目录
clone
clone是Linux系统中的一个系统调用,可以用于创建新进程或新线程。它是fork系统调用的一种更加灵活的替代方案,不仅可以创建新的进程,还可以在同一个进程内创建新的线程,同时可以精确地控制各项资源的共享情况,例如内存、文件描述符、信号处理等。
clone系统调用的调用方式类似于fork,但是它接受一个额外的参数flags,用于指定新进程或新线程的属性和行为。常用的flags包括:
- CLONE_VM:共享进程的地址空间
- CLONE_FILES:共享进程的文件描述符
- CLONE_FS:共享进程的文件系统信息
- CLONE_SIGHAND:共享进程的信号处理器
- CLONE_THREAD:创建新的线程而不是进程
- CLONE_NEWPID:创建新的PID命名空间
- CLONE_NEWNET:创建新的网络命名空间
clone系统调用可以用于实现轻量级线程,例如在一个进程内创建多个轻量级线程,共享进程的资源,但是可以通过设置不同的栈和程序计数器来执行不同的任务。同时,由于不需要像fork那样复制整个进程的地址空间,因此clone调用的开销相对较小,可以更加高效地实现并发编程。
---
pcb
PCB(Process Control Block,进程控制块)是操作系统中用于管理进程的数据结构,是操作系统内核中一个重要的数据结构。每个进程在创建时都会分配一个唯一的PCB,用于存储进程的状态信息、程序计数器、寄存器、内存地址、文件描述符、调度信息等各种进程相关的信息。
PCB通常包括以下几个方面的信息:
- 进程标识符(Process ID,PID):唯一标识一个进程的数字。
- 进程状态(Process State):表示进程当前的状态,例如就绪、运行、阻塞等。
- 程序计数器(Program Counter,PC):指向进程当前执行的指令的地址。
- 寄存器(Registers):保存进程的寄存器状态,包括通用寄存器、标志寄存器等。
- 内存地址(Memory Address):保存进程的内存地址信息,包括代码段、数据段、堆栈等。
- 文件描述符表(File Descriptor Table):保存进程打开的文件的相关信息。
- 调度信息(Scheduling Information):保存进程的调度信息,例如优先级、时间片等。
PCB在操作系统中起着非常重要的作用,它使得操作系统能够有效地管理多个进程,实现进程的创建、调度、阻塞、唤醒等各种操作。同时,PCB也是实现多进程通信的基础,例如通过共享内存、消息队列等机制实现进程间的数据共享和通信。
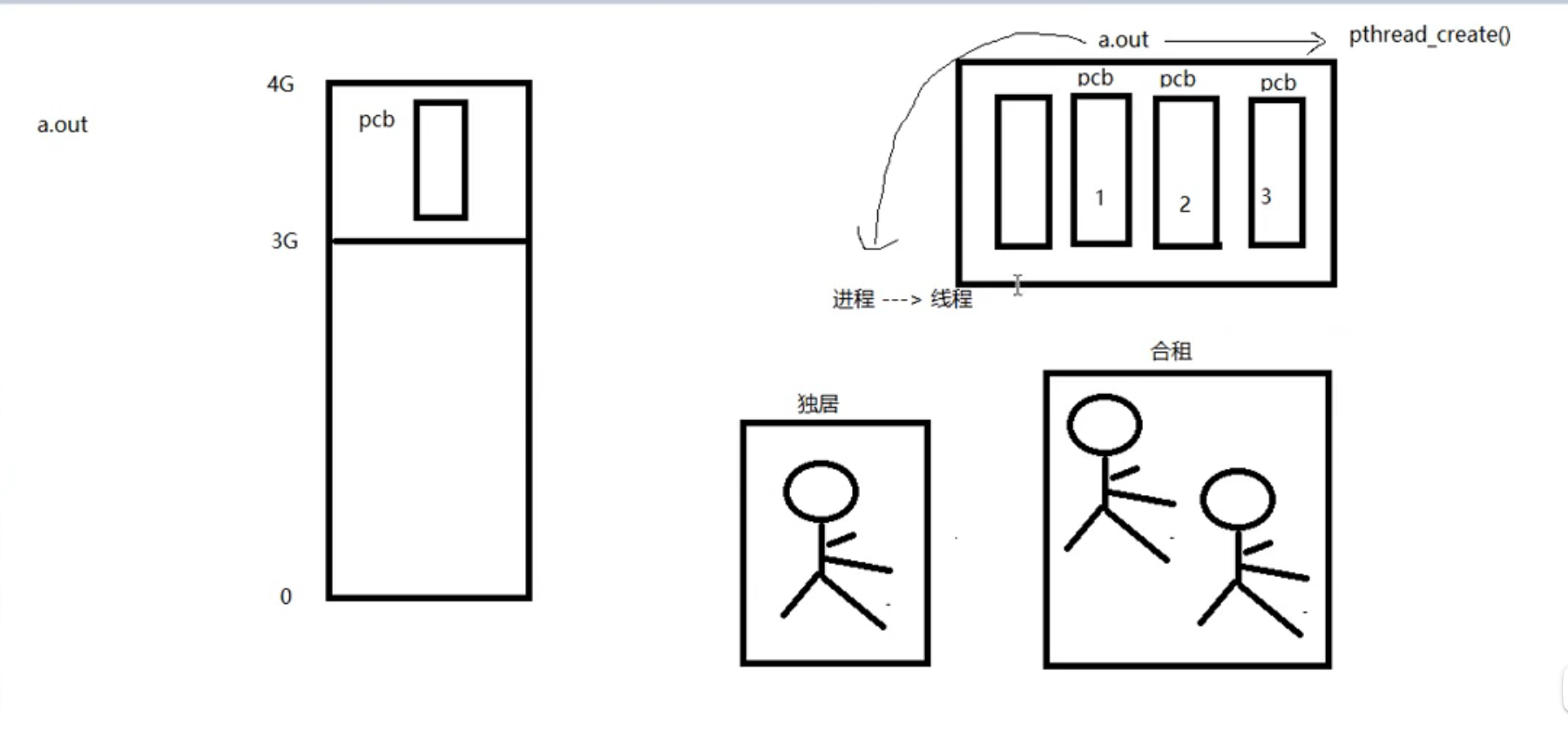
一个进程多个pcb
在一个进程中多个PCB的情况,通常称为线程(Thread)。
线程是进程的一部分,它与进程共享进程的内存、文件和其他资源,但是拥有自己的程序计数器、栈和寄存器等信息。线程是进程中的一个执行流,它可以独立地执行指令序列,但是它与同一进程中的其他线程共享进程的资源,因此可以更加高效地实现并发编程。
在同一个进程中,可以创建多个线程,并且这些线程共享进程的资源。例如,多个线程可以同时读写同一个文件,或者同时访问同一个共享内存区域。同时,由于线程之间的切换开销比进程之间的切换开销小得多,因此多线程编程可以更加高效地利用CPU资源。
需要注意的是,由于多个线程共享进程的地址空间和文件描述符表等资源,因此在多线程编程中需要注意线程之间的同步和互斥问题,以避免出现数据竞争等问题。
总之,在一个进程中创建多个PCB,即多个线程,可以更加高效地实现并发编程,提高程序的执行效率和响应速度。
---
主线程创建完副线程后,主、副线程在干嘛啊,哎哟~
在主线程创建完副线程后,主线程和副线程可能会同时执行,各自完成各自的任务。具体来说:
-
