 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
春节假期回到家里断然是不会有看纸质书的时间的。造化弄人,二月三号早上十一点的飞机延误到一点多,原本三小时不到的阅读时间延长为五个小时,也给了我看完这本书的机会。
第一次了解到这本书是Tison在朋友圈发了他写的书评[2],开头便是:
值得一读,尤其是对开始开发流计算任务或系统一到两年,初步实现过一些功能或作业,但是还没有对流式系统建立起系统认识的开发者。
Tison参与开源的起家项目就是Flink。而我对于流计算系统接触起源于时序数据库的流式计算(降采样),时序数据的以目前使用的场景来看,绝大多数还是把分钟/秒级别数据基于SQL规则降维度/不降维度(对应group by tag/*)到小时/天级别,这样的需求大多数决策者会在写入链路上加一个Flink/Spark,将数据本身处理后写入时序数据库,这也导致业务成本上相当一部分是在Flink/Spark上的。
我们可以看到TDengine的官网上将缓存、流计算,数据订阅以及时序数据库的功能闭环在TDengine内部,并将此作为卖点之一,核心是为了降低系统设计复杂度和运行成本,并标榜自己为时序大数据处理平台。
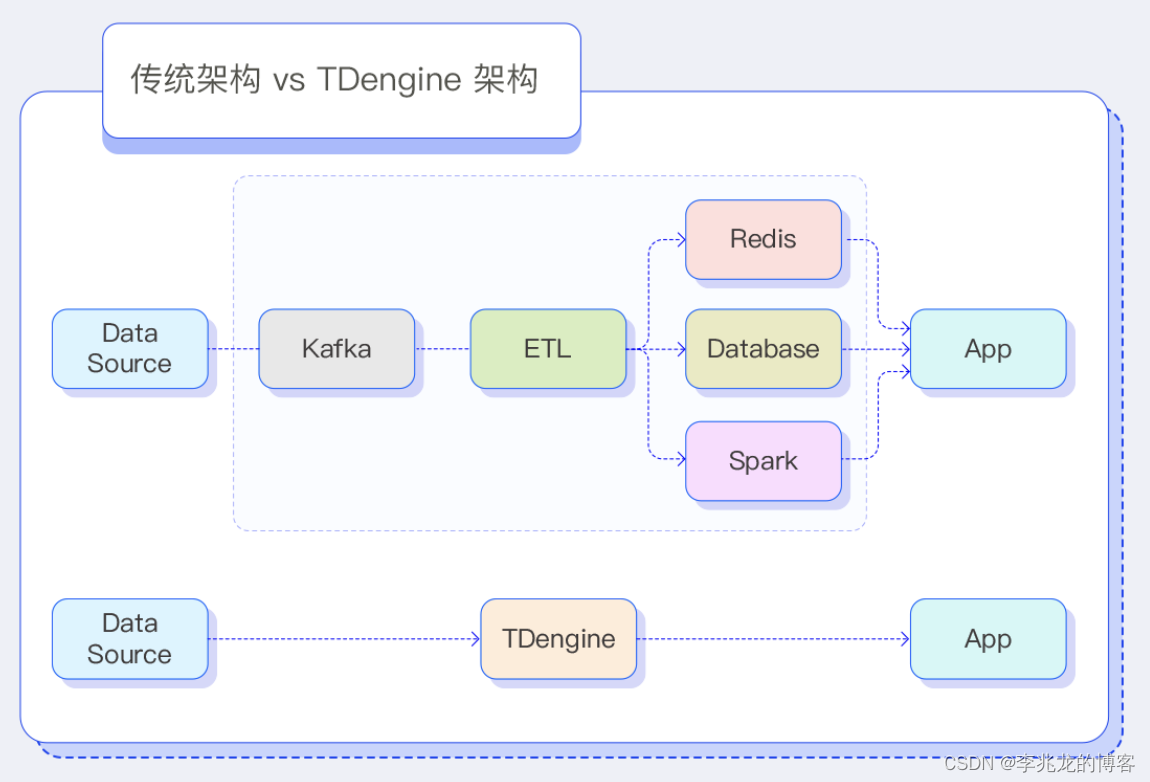
我对于流计算系统的浅薄了解便来自于这里。事实上TDengine包括我们的实现标榜为流计算系统并不完全正确,准确的说应该窗口仅为时间,无状态的,且非DAG的简化批处理系统,但是这样的场景对于目前绝大多数需求完全够用,因为目的是为了加速查询而不是给业务赋能。
我参与了腾讯新一代时序数据库从立项到上云的全过程,并实现了对于系统内部简化流计算能力的支持,所以非常符合“开始开发流计算任务或系统一到两年,初步实现过一些功能或作业”的人的,这也是读这本书的主要原因。
在开始书评之前,以TDengine这张图为背景,我以我浅薄的知识评价下在决策者的角度我会怎样使用时序数据库。
- 首先我认为时序数据库的流式计算能力是可以解决时序场景中的绝大多数分析需求的,所以我愿意尝试这里的能力。但是对于是否降本我持怀疑态度,因为系统内部执行流计算系统需要大量的内存,尤其是在流计算任务较多时(每个measurement一个,这个数字会极度膨胀),这个时候扩容成了唯一的方法,如果只按照读写的能力去申请资源,加上流计算的资源消耗存在内存风险。但也并不是没有显而易见的好处,即数据库自治,绝大多数情况只有数据库自己知道该如何较优构建降采样和流计算。
- kafka的钱是省不了的,这是系统的最后兜底,假如我是一个CEO不可能把我身家性命放在“时序大数据处理平台”的,而且业务数据还需要做更高级的分析需求(降维度,接入用户内部分析系统等),时序数据库的流计算短期能很难看到超越专业流计算系统的可能,所以接受到业务数据后架一个kafka是必要的。
