 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
引言
TSM-BenchMark其实是这次VLDB2023我最期待的几篇文章之一,本质的原因是因为通用的时序数据库BenchMark是一个看似简单,实则极具挑战的问题,自我们的项目立项之初我们就一直不得不做这方面的工作,与我个人来看有这么几个难点:
数据真实性:不同的时序数据模型在读写上可能有非常大的差异,但是使用什么数据作为benchmark数据集?线上真实采集的数据规模有限,现有工具生成的数据无法模拟线上数据场景数据隐私性:内部的很多优化基于内部数据集,在和友商产品做对比的时候我们自然使用线上采集的真实数据集作为对比,但是如何让外界可以复现查询模式固定且很难扩展:目前我们使用的InfluxDB-comparison就存在这个问题,查询的类型非常单一,而且扩展更多的查询模型就需要修改代码,且怎么样的查询模式才能准确找到系统的薄弱点?负载单一:我们内部的使用的InfluxDB-comparison就是一个经典的例子,InfluxDB-comparison的流程分为四步bulk_data_gen,bulk_load_influx,bulk_query_gen,query_benchmarker_influxdb,分别是数据生成,数据载入,查询生产,执行查询;这个过程只能测试出Offline的负载,无法测试出写入持续进行时的查询性能(Online)。
我花了半天时间体验了一下TSM-BenchMark,并把TSM-BenchMark Online场景移植到我们的产品上来,在这个过程中发现了TSM-BenchMark的几个缺点:
- 原始数据集单一,模型为
sensor,id_station=st0 s0=0.392098......s99=0.392098 timestamp,包含一个tag和100个field,想要其他的数据需要自己提供新数据集合,重新训练模型,并执行一整套数据生成流程 DCGAN的输入看起来是field级别的,这个其实很麻烦,因为很多时间线不是连续上报的,换句话说稀疏场景想生成还得改代码(拆field,补零),当然一般连续上报要生成数据也需要自己加很多逻辑,无法做到输入一个原始数据集合,输出一个原始数据集合。Online场景暂时没有自动化,且基本处于不可用阶段,而且因为是论文带的项目,基本不存在发展新特性的可能(我一下午基本一半时间就是在改inlfuxdb的Online流程了)- 工程化水平弱,代码中充斥着绝对路径和无用的注释,且基本无法扩展。但是也有值得学习的地方,比如benchmark结束以后会自动生成性能对比图,这个可以考虑引入我们的项目