主线程可能会执行其他任务,例如接收输入、处理事件、计算等,而不必等待副线程完成。主线程可以通过调用
pthread_join函数等待副线程结束,并在等待期间执行其他任务。 -
副线程可能会执行分配给它的任务,例如计算、文件操作、网络通信等,在执行过程中可能会与其他线程竞争共享资源。副线程可以使用线程同步机制(例如互斥量、条件变量等)来确保对共享资源的访问不会导致数据竞争和其他并发问题。
-
如“ 主副线程共享全局变量 ”中的副线程执行的是下面的任务:
-
void *worker_thread(void *threadarg) { printf("Worker thread started.\n"); while (1) { printf("Worker thread updating global variable.\n"); global_variable++; printf("Worker thread finished.\n"); break; } printf("Main thread waiting for worker thread to finish.\n"); pthread_exit(NULL); }
-
需要注意的是,在多线程编程中,主线程和副线程之间可能会存在一些并发问题,例如数据竞争、死锁、优先级反转等。为了避免这些问题,需要使用适当的线程同步机制,并确保线程之间的通信和同步是正确和安全的。
此外,还需要注意在程序退出前,要等待所有副线程都结束,并释放它们占用的资源,以避免资源泄漏和其他问题。
---
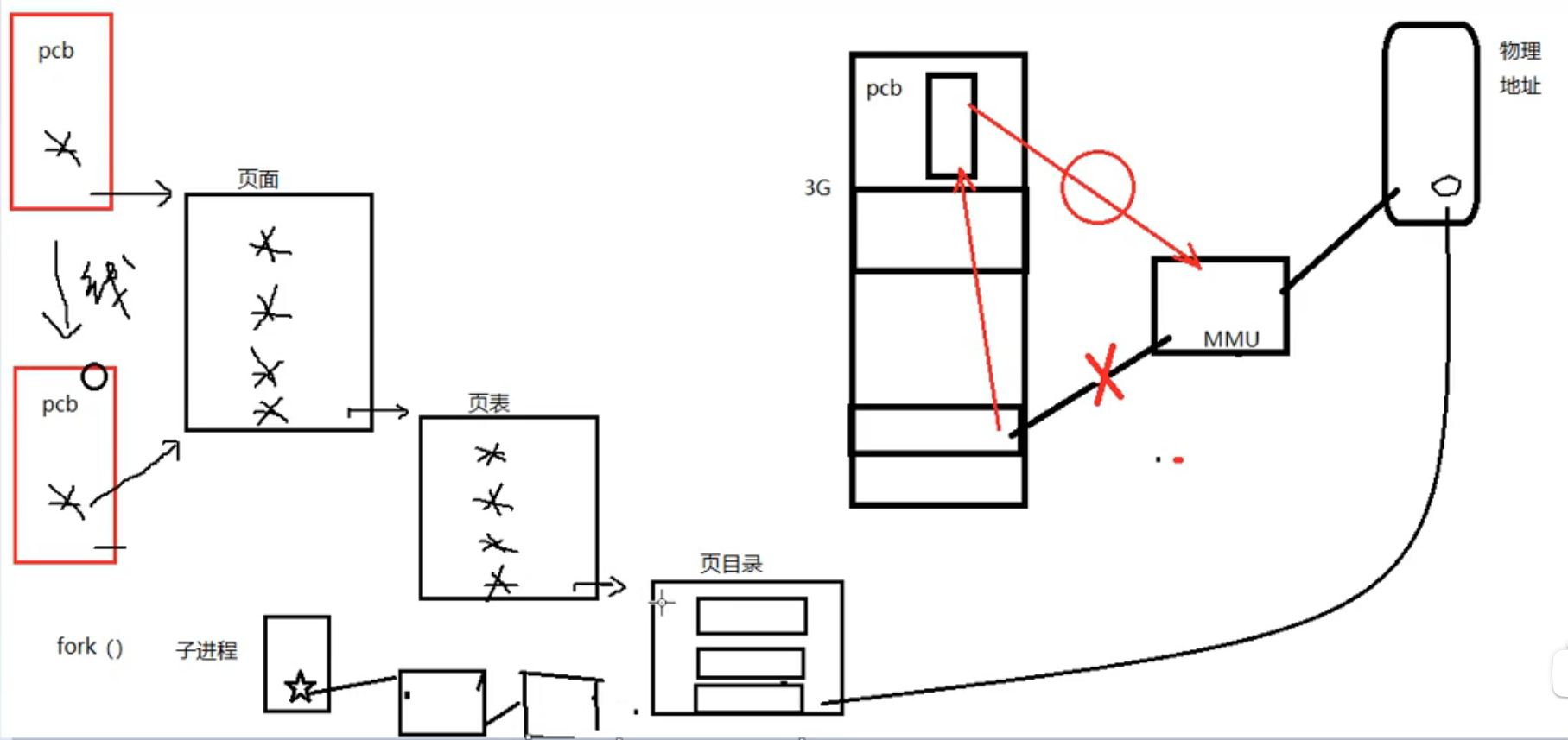
MMU
MMU(Memory Management Unit,内存管理单元)是计算机系统中的一种硬件设备,用于实现虚拟内存和内存保护等功能。MMU通常是CPU的一部分,它负责将虚拟地址转换为物理地址,并控制对内存的访问,以保证每个程序都可以独立地访问自己的内存空间,同时保护系统的安全性。
MMU的主要功能包括以下几个方面:
-
虚拟地址转换:MMU将程序发出的虚拟地址转换为物理地址,以便访问实际的内存空间。这个过程通常是通过页表或段表等数据结构实现的。
-
内存保护:MMU可以设置内存访问权限,以保证程序只能访问自己的内存空间,并防止程序越界访问其他程序的内存空间。这个过程通常是通过设置页面属性或段属性等方式实现的。
-
资源分配:MMU可以为每个程序分配独立的内存空间,以保证程序之间不会相互干扰。这个过程通常是通过虚拟内存机制实现的。
-
缓存管理:MMU可以控制CPU的缓存访问,以提高程序的执行效率和响应速度。
总之,MMU是计算机系统中非常重要的一个硬件设备,它实现了虚拟内存和内存保护等功能,保证了系统的稳定性和安全性。在操作系统中,MMU是实现虚拟内存、进程隔离和安全保护等功能的基础。
---
heap
在Linux中,Heap通常指的是进程的堆内存。 堆内存是进程在运行时从操作系统中分配的动态内存空间,它不像栈内存那样具有固定的大小或结构。 堆内存通常用于存储应用程序中需要动态分配或释放的数据,如变长字符串、数组和结构等。在Linux中,堆内存可以通过malloc()和free()等C库函数进行动态分配和释放,也可以通过系统调用brk()和mmap()来管理。 堆内存的大小和分配方式对应用程序的性能和稳定性有着很大的影响,因此在编写应用程序时需要特别注意内存管理。
---
主副线程共享全局变量

#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define NUM_THREADS 2
int global_variable = 0;
void *worker_thread(void *threadarg) {