- Cache功能完全可以集成到时序数据库内部,这里有两个场景,1. 系统需要快速将最新数据返回给应用程序 2. 相同sql数据缓存,实际查询只查询两次sql的时间差值内的数据,减少CPU/内存消耗;时序数据库集成这些功能是完全可行的,对于我们开发的多模数据库,可以在用户的资源内起一个SSD Redis db,存储大量数据在SSD中,在增加了存储利用率的同时减少了用户查询时延。
内容
若河床上没有岩石,溪流就不会有歌声
第一章阐述了应用程序,后台服务,批处理系统,流处理系统之间的区别,并讨论多阶段架构,为后续引出DAG做铺垫。
先解决问题,再编写代码
第二章引入收费站的例子,指出基于Web服务构建存在流量增加时请求延迟引发了系统迟滞,导致结果不准确的问题,因而引出使用流系统,并指出流系统的核心概念由事件,作业,源,算子和流构成,处理引擎由源执行器,算子执行器和作业启动器构成。
九个人不可能再一个月造出一个孩子
第三章介绍了并行化和数据分组,这可以解决分布式系统的一个根本挑战,即如何扩展系统以增加吞吐量,或者说如何在更短的时间处理更多的数据。并行化包含数据并行和任务并行,前者含义为将一个任务的不同子集交给不同的执行单元,后者含义为在不同的数据上运行相同的任务。章节的后续引入事件分发器,并提出分组概念,为了下游组件可以高效的并行处理上游事件,这和kafka中的partition概念基本一致。
糟糕的程序员担心代码,优秀的程序员担心数据结构和它们之间的关系
第四章引入欺诈检测的case,与之前不同,这时的流并不是一条直线,在数据源之后需要执行多种检测,这就引出了DAG,并解释了算子的扇入扇出,同时指出扇出时发出的事件可以只被推送到某些输出队列中,此外不同的输出队列中可能拥有不同的数据。
人们从来没有足够的时间去做正确的事情,但总有足够的时间去重做一遍
第五章介绍了送达语义,即至多一次(At-Most Once)、至少一次(At-Least Once)和恰好一次(Exactly Once),并指出Exactly Once需要重试和幂等来保证。在我们的时序系统中实现了kafka ingest,需要接受用户写入kafka的数据,并高效的写入引擎,这里开始我们使用autoCommit,这就是经典的至多一次,但是存在数据丢失风险,后来我们使用手动管理offset,保证在实际写入成功后再提交offset,但这依旧只能保证至少一次,真正的恰好一次是靠时序数据库本身的幂等保证的。
技术使人们能够控制除了技术以外的一切
第六章是对前五章的总结。
计算机能集中注意力的时间只和它的电源线一样长
第七章讨论了窗口计算和窗口水位;前者讨论了固定窗口,滑动窗口和会话窗口,并指出可以使用外部系统来完善窗口算子;其次提到乱序数据的到达需要设置窗口水位,一般情况下维持多个窗口开销较大,以目前的经验用户通常可以接受丢弃这部分数据。Tison提到The Dataflow Model 是 Google 流计算的经典论文,Dataflow 模型的开山之作,简单浏览了一下文章内容,窗口水位部分对应文章中:
- When in processing time they are materialized ?
- How earlier results relate to later refinements ?
这里我还想讨论下目前公有云监控的实时性问题,腾讯云上目前分钟监控在120s内,秒监控在12s以内,这个值是怎么得到的呢?时序数据本质上也可以看作一个有界的数据流,分钟级别监控可以认为是窗口为时间的数据,在这种情况下首先存在一个攒数据的过程,因为不确定数据实在一分钟的哪一秒到达,这就60s了,在加上上报存在失败,在最后1s失败时允许重试,最后就是时序数据库内写入的削峰,这些加起来产品给出了120s的保证。
一个SQL查询来到酒吧,走到两张桌子(table)前问道:我能加入(join)你们吗
第八章讨论JOIN。书中把join当作一种特殊的扇入方式,并提出流必须转化为表才可以执行join,同时讨论了双流join中首先基于窗口物化流,其次再join。这一节的内容在我们的流系统中无法使用,但是在流式查询引擎中还是有理论指导意义的,首先基于窗口截取,其次再合并返回。
永远不要相信一台你无法扔出窗口的计算机
第九章讨论了流系统中广泛支持的故障处理机制,即反压,一种与数据流向相反的压力。因为流是源源不断的,如果存在某个模块出现预期之外的情况,问题很快会传播到其他组件,导致系统崩溃,反压就是最后一道防线,
具体介绍了如何判断繁忙状态与如何执行反压,前者我认为与系统相关,后者的处理是通用的,1. 停止数据源 2. 停止上游组件 并需要考虑如何解除反压状态让系统恢复。
且反压需要区分事件,比如实例宕机或者消费能力不足,这两者靠自身都是无法恢复的,需要拉起实例和增加资源,书中还提到一种特殊的case,即持续触发反压,这会造成整个系统的抖动。
这一章对我来说最大的意义在于从理论上确定了在流系统上思考极端情况是有理论基础的,在我们的实现流计算过程中就遇到过类似的问题,比如WAL拉取导致计算节点CPU暴增处理包变慢,存储节点累计大包,出现大范围OOM;其次还有在均衡操作触发时存在消费老数据的情况,造成CPU激增,影响其他组件;这些其实都是没有考虑反压的情况。
对于如何判断繁忙状态与如何执行反压,前者可以通过统计CPU/内存来做,后者可以选择停止输入和丢弃,工程上不同的场景在监控上需要可以体现。
重启试试
第十章讨论了有状态计算,这同时是Flink的最大价值,即而在于实现了带状态的流计算。这一章主要阐述状态和检查点,即何时持久化状态,书中给出的方法是在数据流中加入检查点,这可以理解为屏障(barrier)。其实以目前我们在时序数据库中实现的流系统来看,最难的点其实在于调度,因为调度的复杂性,我们没有选择有状态的流计算,在出现故障时,选择重放几个窗口的事件,并限制CPU/内存使用。
成功不在于是否曾经摔倒,而在于能否重新站起来
第十一章终章是对七到十章节的总结和展望。
总结
现有的时序数据库只是实现了窗口仅为时间,无状态的,且非DAG的简化批处理系统,想以此替代流系统的全部份额基本不太现实,但是确实可以拿下其中部分收益,领域垂直公司需要故事去活下去,但是公有云需要关注业务上真正需要解决的问题,可见的未来我们的精力不会投入到完善时序的流计算系统中去。
参考:
- 大图书馆 #8 流式系统阅读指南
- 大图书馆 #9 《流计算系统图解》书评
- 支持消息队列和流式计算背后,TDengine 3.0 存储引擎的优化与升级
- DolphinDB教程:流数据时序引擎
- 一文学会如何使用 TDengine 3.0 中的流式计算
- 支持消息队列和流式计算背后,TDengine 3.0 存储引擎的优化与升级
- Naiad:A Timely Dataflow System
- 论文阅读-Naiad:A Timely Dataflow System
- The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing
- 大数据理论篇 - 通俗易懂,揭秘谷歌《The Dataflow Model》的核心思想(一)