其次正因为数据模型的原因(单tag多fields),文章最后对于七种数据库的benchmark比较结论也不能直接用在广义的时序场景中,但是不妨碍这仍旧是一篇非常好的文章,至少可以给我这些启发:
- 基于
GAN(Generative Adversarial Network)生成时序数据是一个可行的方案,可以解决数据隐私性问题,从而推进各大云厂商进行BecnchMark的数据共享 - 大批量写入的
Online场景下Time Struct Merge Tree(inlfuxdb 1.7)查询性能/稳定性强于ClickHouse,Druid,eXtremeDB,MonetDB,QuestDB,TimescaleDB一众老牌数据库
真实数据生成方法
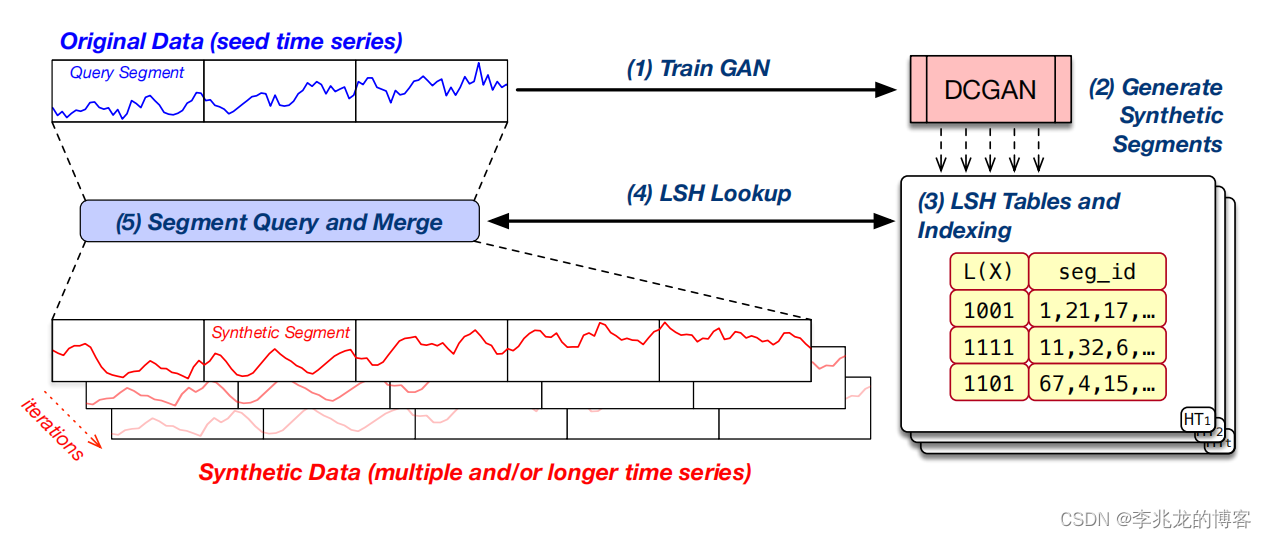
- 将原始数据划分为段,训练
DCGAN模型 - 训练完成后生成具有真实数据特征的时序数据段
- 基于生成的数据段建立LSH哈希表[3],这个流程中除了希望保持原始数据的特征外还希望有一定的变化,可以通过创建多个哈希表来完成
- 基于原始数据集合,查找与原始数据相似的段,这个过程利用的LSH的特性,即哈希冲突被最大化,位置相关哈希可以高概率将相似的输入项哈希到相同的桶中
- 查找N个相似的段,随机选择一个段,并从哈希表中删除,然后利用拟合函数把选择段的开始和上一个段的结束平滑拟合
原理非常简单,主要的思想是GAN+LSH。
查询类型
这个流程的贡献其实是把时序的基本查询模式抽象出来,虽然本文是基于水利数据来评估的,但是这些查询其实适用于所有场景,基本的流程是通用的,当然公司内部的评估会更细,因为我们需要检查系统更细节的瓶颈。
下面虽然看着负责,其实很容易区分类型:
- data fetch
- filter data fetch
- aggregate + group by tags
- aggregate + group by tags, time
- aggregate + group by time (fill)
