引言
简单浏览了下ICDE 2023 industry-and-applications-track 部分的文章,其中我感兴趣的文章有三篇,分别为:
- Accelerating Cloud-Native Databases with Distributed PMem Stores
- Backward-Sort for Time Series in Apache IoTDB
- Firestore: The NoSQL Serverless Database for the Application Developer
当然最关心的就是当前这一篇了,简单浏览了一下摘要和介绍,发现这篇文章提到了一个实现和我最近做的东西很类似,即在另外一个系统之上建立一层多租户层。尤其是当底层系统是偏向于分析型场景时,因为此时一个RPC请求的资源消耗基本无法准确预测,此时请求本身无法作为隔离指标,遂需要在其他维度解决这个问题。
Firestore卖点
文章中放在摘要和介绍部分的必然是这个系统最为人称道的地方。可以看到字里行间中都透露这FireStore对于用户友好这一点的自豪,具体到点分为以下几个方面:
| 分类 | 细节 |
|---|---|
| 移动端友好 | 1. schemaless 2. ACID 3. 强一致性 4. 默认每个字段都存在索引 |
| 实时通知能力 | 增量推送变化的实时查询 |
| 处理工作负载高峰的可扩展性 | 挺扯淡的,建议用户五分钟内流量不要上涨50%,且建议qps从500开始[3] |
| 灵活的按需计费,且提供每天部分免费配额以吸引用户 | 这部分看起来并不是RU,而是记录日志,对接外部计费系统,这意味着Google还是不看好RU的 |
| 终端用户可以访问数据库 | 终端用户的firestore操作直接路由到firestore,不需要专门的服务器进行访问控制,得益于开发者设置的安全规则[4][5] |
| 断线操作 | 移动设备可能在任意长时间内断开网络连接,应用程序需要在断开网络连接后部分服务人就成功,并在连接上网络后进行自动调节。大幅减少开发一个app的门槛 |
| Write Triggers | 触发器,和Google Cloud Functions对接。这个后续我们的产品倒是可以参考,目前没看到别家厂商这么玩 |
文章贡献
- 从单一底层的关系型数据库之上建立一个多租户数据库服务。
- 多租户架构如何支持快速扩展,高可用性,数据完整性和隔离性
- 客户端SDK库如何实现断开连接操作。如何计算并向客户端发送实时查询的通知更新。以及这些更新如何以一致的方式展现给终端用户
事实上这篇文章大部分篇幅用来描述如何以Spanner为底层存储系统的情况下实现查询,实时查询和写操作,但这不是我关心的部分,所以这篇文章不会提到操作实现部分的内容。
多租户与隔离
Firestore的所有组件和Spanner都在大量firestore中共享,特定组件中的任务数量会根据负载情况进行调整。
一个问题是一个数据库实例的流量可能消耗一个或者多个组件的全部或者绝大多数的资源来影响其他数据库实例的可用性,挑战如下:
- 一个独立的RPC不是一个统一的工作单位,不同的rpc之间资源消耗差异巨大,且请求本身无法预测消耗
- 瓶颈集中在Firestore后端的内存CPU隔离以及Spanner的CPU隔离
- 流量可能存在明显波峰
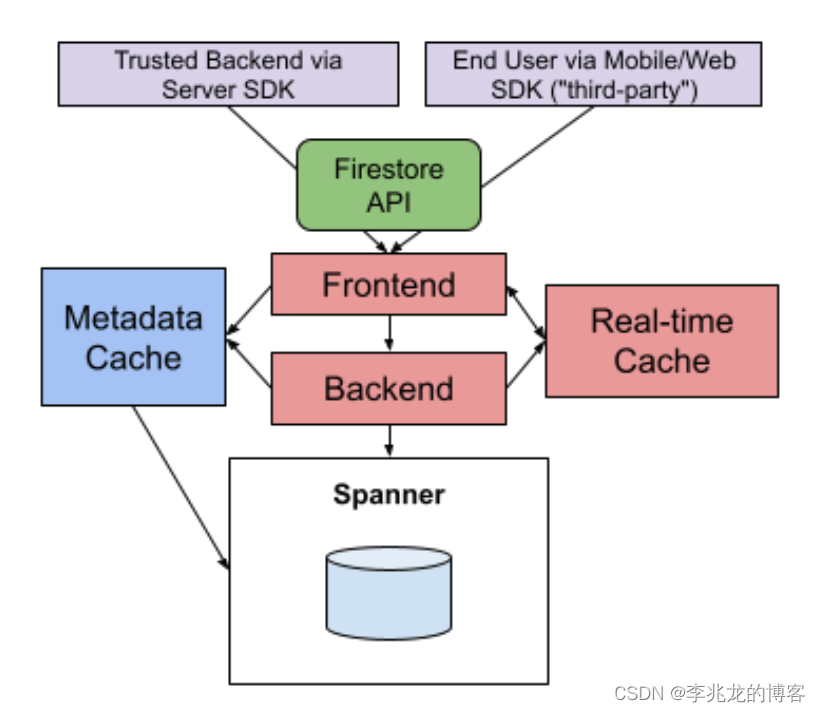
上面的挑战配合这这幅图来说,就是Fronted负责路由,瓶颈集中在Backend的CPU/内存和Spanner的CPU,需要处理波峰和大查询影响其他租户。
解决方案:
- 后端任务中使用了一个公平的CPU共享调度器,以租户ID作为key。
- 把租户ID传递给spanner,spanner内部设置了类似的公平CPU调度器。
- 此外某些批处理和内部工作负载在RPC上打上标签,使得延迟敏感的业务可以优先于这部分RPC(本质上就是本身没有能力辨别,需要用户介入隔离慢查询)。其实很多DB没有做慢查询的原因是过于复杂,不是所有的数据库都像Redis这样可以相对无理论压力的情况加入慢查询隔离,如果设计之初没有考虑到后续想做就难了,从这个角度看我推测后续可能会有论文以这里为创新点。