printf("Worker thread started.\n");
while (1) {
printf("Worker thread updating global variable.\n");
global_variable++;
printf("Worker thread finished.\n");
break;
}
printf("Main thread waiting for worker thread to finish.\n");
pthread_exit(NULL);
}
int main() {
pthread_t threads[NUM_THREADS];
int exit_code = 0;
for (int i = 0; i < NUM_THREADS; i++) {
printf("Main thread started.\n");
printf("Creating thread %d ...\n", i + 1);
exit_code = pthread_create(&threads[i], NULL, worker_thread, (void *)(i + 1));
if (exit_code != 0) {
printf("Failed to create thread %d!\n", i + 1);
exit(-1);
}
printf("Thread %d created.\n", i + 1);
}
for (int i = 0; i < NUM_THREADS; i++) {
printf("Main thread waiting for thread %d to finish.\n", i + 1);
pthread_join(threads[i], NULL);
printf("Thread %d joined.\n", i + 1);
}
printf("Main thread finished.\n");
printf("Global variable = %d.\n", global_variable);
exit(0);
}
在这个代码示例中,主线程和副线程都访问了全局变量 global_variable,但它们各自拥有自己的堆栈和变量,因此它们不会相互干扰。
主线程和两个副线程一起运行,总共创建了三个线程。
- 主线程:创建了一个线程对象,并等待所有副线程完成。
- 副线程 1:创建了一个线程对象,并执行了
worker_thread函数。 - 副线程 2:创建了一个线程对象,并执行了
worker_thread函数。
运行结果(每次运行结果顺序都不一样):
Main thread started.
Creating thread 1 ...
Thread 1 created.
Main thread started.
Creating thread 2 ...
Worker thread started.
Worker thread updating global variable.
Worker thread finished.
Main thread waiting for worker thread to finish.
Thread 2 created.
Worker thread started.
Worker thread updating global variable.
Worker thread finished.
Main thread waiting for worker thread to finish.
Main thread waiting for thread 1 to finish.
Thread 1 joined.
Main thread waiting for thread 2 to finish.
Thread 2 joined.
Main thread finished.
Global variable = 2.
在每个副线程中,它将 global_variable 的值加 1,然后等待主线程等待它们完成。主线程等待所有副线程完成,然后打印出 global_variable 的当前值。由于主副线程共享全局变量,因此它们的更新将影响 global_variable 的值。
请注意,在这个代码示例中,主副线程共享全局变量是不安全的。在实际应用中,应该尽量避免在主副线程之间共享全局变量,而是使用其他同步机制来确保数据的一致性。
---
使用pthread_join将循环创建的多个子线程回收
(终止线程:pthread_cancel)
如果一个线程已经终止,调用该函数会立即返回。如果线程尚未终止,则调用线程会被阻塞,直到目标线程终止并回收其资源。
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define NUM_THREADS 5
void *thread_func(void *arg) {
int tid = *(int*)arg;
printf("Thread %d is running\n", tid);
sleep(1);
printf("Thread %d is done\n", tid);
pthread_exit(NULL);
}
int main() {
pthread_t threads[NUM_THREADS];
int thread_args[NUM_THREADS];
int i;
for (i = 0; i < NUM_THREADS; i++) {
thread_args[i] = i;
if (pthread_create(&threads[i], NULL, thread_func, &thread_args[i]) != 0) {
perror("pthread_create");
exit(EXIT_FAILURE);
}
}
// 等待线程终止并回收线程资源
for (i = 0; i < NUM_THREADS; i++) {
if (pthread_join(threads[i], NULL) != 0) {
perror("pthread_join");
exit(EXIT_FAILURE);
}
printf("Thread %d is joined\n", i);
}
return 0;
}
在上面的示例中,我们创建了 NUM_THREADS 个线程,每个线程都执行 thread_func 函数。在主线程中,我们使用 pthread_join 函数等待每个线程终止,并回收它的资源。在等待一个线程时,主线程会被阻塞,直到目标线程终止并回收其资源。在每个线程终止并回收其资源后,主线程会打印一条消息表示该线程已经被回收。
请注意,为了避免线程函数访问不再存在的参数,我们将参数传递给线程的地址作为参数。这样,线程可以通过访问该地址来获取其参数值。
- pthread_t threads[NUM_THREADS];
- 如果
NUM_THREADS是 5,那么threads数组将包含 5 个pthread_t类型的变量,分别为threads[0]、threads[1]、threads[2]、threads[3]和threads[4]。在调用pthread_create创建线程时,我们将每个线程的线程 ID 存储在相应的数组元素中,以便稍后可以使用它们来回收线程资源(pthread_join函数)。
同一个主线程创建的多个副线程执行的内容是一样的吗
同一个主线程创建的多个子线程执行的内容可能会相同,也可能会不同,这取决于编程时的设计和实现。但是,无论子线程执行的内容是否相同,都需要注意线程之间的同步和竞态条件,以确保多线程程序的正确性和安全性。
---
线程和进程函数的相似之处

---
如何避免僵尸线程
- pthread_join
- pthread_detach
- pthread_create指定分离属性
具体的
1.使用pthread_join()函数:
-
调用该函数等待线程执行完毕,并释放线程资源。如果线程已经执行完毕,调用pthread_join()可以立即返回,并回收线程资源。如果不调用pthread_join(),线程资源将一直得不到释放,从而导致僵尸线程的产生。
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);
thread:要等待的线程的标识符。
retval:用于存储线程返回值的指针,如果不需要,则传递NULL。2.使用pthread_detach()函数:
-
调用pthread_detach()函数后,线程会变成分离状态,线程在执行完毕后会自动释放资源,不需要其他线程调用pthread_join()函数。需要注意的是,一旦线程被分离,就无法调用pthread_join()函数等待它执行完毕了。
pthread_detach(pthread_t thread);
thread:要分离的线程的标识符。3.使用pthread_create()函数指定分离属性:
- 在创建线程时,可以使用pthread_attr_t结构体和pthread_attr_init()函数初始化线程属性,再使用pthread_attr_setdetachstate()函数设置分离属性。调用pthread_create()函数时,将线程属性作为参数传递给该函数,从而创建分离线程。
- 创建的线程在执行完毕后,会自动释放资源,不需要其他线程调用pthread_join()函数。
#include <pthread.h>
int pthread_attr_init(pthread_attr_t *attr);
int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine)(void *), void *arg);
attr:线程属性结构体的指针。
detachstate:分离属性,可以设置为PTHREAD_CREATE_DETACHED(分离状态)或PTHREAD_CREATE_JOINABLE(非分离状态)。- 调用pthread_create()函数创建分离线程的代码示例如下:
#include <pthread.h>
#include <stdio.h>
void *thread_func(void *arg)
{
printf("Thread running\n");
return NULL;
}
int main()
{
pthread_t thread;
int ret;
pthread_attr_t attr;
ret = pthread_attr_init(&attr);
if (ret != 0) {
printf("Failed to initialize thread attribute\n");
return 1;
}
ret = pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
if (ret != 0) {
printf("Failed to set thread attribute\n");
return 1;
}
ret = pthread_create(&thread, &attr, thread_func, NULL);
if (ret != 0) {
printf("Failed to create thread\n");
return 1;
}
printf("Thread created\n");
pthread_attr_destroy(&attr);
return 0;
}
---
解引用*
在C语言中,解引用指针是获取指针指向的变量的值的一种方式。如果我们要使用指针所指向的变量的值,就需要使用解引用符号“*”来获取这个变量的值。
指针本身只是一个存储内存地址的变量,通过它只能访问到内存地址,而不能直接访问内存中存储的实际数据。因此,我们必须通过指针解引用来获取指针所指向的变量的值。
例如,如果我们定义了一个指向整型变量的指针p,我们可以通过解引用符号“*”来获取它所指向的变量的值:
int num = 10;
int *p = #
printf("%d", *p); // 输出10
在上面的代码中,我们使用了解引用符号“*”来获取指针p所指向的变量num的值,即输出了num的值10。
取地址&
在C语言中,符号&表示取地址运算符,可以用来获取一个变量的地址。
例如,如果我们声明了一个整型变量num,我们可以使用&符号来获取它的地址:
int num = 10;
int *p = # // 获取num变量的地址并赋值给指针变量p
在上面的代码中,我们使用&符号来获取num变量的地址,并将它赋值给一个指向整型的指针变量p。这样,指针变量p就指向了num变量所在的内存地址,我们可以通过指针变量p来访问num变量。
除了获取变量的地址之外,&符号还可以用来定义指向函数的指针。例如,我们可以定义一个指向函数的指针变量p,然后使用&符号来获取函数的地址:
int add(int a, int b) {
return a + b;
}
int (*p)(int, int) = &add; // 获取add函数的地址并赋值给指针变量p
在上面的代码中,我们定义了一个名为add的函数,然后定义了一个指向函数的指针变量p,并使用&符号获取add函数的地址,并将它赋值给指针变量p。
---
函数返回值为定义在函数里的本地变量⚠
void *tfn(void *arg)
{
struct thrd tval;
tval.var=100;
strcpy(tval.str,"hello thread");
return (void *)&tval;
}在这个函数中,我们定义了一个结构体变量 tval,并初始化了它的成员 var 和 str。然后,我们使用 (void *)&tval 将结构体变量 tval 的地址强制转换成了 void 类型的指针,作为函数的返回值。
但是,这个函数存在严重的问题,即返回了一个指向栈上局部变量的指针。这是不安全的,因为在函数返回后,栈上的数据可能已经被销毁或被其他函数重写。如果在函数外部继续使用返回的指针,将会导致未定义的行为。
为了解决这个问题,我们可以将结构体变量 tval 改为使用动态内存分配,例如:
void *tfn(void *arg)
{
struct thrd *tval = malloc(sizeof(struct thrd));
tval->var = 100;
strcpy(tval->str, "hello thread");
return (void *)tval;
}
在上面的代码中,我们使用 malloc() 函数动态分配了一个 struct thrd 类型的内存块,并将指针 tval 指向这个内存块。然后,我们初始化了结构体成员 var 和 str。最后,我们返回了指针 tval,这是安全的,因为它指向了动态分配的内存块,不会随着函数的返回而被销毁。
请注意,如果在使用完动态分配的内存块后没有及时释放,将会导致内存泄漏。因此,我们应该在使用完后使用 free() 函数释放内存块,例如:
struct thrd *t = tfn(NULL);
// 使用返回的指针 t
free(t); // 释放动态分配的内存块---
return (11) 和 exit (11) 有什么区别
return和exit都可以用来退出程序并返回一个状态码,但它们的用法和含义略有不同。
return通常用于函数或方法中,用来表示函数执行结束并返回一个值,同时将控制权返回给调用该函数的代码。在Python等编程语言中,return后面可以跟一个表达式,表示返回的值。如果没有指定返回值,将默认返回None。在这种情况下,return (11)将返回值11并将控制权返回给调用该函数的代码。
exit用于退出整个程序并返回一个状态码,通常用于命令行程序或脚本中。在C和C++等编程语言中,exit函数需要传入一个整数作为状态码。在Unix和Linux系统中,exit也可以在命令行中直接使用,后面的参数表示状态码。例如,exit 11将会以状态码11退出程序。与return不同,exit将直接退出整个程序,不会返回到调用代码中。
- 终止线程就算了把,还是用return
因此,return (11)和exit(11)的区别在于前者是用于函数中返回值并返回控制权给调用代码,后者是直接退出整个程序并返回状态码11。
---
守护进程的创建
(不懂有没有用,先写了再说)

---
互斥锁🔓
互斥锁是一种同步机制,用于在多线程或多进程环境中控制对共享资源的访问。在同一时刻只有一个线程或进程能够持有互斥锁,其他线程或进程必须等待该锁被释放后才能继续执行。
当一个线程或进程获得了互斥锁时,它就可以安全地访问共享资源,因为此时其他线程或进程无法访问这些资源。当该线程或进程完成了对共享资源的访问后,它就会释放互斥锁,使其他线程或进程可以继续访问这些资源。
互斥锁通常用于保护对共享资源的并发访问,例如对文件、数据库、网络连接等的访问。在多线程编程中,互斥锁也是解决并发访问问题的重要工具之一。

#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
// 互斥锁
pthread_mutex_t mutex; //该锁🔓变量可以看成为int类型 ---(本质是结构体)
// 共享资源
int shared_resource = 0;
// 线程函数
void *worker(void *arg)
{
// 获取互斥锁
pthread_mutex_lock(&mutex); //加锁,,看成 锁🔓--(加一次锁自减一次), 所以1-1=0
// 修改共享资源
shared_resource++;
// 释放互斥锁
pthread_mutex_unlock(&mutex); //解锁 ,,看成 锁🔓++ , 所以0+1=1
return NULL;
}
int main()
{
// 初始化互斥锁
pthread_mutex_init(&mutex, NULL); // 看成int 锁🔓 = 1 (调用成功,锁🔓的初值为1)
// 创建多个线程来访问共享资源
pthread_t threads[10];
for (int i = 0; i < 10; i++) {
pthread_create(&threads[i], NULL, worker, NULL);
}
// 等待所有线程执行完毕
for (int i = 0; i < 10; i++) {
pthread_join(threads[i], NULL);
}
// 输出共享资源的值
printf("共享资源的值为: %d\n", shared_resource);
// 销毁互斥锁
pthread_mutex_destroy(&mutex);
return 0;
}
- 在这个示例代码中,我们首先定义了一个互斥锁对象
mutex和一个共享资源shared_resource,然后定义了一个线程函数worker,该函数在获取互斥锁后对共享资源进行修改,最后释放互斥锁。 - 接着,我们创建了10个线程来访问共享资源,每个线程都会执行
worker函数。最后,我们等待所有线程执行完毕,然后输出共享资源的值。 - 需要注意的是,在使用互斥锁时,必须确保在任何时刻只有一个线程能够持有该锁。否则,可能会出现死锁等问题。因此,在获取互斥锁后,应尽快完成对共享资源的操作,并尽快释放锁。同时,还需要注意互斥锁的初始化和销毁操作,以避免内存泄漏等问题。
下面是加入pthread_create指定分离属性的代码
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
// 互斥锁
pthread_mutex_t mutex;
// 共享资源
int shared_resource = 0;
// 线程函数
void *worker(void *arg)
{
// 获取互斥锁
pthread_mutex_lock(&mutex);
// 修改共享资源
shared_resource++;
// 释放互斥锁
pthread_mutex_unlock(&mutex);
// 当线程执行完毕后,自动释放资源
pthread_detach(pthread_self());
return NULL;
}
int main()
{
// 初始化互斥锁