- aggregate
- Correlation 这种算子和其他的表达式不太一样
下面引用中的数据第一行是我通过图推算的infuxql语句,第二行是我跑了TSM-Benchmark以后拿到的真实测试语句。
Data Fetching

select id_station, *::fields from ts_table where st_id = x and st_id = y … and time > ?timestmp - ?range and time < ?timestamp
select time, id_station, s40, s39, s87 FROM “sensor” where (id_station =‘st9’) AND time > ‘2019-03-01T02:59:39Z’ - 1d AND time < ‘2019-03-01T02:59:39Z’"
查询指定时间区间内,指定st_id/s_list的原始数据信息。
用于评估数据的扫描和输出性能。
Data Fetching with Filter

- select *::fields from ts_table where st_id = x and st_id = y … and sensor_k > ?value and time > ?timestmp - ?range and time < ?timestamp
- select time, id_station, s92, s78, s12 FROM “sensor” where (id_station =‘st1’) AND time > ‘2019-03-01T16:32:47Z’ - 1d AND time < ‘2019-03-01T16:32:47Z’ and ( s92 > 0.95)
用于检查某个传感器的值是否超过阈值,filter的过滤只应用于一个传感器,filter的值是从数据分布中采样的,默认采样百分之5,此查询用于获取超过边界值的所有数据。
用于评估filter和输出的性能。
Data Aggregation

- select mean(*) from ts_table where st_id = x and st_id = y … and time > ?timestmp - ?range and time < ?timestamp group by st_id
