用)的大小与缓冲区相同。指代磁盘的流默认采用此模式
- _IONBF
setbuf()函数:
setbuf()函数构建在setvbuf()之上,执行了类似任务
#include<stdio.h>
void setbuf(FILE *stream, char *buf);
setbuf(fp,buf)调用除了不返回函数结果外,就相当于
setvbuf ( fp,(buf==NULL) ? _IONBF : _IOFBF,BUFSIZ ) ;
fflush()刷新stdio缓冲区
无论当前采用何种缓冲形式,都可以用fflush()函数强制将stdio输出流中的数据强制刷新到内核缓冲区中.
#include <stdio.h>
int fflush(FILE* stream);
若stream==NULL 则fflush()将刷新所有的stdio缓冲区.
也能将fflush()函数应用于输入流,这将丢弃以缓冲的输入数据
当关闭相应流时 自动刷新stdio缓冲区.
在包括 glibc 库在内的许多 C 函数库实现中,若 stdin 和 stdout 指向一终端,那么无论何时从 stdin 中读取输入时,都将隐含调用一次 fflush(stdout)函数。这将刷新写入 stdout 的任何提示,但不包括终止换行符(比如,printf(“Date:”))。然而,SUSv3 和 C99 并未规定这一行为,也并非所有的 C 语言函数库都实现了这一行为。要保证程序的可移植性,应用应使用显式的 fflush(stdout)调用来确保显示这些提示。
控制文件IO的内核缓冲
强制刷新内核缓冲区到输出文件是可能的,并且有时很重要
同步IO数据完整性和同步IO文件完整性
同步I/O完成-定义为:某一 I/O 操作,要么已成功完成到磁盘的数据传递,要么被诊断为不成功
SUSv3 定义的第一种同步 I/O 完成类型是 synchronized I/O data integrity completion ,旨在确保针对文件的一次更新传递了足够的信息(到磁盘),以便于之后对数据的获取
- 就读操作而言,这意味着被请求的文件数据已经(从磁盘)传递给进程
- 就写操作而言,这意味着写请求所指定的数据已传递(至磁盘)完毕,且用于获取数据的所有文件元数据也已传递(至磁盘)完毕
Synchronized I/O file integrity completion 是 SUSv3 定义的另一种同步 I/O 完成 是synchronized I/O data integrity completion 的超集该 I/O 完成模式的区别在于在对文件的一次更新过程中,要将所有发生更新的文件元数据都传递到磁盘上,即使有些在后续对文件数据的读操作中并不需要
- data 类型是指将足够的信息(data)传到磁盘
- file 类型是将所有文件信息(file)传到磁盘
用于控制文件IO内核缓冲的系统调用函数
fsync()
- fsync()系统调用将使缓冲数据和与打开文件描述符 fd 相关的所有元数据都刷新到磁盘上。调用 fsync()会强制使文件处于 Synchronized I/O file integrity completion 状态。(data的超集)
#include <unistd.h>
int fsync(int fd); // return 0 to success,-1 to error;
仅在对磁盘设备(或者至少是其高速缓存)的传递完成后,fsync()调用才会返回。
fdatasync()
- fdatasync()系统调用的运作类似于fsync() ,只是强制文件处于ynchronized I/O data integrity completion 的状态。
#include <unistd.h>
int fdatasync(int fd); // returns 0 to success , -1 on error;
通过 open的flag 使所有同步写入:
–> O_SYNC
调用open()函数时指定O_SYNC 则会使所有后续输出同步
fd=open(payhname,O_SYNC|O_WRONLY)
在调用open函数时添加O_SYNC 之后的每个write函数将会自动将文件数据和元数据刷新到磁盘上(即 按照*************data**************模式进行操作)
采用 O_SYNC 标志(或者频繁调用 fsync()、fdatasync()或 sync())对性能的影响极大
–> O_DSYNC 和 O_RSYNC 标志
同样的 SUSv3 规定了两个与同步IO相关的打开文件标志状态 O_DSYNC 和 O_RSYNC
- O_DSYNC 标志要求按照(data模式执行)
- O_SYNC 标志要求按照(file模式执行)
- O_RSYNC 标志是和上两个结合进行使用的
- 同时指定 O_RSYNC 和 O_DSYNC 标志,那么就意味着会遵照 synchronized I/O data integrity completion (即,在执行读操作之前,像执行 O_DSYNC 标志一样完成所有待处理的写操作)
- 同时指定 O_RSYNC 和 O_SYNC 标志,则意味着会遵照 synchronized I/O file integritycompletio (即,在执行读操作之前,像执行 O_RSYNC 标志一样完成所有待处理的写操作)
IO缓冲小节
绕过缓冲区直接IO
直接 I/O 只适用于有特定 I/O 需求的应用。例如数据库系统,其高速缓存和 I/O 优化机制均自成一体,无需内核消耗 CPU 时间和内存去完成相同任务。
- 直接IO的使用方式是—> 用open()打开文件或设备时指定O_DIRECT标志
直接IO的对齐限制
因为直接IO涉及对磁盘的直接访问,所以在执行IO时 需要遵守以下限制
- 用于数据传递的缓冲区,其边界必须对齐为块的整数倍大小
- 数据传输的开始点,即文件设备的偏移量 ,必须为块的大小的整数倍
- 待传输数据的长度必须是块大小的整数倍
不遵守上述任一限制将EINVAL错误,(上述 块大小为物理块的大小)
混合使用库函数与系统调用进行IO操作
#include <stdio.h>
int fileno(FILE* stream);
return file descriptor on success , or -1 on error
FILE* fdopen(int fd,const char * mode);
return (new) file opinter on success , or NULL on error
fileno()
给定一个文件流 返回他相应的文件描述符(即stdio库在流上已经打开的文件描述符)
随即可以在read()write()dup()fcntl()系统调用中正常使用该文件描述符;
fdopen()
与fileno()函数功能相反.给定一个文件描述符,该函数创建了一个使用该描述符进行文件IO想相应流.返回一个(文件)流,mode参数和fopen参数中mode参数相同(w a r,写 追加 读…)
如果 该文件描述符 与函数中mode的访问模式不一致,则对fdopen()函数的调用失败
fdopen函数对非常规文件描述符很有用 在创建套接字和管道的系统调用总是返回文件描述符.为了在这些文件类型上使用stdio的库 则必须使用fdopen()函数创建相应的文件流
混合使用的缓冲问题
在进行库调用和系统调用时,应将缓冲问题牢记IO的系统调用将直接吧数据冲到内核缓冲区高速缓存,而stdio库函数需要等待用户空间的缓冲区填满时,再调用write()函数将缓冲区数据从入内核缓冲区高速缓存
将IO系统调用和stdio函数混合使用时,使用fflush()来规避这些问题,同时也可以使用setvbuf()或setbuf()函数使缓冲区失效 但这么做会影响IO性能 因为每次输出操作将引起一次write()系统调用
总结
输入输出数据的缓冲由内核和 stdio 库完成。有时可能希望阻止缓冲,但这需要了解其对应用程序性能的影响。可以使用各种系统调用和库函数来控制内核和 stdio 缓冲,并执行一次性的缓冲区刷新。
在 Linux 环境下,open()所特有的 O_DIRECT 标识允许特定应用跳过缓冲区高速缓存。
在对同一个文件执行 I/O 操作时,fileno()和 fdopen()有助于系统调用和标准 C 语言库函数的混合使用。给定一个流,fileno()将返回相应的文件描述符,fdopen()则反其道而行之,针对指定的打开文件描述符创建一个新的流。