 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
在时序数据库这样一个小众的圈子里面每年有意思的东西并不多,每一篇顶会paper都值得细细品读。其次靠自己想很多问题很难解决,还是需要向业界优秀的团队虚心学习,才能清除和增加自己产品的核心竞争力。
问题定义
如下图是《Apache IoTDB: A Time Series Database for IoT Applications》中提出的一个典型场景:
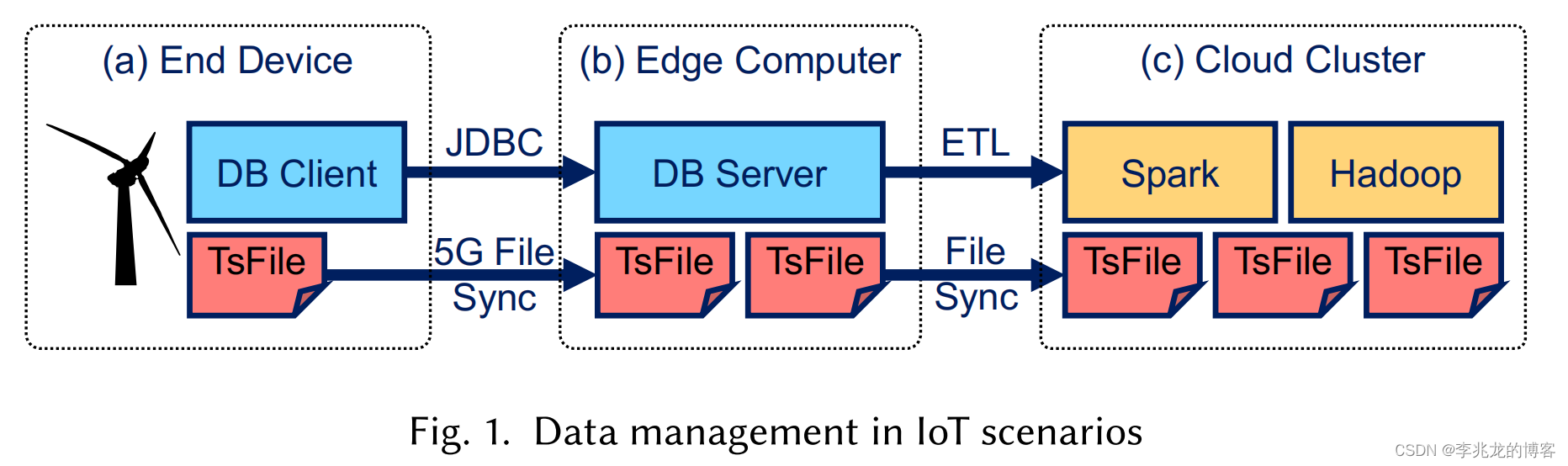
- 边缘设备(时序数据的产生点)
- 边缘服务器中需要一个用于写入,存储和查询的数据库
- 云端的计算集群,用于OLAP分析
文章开篇指出了IotDB聚焦的问题,即:
- 不断变化的模式,即对于SchemaLess的支持(传感器经常被替换,移除,新增)
- 周期性的数据采集
- 强相关的series(利用2,3可以增加压缩的可能性)
- 多样化延迟数据的写入
- 高并发的数据写入
其次在优雅的解决这些问题能保证查询上做到:
- 一天之内10万数据点的selection在100ms
- 三年之内1000万数据点的aggregation在100ms
新技术
数据模型
InfluxDB中measurement+tags+fields的数据模型基本已经成为现实标准,但是IotDB认为这样的模型对于设备和传感器进行管理难以优化物理存储,遂使用树形管理所有的时间序列。
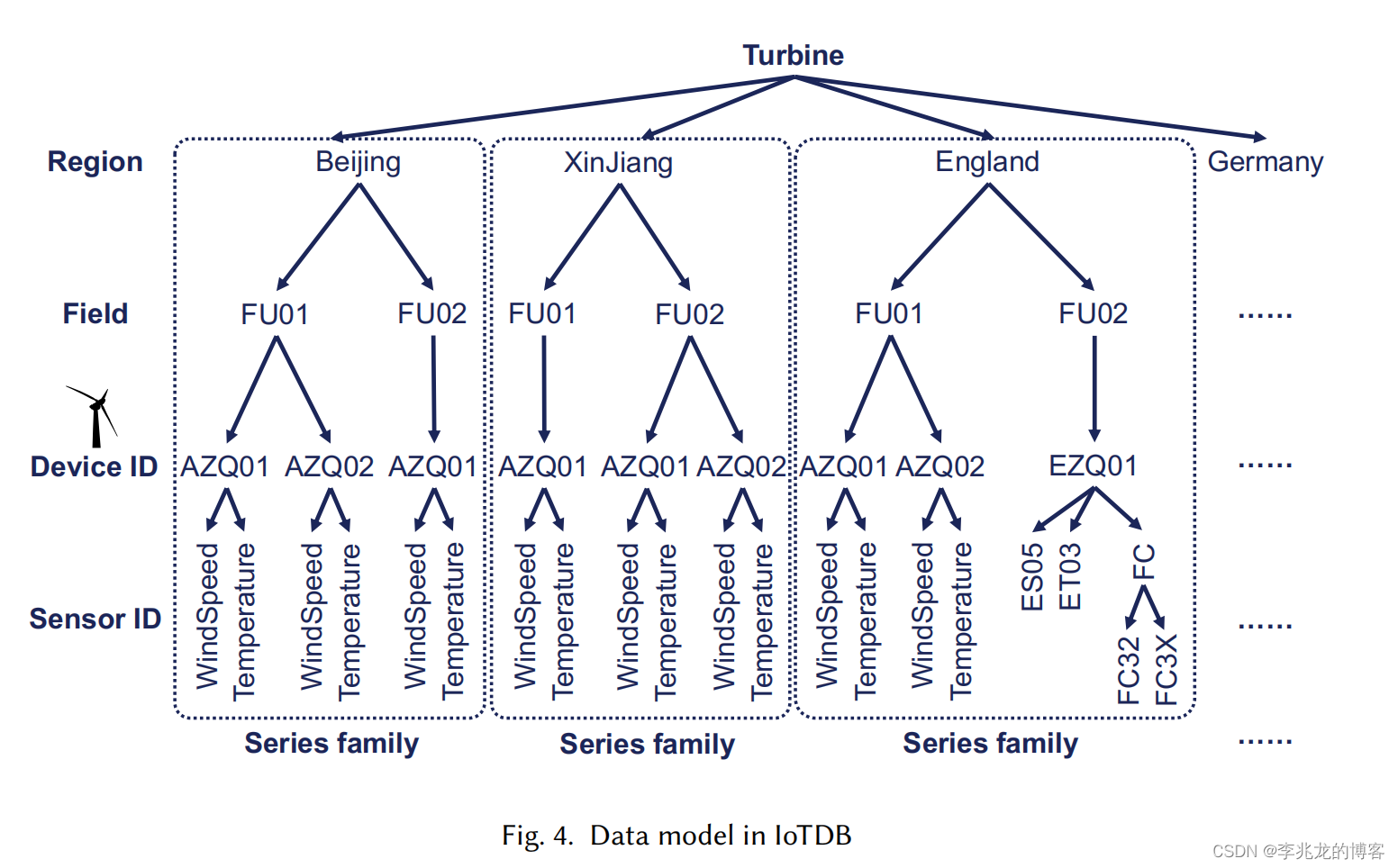
iotDB使用Sensor+Device管理所有的时间序列
物理模式如下:
- Time Series:每一条根节点到叶子结点是一个时间序列
- Series Family:一个设备的时间序列存储在一个tsfile中,一个tsfile中可以存储多个设备的时间序列,每一个 Series Family有一个独立的存储引擎,所有的tsfile存储在一个目录中