- SELECT mean(s56), mean(s16), mean(s14) FROM “sensor” WHERE time > ‘2019-03-01T02:59:39Z’ - 1d AND time < ‘2019-03-01T02:59:39Z’ and (id_station =‘st0’) GROUP BY “id_station”
用于检查指定时间区间内多个station的多个传感器的平均值。
用于评估grouy by和聚合的性能
Downsampling

- select mean(*) from ts_table where st_id = x and st_id = y … and time > ?timestmp - ?range and time < ?timestamp group by st_id, time(1h)
- SELECT mean(s90), mean(s91), mean(s69) FROM “sensor” WHERE time > ‘2019-03-01T22:38:54Z’ - 1d and time < ‘2019-03-01T22:38:54Z’ and (id_station =‘st2’) GROUP BY id_station,time(1h)
先基于station分组,在在每个分组内按照时间聚合,这种方法可以缩小数据规模,且保留数据的主要趋势,这是一个非常常用的操作。
用于评估window operations和聚合的性能
Upsampling

- select max(*) from ts_table where st_id = x and st_id = y … and sensor_k > ?value and time > ?timestmp - ?range and time < ?timestamp group by time(5s) fill()
- SELECT id_station, mean_value FROM (SELECT mean(s31), mean(s13), mean(s20) as mean_value FROM “sensor” WHERE time > ‘2019-03-01T08:36:01Z’ - 1d AND time < ‘2019-03-01T08:36:01Z’ and (id_station =‘st3’) GROUP BY id_station,time(5s) FILL(0)) GROUP BY id_station