- 限制结果集和和单个RPC的工作量,API上允许先返回一部分数据,后续返回剩下的数据。本质上是小粒度的请求和资源消耗是有明显基线的,这也是KV系统使用Retro就可以很好的做到隔离的原因。文章中的做法其实就是流式查询,流式查询是为了解决数据量超大是对接入层内存威胁而引入的,但是以我的实际运营经验来看这样做问题也很大。。)
- 遇到两个需要大量内存多RPC的极端情况;需要限定给定数据库正在执行的查询的数量;或者流量导入到独立池中。这样做本质的原因是内存还是没隔离好。
- 为了防止用户请求波峰,Firestore要求符合要求的流量逐步增长,每分钟做多增加百分之五十,从500qps基础开始。(过于愚蠢)
总的来看,从
功能
- 为了减少管理成本,文档的每一个字段上都定义了一个升序索引和一个降序索引。防止某些频繁更新的字段造成写入瓶颈,允许用户指定字段不需要索引。
- Firestore支持强一致性的,或者最近时间点的点查,为了更好的使用缩影,一个查询最多有一个不等式谓词,且必须与第一个排序顺序匹配。
- 实时查询报告了一系列带有时间戳的快照,快照为与前一个快照的增量变化,文章中举量一个带删除的例子,实际不会返回给用户这个delete操作。这与时序数据库中的Rollup Cache思路类似,不过后者核心原因是存储资源过剩,可以保留部分查询结果,这对于BI分析等常见可以节省大量CPU资源。这里我想表达的核心逻辑其实是实时查询显然只查询一部分时间就可以。
- SDK客户端维护了一个缓存和索引,使用本地缓存加速访问,收到实时通知时更新,断开连接后可以使用本地缓存,连接网络时更新,且查询命中本地缓存不收费
其他经验
- firestore新版本发布后会立即影响用户流量,所以需要严格的灰度流程;在同一个地区缓慢推出配置和代码,然后才在多区域逐渐推出;使用自动化多A/B测试,对多个指标进行分析,看起来像是金丝雀发布,这在Google系统架构解密中有提到
- 数据完整性的问题,需要提防机器静默错误[8][9]。基本上没有运营经验是不会感觉到这种事情的恐怖的。入职一年不到,现在我已经经历过CPU损坏导致位翻转,磁盘跳变,网卡重启,数据中心断网等等以前完全认为不会发生的事情。这里需要提到的主要是三个事情;一为如何快速发现;二为如何恢复数据;三为控制面中故障检测与剔除部分如何快速且精确识别故障机器;
总结
这篇文章显然是一篇摸鱼文章。写下这篇文章的本质原因是我在看到摘要和介绍的时候以为Google的工程师们解决了这个我们头疼不已的问题,但原来还是和我们一样都是蒙起自己和客户的眼睛。
我理解这篇文章重点还是在介绍Firestore的卖点和实际读写,实时读的实现上。但是我感兴趣的还是他的架构实现,从我看文章的角度来看与[10]还是有不小的差距,无聊的一篇文章,但是看都看了,笔记也记了,不如听着歌润色一个半小时水一篇博客。

参考:
3. Firestore: The NoSQL Serverless Database for the Application Developer
4. 从一到无穷大 #7 Database-as-a-Service租户隔离挑战与解决措施
5. https://firebase.google.com/docs/firestore/best-practices#ramping_up_traffic
6. https://firebase.google.com/docs/rules#key_capabilities
7. https://firebase.google.com/docs/auth
8. Cores that don’t count
9. Silent Data Corruption at Scale
10. Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service