这样的优势我理解是可以控制哪些设备处于一个Series Family中,进而利用周期性和强相关的数据执行更有效的数据压缩。
schemaless
[12]中描述了iotdb的方案,后续有时间看下,influxdb的方案就很简单,不知道有什么区别。
Tsfile设计
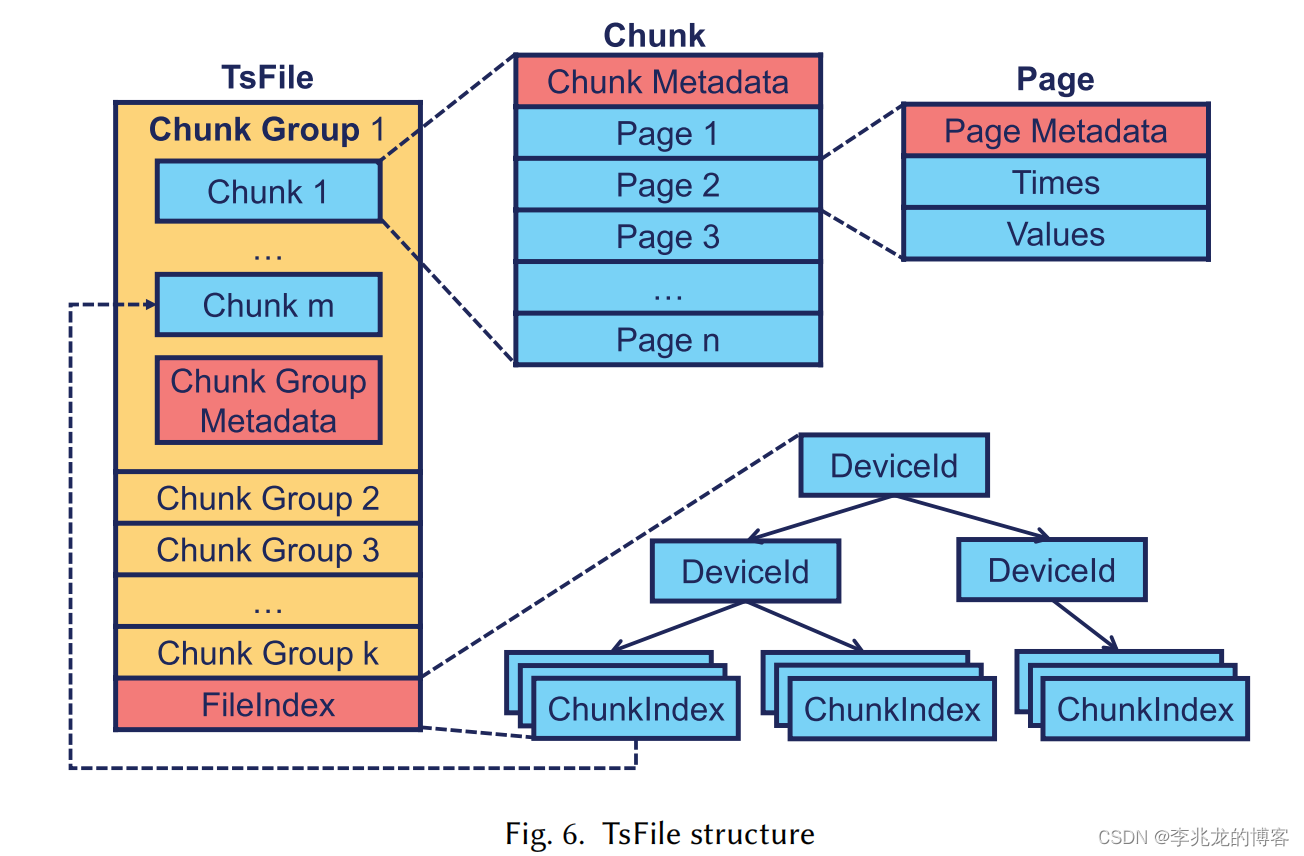
- page:基本存储单位,一个page属于一个时间序列,其中存储两列,即时间和filed
- chunk:由metadata+多个page组成,所有page都属于一个时间序列
- chunk group:由metadata+多个chunk组成,所有的chunk属于一个或多个时间序列。多个chunk放在一起的原因文章中提到是一个设备所属的多个传感器一般被同时访问,
- index:很巧妙的组织形式,可以很快的索引某个时间序列的所有chunk信息,并且携带时间序列的统计信息,比如count,begin,end等,用于查询优化
本质上和TSM存储格式差不多,但是因为TSM是KV模型,依赖于TSI获取完整的seriesID,在这之中还需要在series file中获取时机的serieskey,这就很慢了。这也是现代时序数据库均使用Parquet,tsfile这样存储模型的原因,不仅导入导出方便,摆脱了倒排索引的依赖。
双MemTable
本质要解决的问题就是乱序数据会使得tsfile的时间区间存在重复,但是这只适用于乱序数据较少的情况,此时会有益于查询和写放大;否则会退化为普通版本,还增加了维护的开销。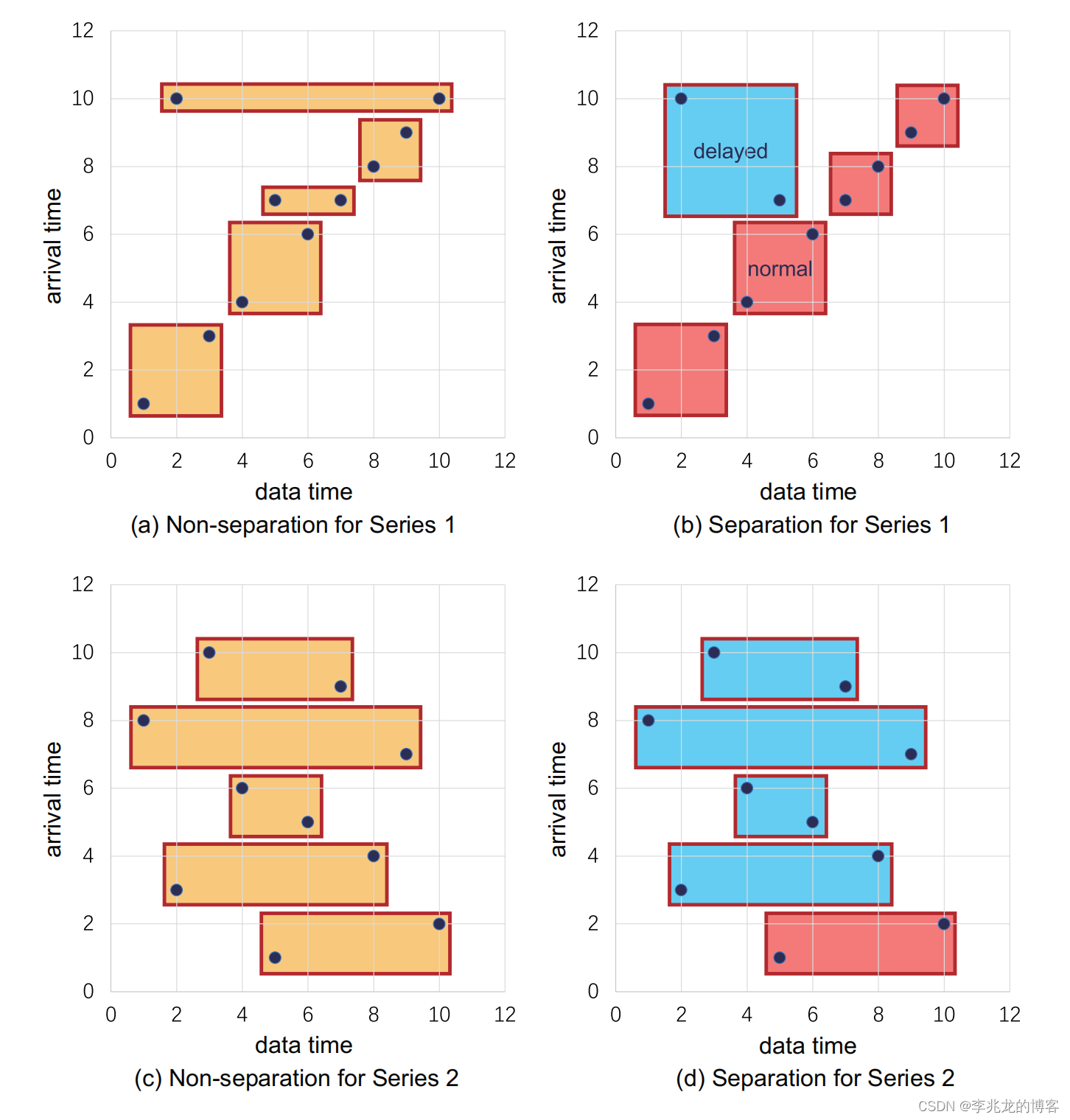 在iotdb遇到的场景下,长延时只有0.0375%;但是在我们当前的场景中,乱序数据是常态;其次influxdb内数据的写入其实是在TSM,每个memtable中包含的是kv数据,就算乱序到达也只不过是查询时需要在level0中的多扫几个块罢了;
在iotdb遇到的场景下,长延时只有0.0375%;但是在我们当前的场景中,乱序数据是常态;其次influxdb内数据的写入其实是在TSM,每个memtable中包含的是kv数据,就算乱序到达也只不过是查询时需要在level0中的多扫几个块罢了;