influxql在group by time时必须有聚合函数,这里其实传感器的上传数据时间间隔比较长,一般一个区间只有一个或没有值,所以可以使用 max
生成新的时间戳,并使用一些策略(interpolation,previous)来构建频率更高的时间对齐数据,可以用这种方式恢复序列中的缺失值。
用于评估 window operations 和 fill 的性能
Cross Average

- select mean(*) from ts_table where st_id = x and st_id = y … and time > ?timestmp - ?range and time < ?timestamp
- select s< sid1>, s< sid2>, (s< sid1>+s< sid2>)/2 FROM “db”.“autogen”.“sensor” where < stid> AND time > ‘< timestamp>Z’ - < range>< rangesUnit> AND time < ‘< timestamp>Z’
不执行维度上的聚合,查询一段时间内的传感器的值聚合,这个SQL其实扫描了全部的时间线。
用于评估查询和聚合的性能
Correlation

- select stddev(s_i)*stddev(s_j) from ts_table where st_id = x and st_id = y … and time > ?timestmp - ?range and time < ?timestamp
- influxql不支持
计算两个传感器一段时间的Pearson correlation[1]
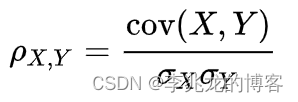
是两个变量的协方差除以它们的标准差的乘积,这个值在influxql中没法表示,因为influxql只支持标准差(stddev),而不支持协方差,但是flux中支持(covariance)。
评估
评估所采用的数据集是基于水利数据生成的两个数据集合,有如下特性:
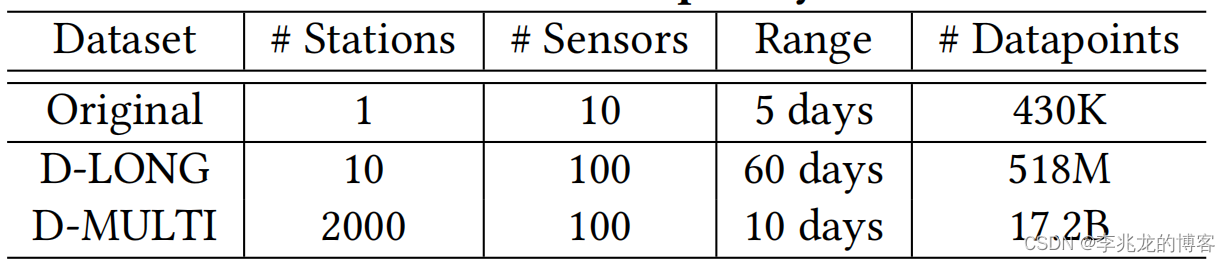
特征就是时间线较少,field非常多。
D-LONG: 10个时间线,5.18亿pointD-MULTI:2000个时间线,172亿point
机器配置主要看CPU和内存:
- Intel® Xeon® CPU E5-2620 v4 @ 2.10GHz (32cores)
- 128GB of memory
Offline Data Bulk Loading
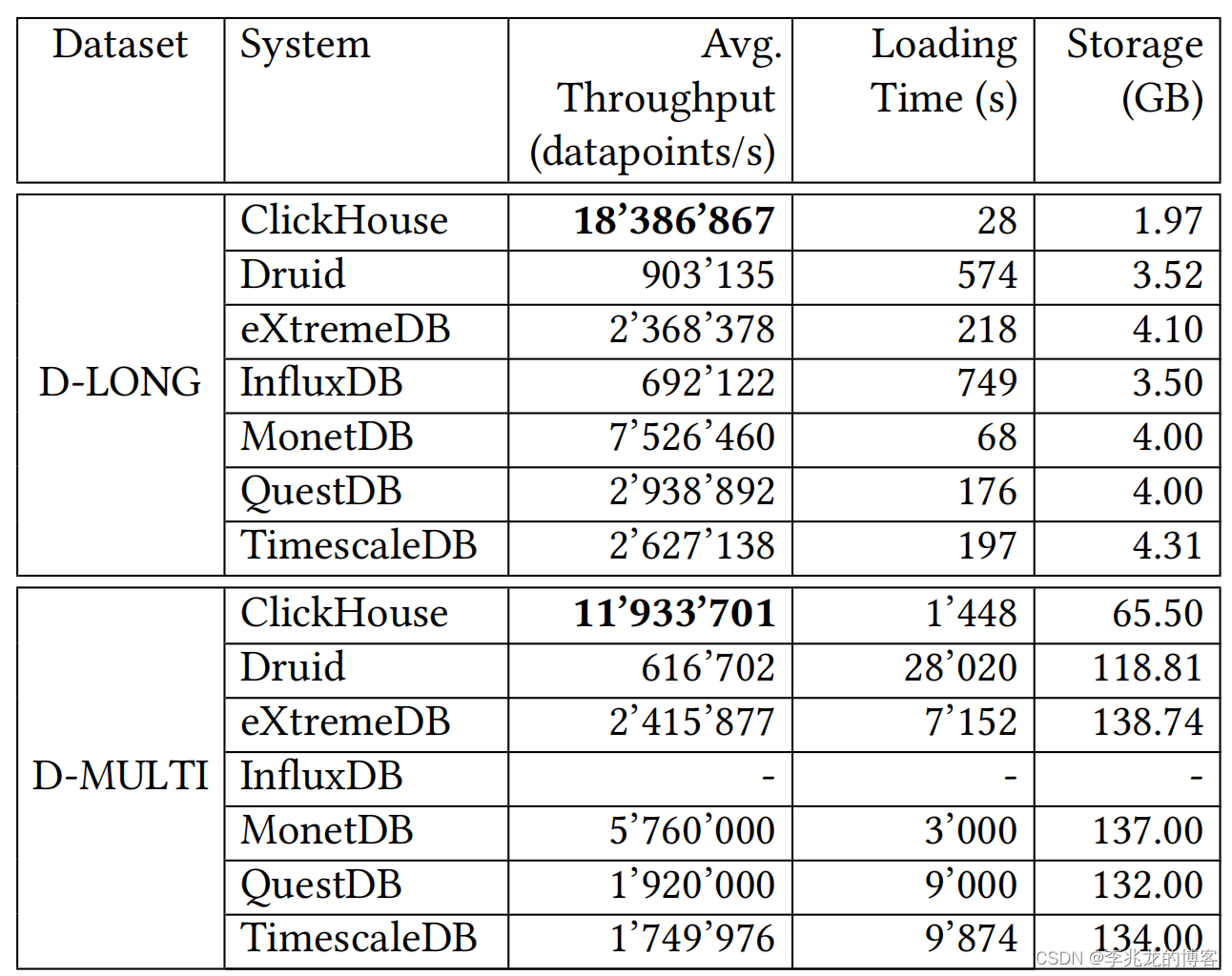
可以看到离线写的情况下ClickHouse取得了最优的性能,其实很好理解,因为对于CK来讲这其实是单主键,所有的field属于一个granule,只有主键需要排序,剩下的field直接插入。
而对于influxdb来讲一个包含100个field的时序数据在TSM中这是100个完全不同key插入。
其次压缩率上ClickHouse也是遥遥领先,这主要归功于sparse index,influxdb对于每个serieskey+field都存在一个索引,这导致了更低的压缩比。
Offline Query Workload
这一节只讨论涉及influxdb的评估,以下数据均基于D-LONG
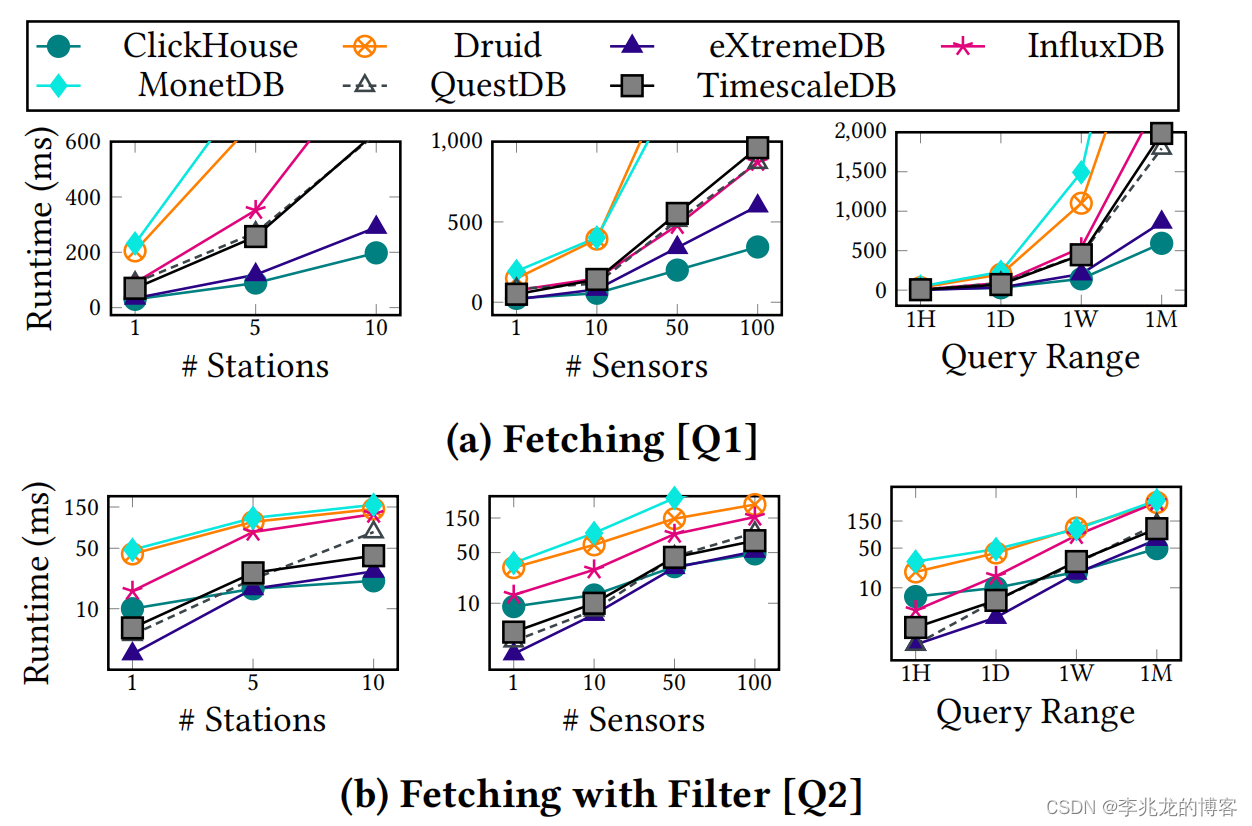
Q1/Q2主要用于评估引擎中获取数据和filter的性能
ClickHouse依旧是赢家,这其实很好理解,这种单tag多field的场景对于ClickHouse优势实在是太大了,CK的索引存储这主键对应granule的偏移,后续field的偏移不需要重新获取,这些都存在idx文件中,也就是可以通过单主键获取所有field的偏移,其次sparse index发挥了最大优势,因为一个granule的所有数据基本都是需要输出的,其次还可以基于主键做分区,这又增加了并行性。
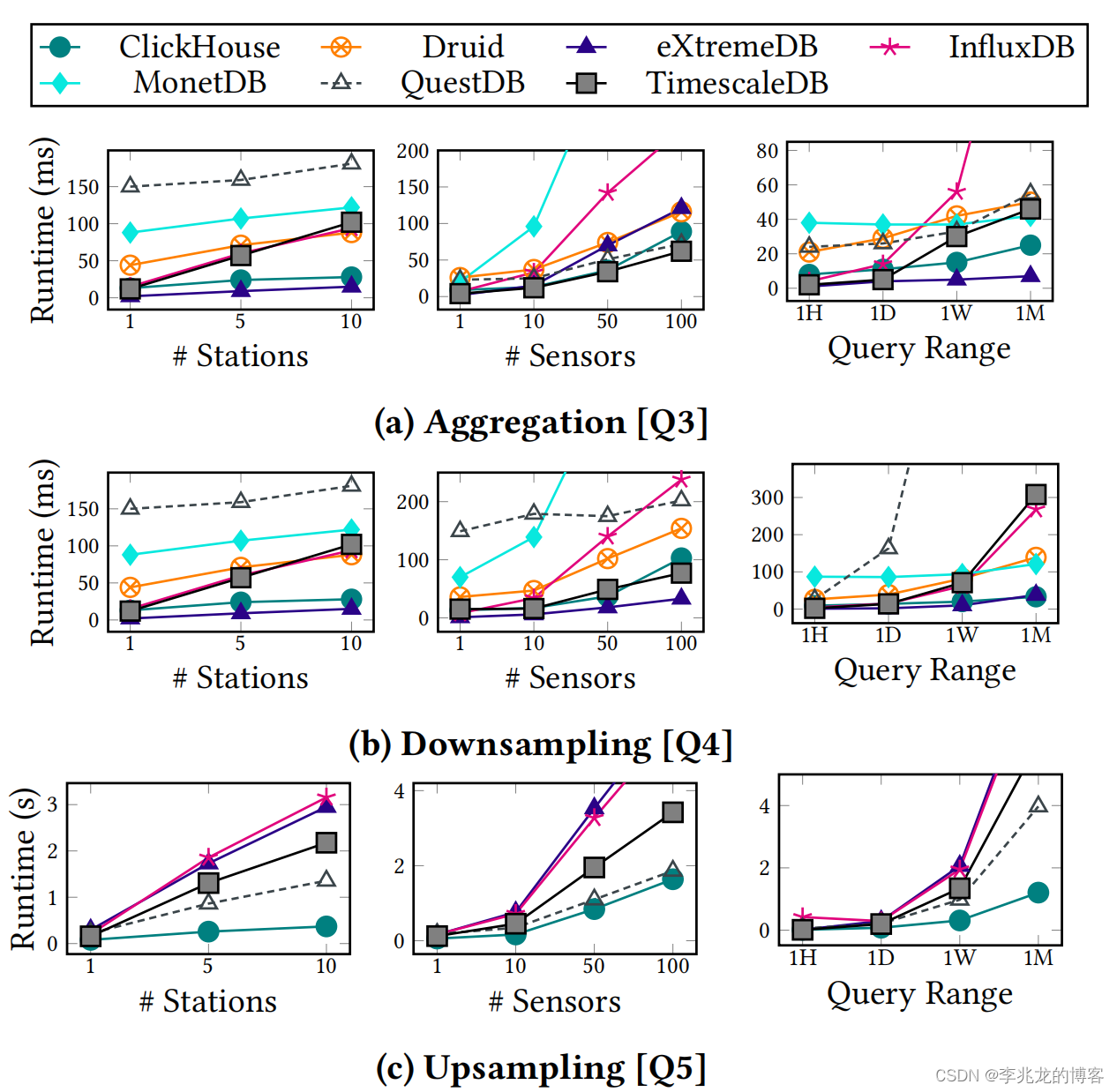
目前我的能力不能做到对这个结果给出真正合理的解释,后续真正搞清楚后来补充原因
Online Query Workload
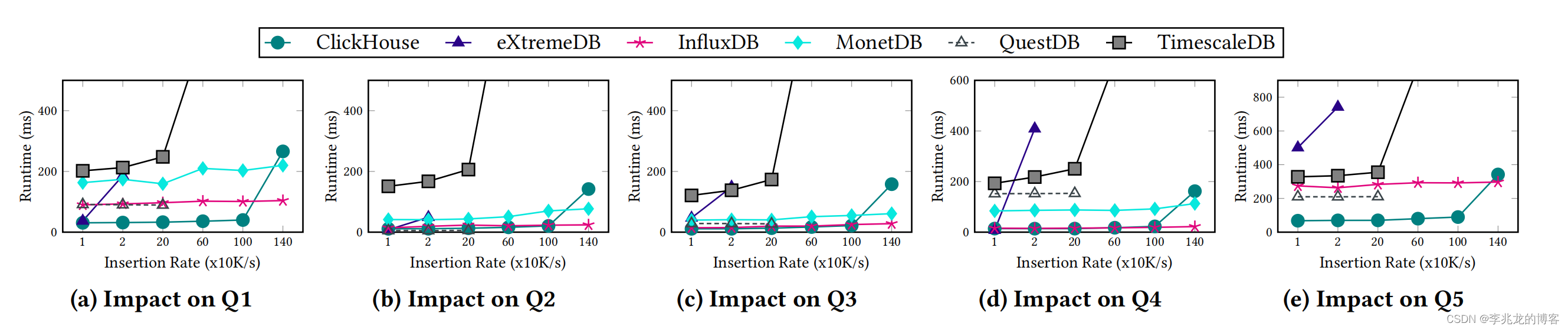
最令人激动的时刻,TSM终于!遥遥领先!