pthread_mutex_init(&mutex, NULL);
// 创建多个线程来访问共享资源
pthread_t threads[10];
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED); // 设置线程分离属性
for (int i = 0; i < 10; i++) {
pthread_create(&threads[i], &attr, worker, NULL);
}
pthread_attr_destroy(&attr);
// 等待所有线程执行完毕
// 不需要使用pthread_join等待线程结束,因为线程已经被设置为分离属性
// 线程结束后会自动释放资源
// 输出共享资源的值
printf("共享资源的值为: %d\n", shared_resource);
// 销毁互斥锁
pthread_mutex_destroy(&mutex);
return 0;
}---
读写锁和普通的锁有什么区别
读写锁(Read-Write Lock)和普通的锁(Mutex Lock)主要的区别在于它们对共享资源的访问方式不同。
- 在普通的锁中,一旦一个线程获得了锁,其他线程就必须等待该线程释放锁,才能继续访问共享资源。这种锁适用于对共享资源的互斥访问,即只允许一个线程同时访问共享资源,其他线程需要等待。
- 而在读写锁中,允许多个线程同时读取共享资源,但只允许一个线程写入共享资源。当一个线程获得了读锁,其他线程也可以获得读锁,但是不能获得写锁;当一个线程获得了写锁,其他线程既不能获得读锁,也不能获得写锁。这种锁适用于对共享资源的读写操作,即多个线程可以同时读取共享资源,但只允许一个线程写入共享资源。
读写锁的优点在于,当多个线程只需要读取共享资源时,可以同时获得读锁,从而提高了并发性能;当一个线程需要写入共享资源时,可以独占写锁,从而保证了数据的一致性。而普通的锁则会限制所有的读写操作,效率较低。
需要注意的是,读写锁和普通的锁一样,也需要避免死锁和竞态条件等问题。同时,读写锁的使用也需要根据实际情况进行选择,如果对共享资源的写操作很少,但对共享资源的读操作非常频繁,那么使用读写锁可以提高并发性能;如果对共享资源的读写操作差不多,那么使用普通的锁可能更为合适。
读写锁的特性

读写锁主要函数

---
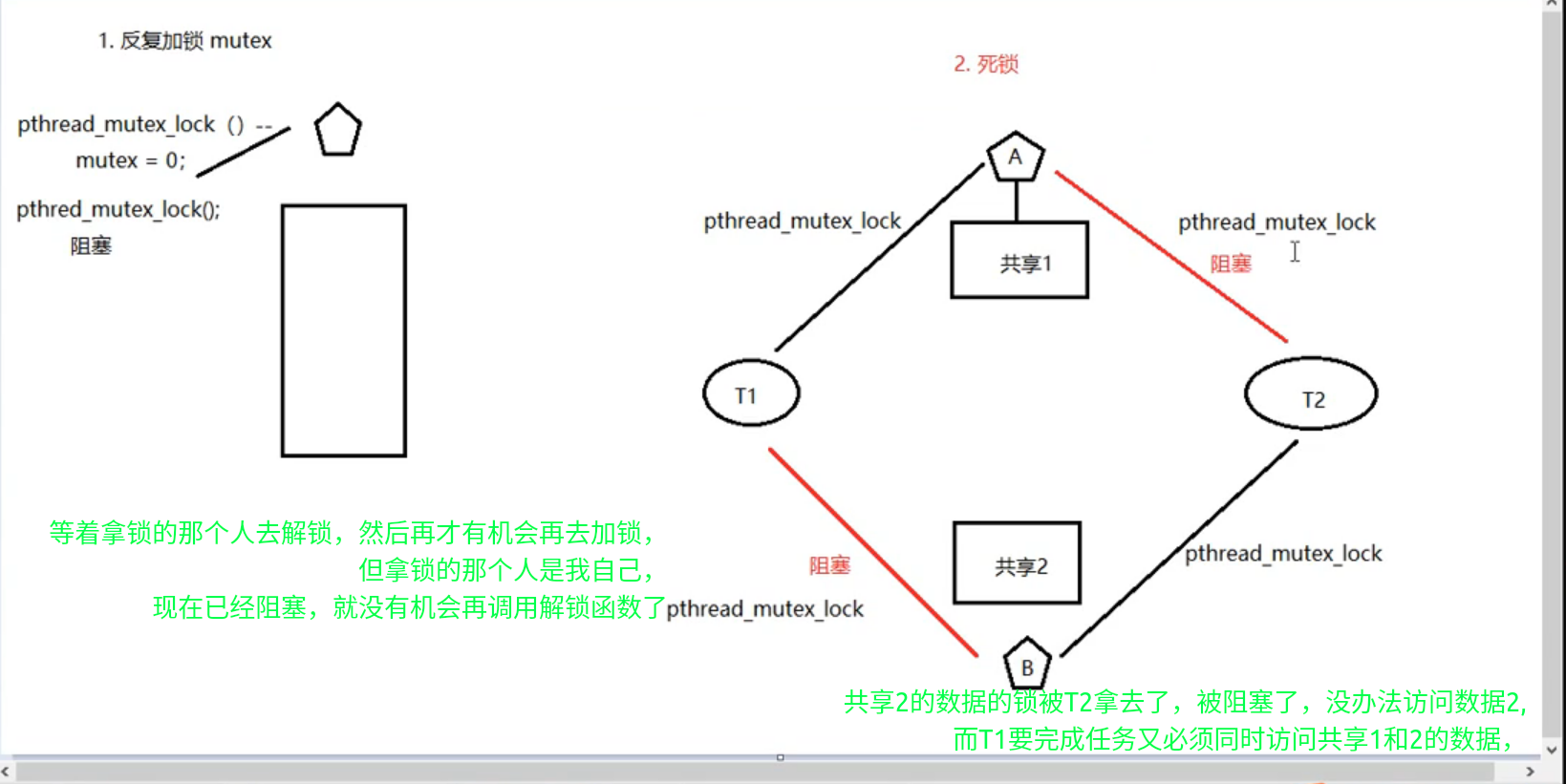
死锁
#include <stdio.h>
#include <pthread.h>
pthread_mutex_t var1_mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t var2_mutex = PTHREAD_MUTEX_INITIALIZER;
int var1 = 0;
int var2 = 0;
void* thread1(void* arg) {
pthread_mutex_lock(&var1_mutex);
printf("线程1获得了var1_mutex锁。\n");
// 模拟一些工作
sleep(1);
// 尝试获取 var2_mutex 锁
pthread_mutex_lock(&var2_mutex);
printf("线程1获得了var2_mutex锁。\n");
// 对 var1 和 var2 进行一些操作
var1++;
var2++;
// 释放锁
pthread_mutex_unlock(&var2_mutex);
pthread_mutex_unlock(&var1_mutex);
return NULL;
}
void* thread2(void* arg) {
pthread_mutex_lock(&var2_mutex);
printf("线程2获得了var2_mutex锁。\n");
// 模拟一些工作
sleep(1);
// 尝试获取 var1_mutex 锁
pthread_mutex_lock(&var1_mutex);
printf("线程2获得了var1_mutex锁。\n");
// 对 var1 和 var2 进行一些操作
var1++;
var2++;
// 释放锁
pthread_mutex_unlock(&var1_mutex);
pthread_mutex_unlock(&var2_mutex);
return NULL;
}
int main() {
pthread_t t1, t2;
// 创建两个线程
pthread_create(&t1, NULL, thread1, NULL);
pthread_create(&t2, NULL, thread2, NULL);
// 等待线程结束
pthread_join(t1, NULL);
pthread_join(t2, NULL);
return 0;
}
- 两个线程
t1和t2分别尝试获取var1_mutex和var2_mutex。- 如果
t1先获取了var1_mutex,而t2先获取了var2_mutex,- 那么当
t1尝试获取var2_mutex的时候,它会被阻塞,因为t2已经持有了var2_mutex的锁。同样地,当t2尝试获取var1_mutex的时候,它也会被阻塞,因为t1已经持有了var1_mutex的锁。这种情况下,两个线程会进入死锁状态,无法继续执行下去。

运行结果:
(后面的东西就再也没有加载出来...)

为什么上面代码不用创建锁和销毁锁?
使用了静态初始化的方式初始化了 pthread_mutex_t 类型的锁,并没有使用 pthread_mutex_init() 函数显式地初始化锁。这是因为,如果我们知道锁的初始值,并且在整个程序的生命周期中只需要使用这个锁,那么静态初始化是一种更简单、更方便的方法。
另外,在本例中,我们也没有使用 pthread_mutex_destroy() 函数来销毁锁。这是因为,在程序退出之前,所有的线程都已经执行完毕,并且已经释放了所有的锁。因此,我们不需要显式地销毁这些锁。
需要注意的是,在一些情况下,需要使用 pthread_mutex_init() 函数显式地初始化锁,例如当需要在动态分配的内存中使用锁时。同样,如果你在程序中使用了动态分配内存的锁,那么在释放内存之前,需要使用 pthread_mutex_destroy() 函数将锁销毁,以免出现内存泄漏等问题。
- 下面是两种不同的初始化(静态的不需要destroy)

---
条件变量
本身不是锁! 但是通常结合锁来使用 mutex
pthread_cond_t cond; //创建条件变量
两种方式初始化条件变量:
1. pthread_cond_init(&cond, NULL); 动态初始化
2. pthread_cond_t cond = PTHREAD_COND_INITIALIZER ;静态初始化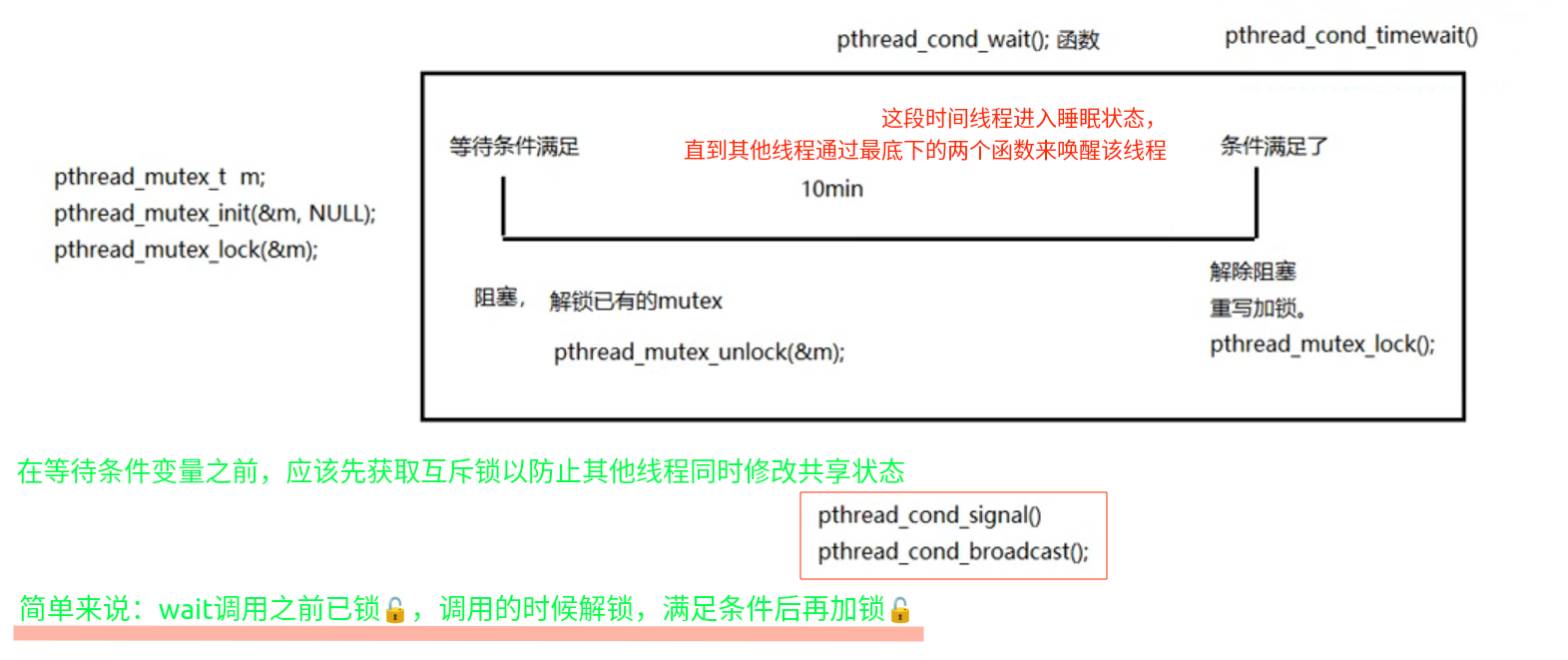
---
生产者消费者模型

- 消费者被阻塞时,生产者在生产完数据后可以成功地加锁🔓
- 因为生产者本身没有像消费者wait函数自带有解锁和加锁的功能,所以在写数据到公共区域后还要 解开 写前加的锁
加单生产者单消费者
一种基本方法是使用一个循环缓冲区(Circular Buffer)和两个指针,一个指向缓冲区的头部,另一个指向缓冲区的尾部。
具体实现步骤如下:
-
定义一个循环缓冲区,包含一个固定大小的数组和两个指针,一个指向缓冲区的头部,另一个指向缓冲区的尾部。同时定义一个计数器来记录缓冲区中的元素数量。
-
定义生产者线程函数,该函数负责向缓冲区中添加数据。当缓冲区已满时,生产者线程将被阻塞,直到有足够的空间可用。当生产者线程添加数据时,它将数据添加到缓冲区的尾部指针所指向的位置,并将尾部指针向前移动一个位置。
-
定义消费者线程函数,该函数负责从缓冲区中移除数据。当缓冲区为空时,消费者线程将被阻塞,直到有足够的数据可用。当消费者线程移除数据时,它将数据从缓冲区的头部指针所指向的位置移除,并将头部指针向前移动一个位置。
-
在生产者线程和消费者线程之间使用信号量来进行同步。当生产者线程添加数据时,它会递增一个信号量,表示缓冲区中已有的元素数量增加了一个。当消费者线程移除数据时,它会递减一个信号量,表示缓冲区中已有的元素数量减少了一个。如果缓冲区已满,则生产者线程将被阻塞,直到有足够的空间可用。如果缓冲区为空,则消费者线程将被阻塞,直到有足够的数据可用。
-
注意在使用指针时需要注意指针越界的问题。可以使用取模运算来保证指针始终指向循环缓冲区中的合法位置。
---
线程池

---