[10]中提到了可以通过数据的到达情况自动判断是否分裂,这对于iodDB来说确实是一种很好的思路。
高级可扩展查询
这几乎是领域龙头做的最好的一个方向了,因为这里非常偏学术,无论是DolphinDB还是IotDB对于各类特殊场景的算子支持都强于公有云厂商。
- 模式匹配算子PATTERN[2]
- 异常检测函数[3]
- 数据估算函数,用于填补空缺值[4][5]
- 用户自定义函数(UDF),用于特定领域个性化计算的需求;在查询引擎中算子的处理都是迭代器化的,这个其实我们也可以加,但是现阶段来看需求并不强烈,没必要透漏给用户这个接口。
其他
- 高效的数据传输,可以在边缘设备,边缘服务器和云端之间导入,不需要昂贵的ETL。这其实不是IotDB独有的优势,本质上只要存储层是独立可解释的文件就有这个优势,单很可惜inlfuxDB1.x不是,这也是InfluxData推动InfluxDBiox的关键动机之一。
- 高效的压缩能力,这其实是核心要解决的问题中周期性以及强相关数据的具体优化方式,在[6]中阐述了各种数据类型压缩的方式,iotdb也研究出了一些巧妙的压缩方式[7][8][9],也证明了一般时序数据库中默认(比如influxdb)的Timestamp: Delta → Scaling → (RLE/Simple8b); Float:XOR;Integer:ZigZag → (Simple8b/RLE/Uncompress);Boolean:Bit-packing;并不是最优的解决方案。但是这并不是IotDB独有的方案,理论上只需要一个实习生任意一个系统都可以具备这样的优势。其次存储目前从经验来看并不是运营中最大的问题,工程不是学术,在压缩率已经达到要求的情况下没有必要过度优化。
IotDB劣势
- 分布式系统设计历史气息浓厚,这带来的直接差异我能想到的有:元数据管理节点存在单点,集群规模TB级别,不适用于公有云,只适合于私有云,这也导致了价钱不会太便宜
- 聚焦于Iot场景,可以说把无损压缩做到了极致,但是现在SSD并不贵,以我们的运营经验来看存储不是瓶颈。优势带来的劣势时时间线较多的场景无法处理,因为tsfile中的树形索引基本失效,每一个series都是一个根节点。
- java编写,我猜测和influxdb1.x一样存在full gc的问题,基本无法解决;
- TSQL能力弱于influxql和SQL
influxDB 1.x 劣势
- 不支持SQL
- 基数无法无限扩展(国内目前TDengine以外其他大厂的时序数据库仔细看都存在时间线限制)
- 存算不分离(开源没有集群版),导致隔离很难做[13],基本上是无解的(也有办法,不过实施比较复杂),所以只能在运营角度规避这个问题
- go实现,且实现的不严谨,导致内存问题很严重;显然Rust/cpp才是最好的引擎语言
- 应该允许在没有本地存储的情况下运行,但是内部实现大量使用mmap(建议大家都看看[14])
- 索引数据分离,导致导入导出极为困难
- Highly indexed,导致写操作较为繁琐且昂贵,可能需要更新两个索引和一个数据
- 查询多时间线时极为昂贵,tsi中需要消耗大量的时间,因为需要对所有的查询条件的结果集做并集,并在seriesfile中查询series key,[15]也提到拆分索引是没有用的,查询的时间线客观存在,拆分索引还会造成内存问题,因为维护索引信息也需要不少内存
- 时间线较多时索引信息大于数据,但是时序的场景导致很多索引自始至终是无法被使用的
结束语
跟着老大InfluxDB IOX走基本上没有错,其他的路都是徒劳。

参考:
- Announcing InfluxDB IOx - The Future Core of InfluxDB Built with Rust and Arrow
- Kv-match: A subsequence matching approach supporting normalization and time warping icde2019
- Time series data cleaning: From anomaly detection to anomaly repairing vldb2017
- Sequential data cleaning: A statistical approach sigmod2016
- SCREEN: stream data cleaning under speed constraints sigmod2015
- Time series data encoding for efficient storage: A comparative analysis in apache iotdb vldb2022
- On aligning tuples for regression KDD22
- Grouping time series for efficient columnar storage sigmod2023
- Frequency domain data encoding in apache iotdb vldb2022
- Separation or not: On handing out-of-order time-series data in leveled lsm-tree icde2022
- Non-blocking raft for high throughput iot data icde2023
- Swapping repair for misplaced attribute values icde2020
- 从一到无穷大 #7 Database-as-a-Service租户隔离挑战与解决措施
- Are You Sure You Want to Use MMAP in Your Database Management System?
- The Design of InfluxDB IOx: In-Memory Columnar Database Written in Rust with Apache Arrow (Paul Dix)