结果显示在插入速率较低时,基于B-tree-based 的QuestDB获得了最优的查询性能。
插入速率较低对array-based 的系统有很大影响;在 eXtremeDB 中,插入是通过在序列末尾追加新元素来完成的,这会导致查询速度减慢,查询运行时间不稳定。
在 TimescaleDB 中,速度逐渐变慢的原因是新插入的数据仍未压缩,因此它需要从磁盘加载未压缩的数据,导致无法从其压缩格式的 IO 优化中获益。
插入率较高时只有 InfluxDB 和 ClickHouse 能够达到优秀的查询性能。对于图中CK明显的性能降低论文给出的理由是:有很大一部分新数据需要合并,超过了系统的并行化能力,而InfluxDB无需额外的合并开销。我认为这个结论是无法令人信服的,influxdb也存在compaction的影响性能的问题,且seriesfile,TSI,TSM都有compaction的可能。
结论
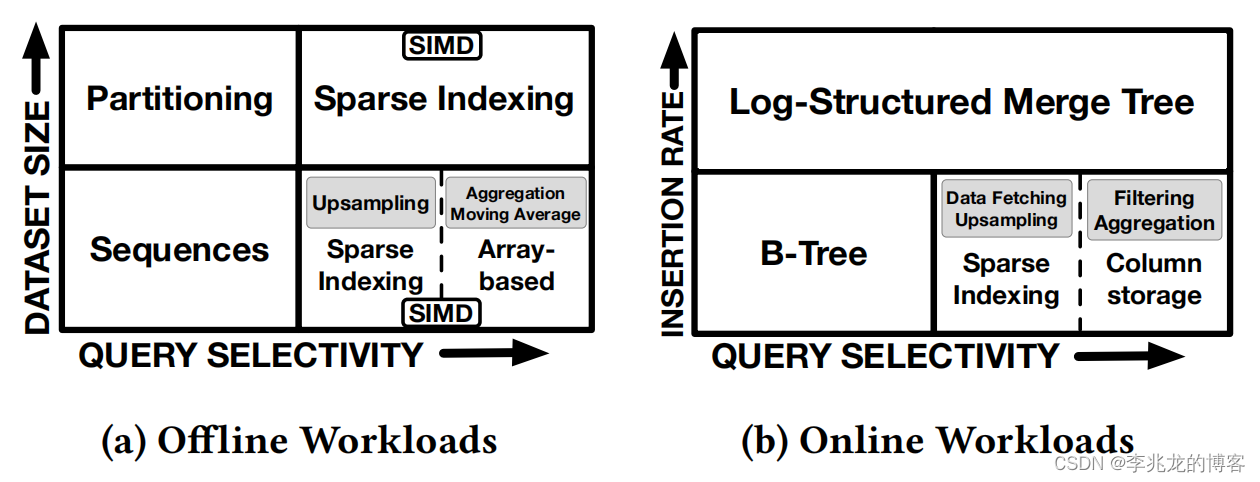
一图胜过千言万语,显然高写入的在线场景才是云原生时序数据库的普遍场景。
当然文章中并没有与Influxdb-IOX,IotDB等基于Parqut,Tsfile这种独立时序文件的数据库做对比,我认为这些数据库在这个场景中才是最有优势的。
其次influxdb最大的优势其实在于tag的种类较多的场景,field较少的场景,这种情况下可以快速的索引到对应的时间线,从而快速在TSM中找到对应的数据块,这是CK再怎么比也无法媲美的。
参考: