 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
引言
《M2Bench: A Database Benchmark for Multi-Model Analytic Workloads》阐述了一种测试多模型数据库系统的Benchmark方法,我理解对于Benchmark而言,核心点在于测试方法与数据生成。
测试方法的角度看,M2Bench基于E-Commerce,Healthcare,Disaster&Safety三个业务场景,总结出17种涉及 relational, document-oriented, property graph, 以及 array models 四个数据模型的操作集合,以此作为测试多数据模型分析负载的Benchmark主体。
从数据生成的角度看,M2Bench在不同的场景使用不同的已有公共数据集合:
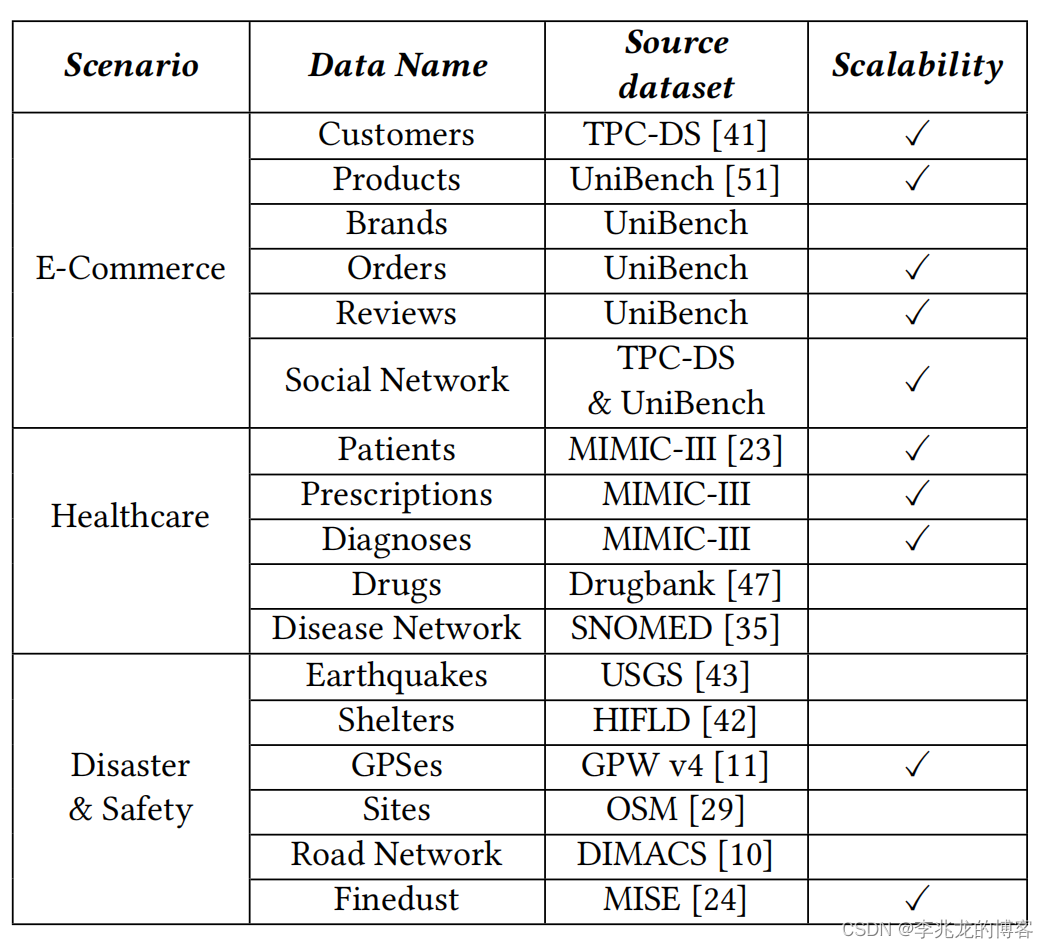
这与[5]中的基于GAN(Generative Adversarial Network)+LSH(Locality-Sensitive Hashing)生成时序数据集的思路完全不一样。
作为同样以Benchmark的设计入选vldb2023的TSM-BenchMark[5],测试方法与数据生成是实际的创新点;而M2Bench则把可以用一个Benchmark测试多数据模型分析负载作为创新点,但是我认为因为其数据生成和测试方法固化以及几乎无法改变测试的数据模型,实际在业界大推广M2Bench基本没有太大价值,可以说就是一个小圈子内的狂欢。
于我个人而言,M2Bench的价值则另有所在:
- 从一个复杂业务的角度如何测试底层数据库的使用方式
- 文章的测试阶段选择使用 MySQL, MongoDB, Neo4j, SciDB作为对照组,与ArangoDB(json/graph/kv/search engine,测试中relational和array使用json模拟)/ AgensGraph(relational/graph) 同时执行现有的测试,我认为这从业务使用角度论证了多模数据库的发展方向
M2Bench测试结果
综前所述,我认为数据集,不同模型间表的设计以及测试本身内容都不重要,我们关注结果就可以
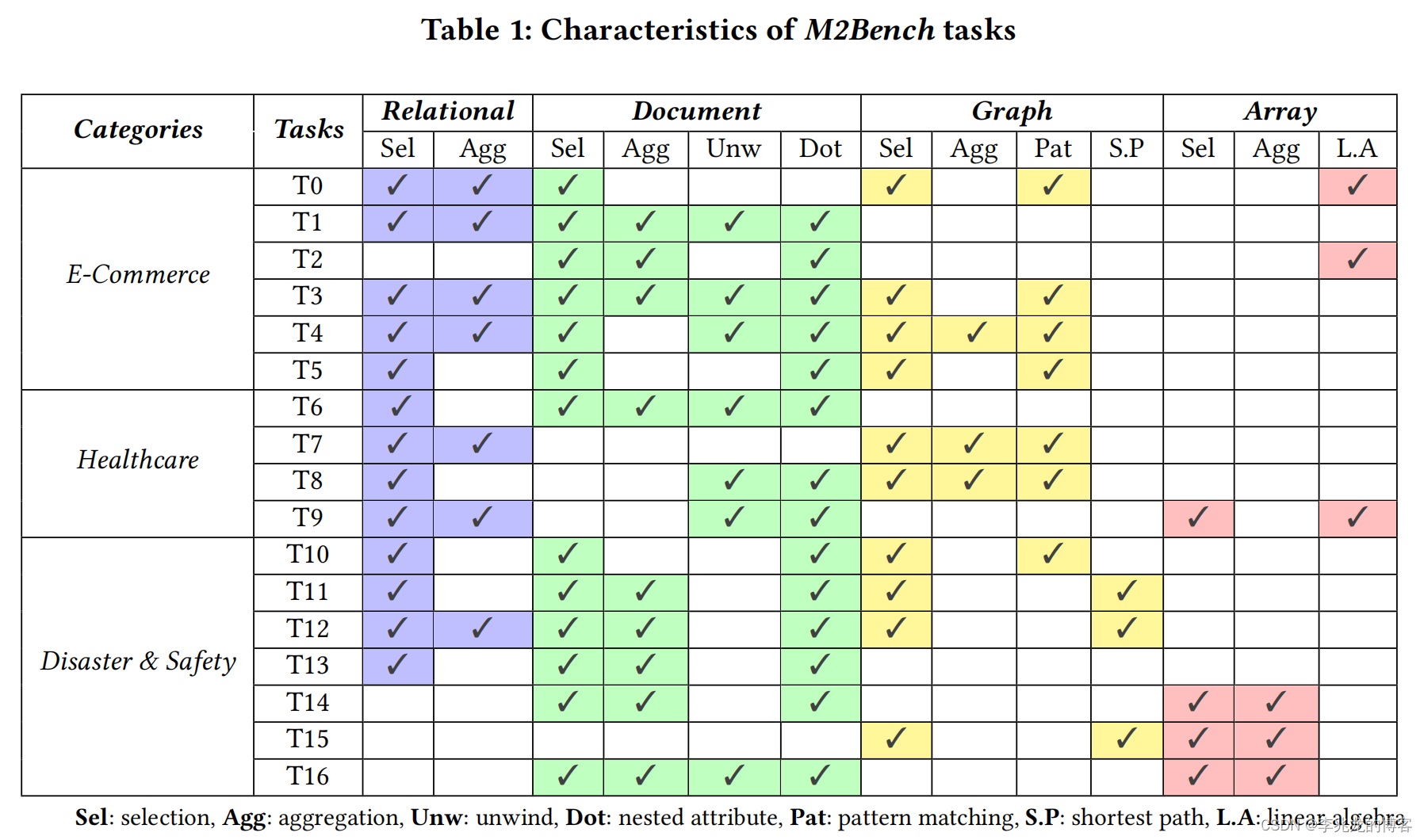
表1描述了M2Bench的17种任务操作所涉及的数据模型。
测试的环境为:a standalone machine with Intel i7-9700K CPU, 32GB RAM, and a 512GB SSD running Ubuntu18.04.4 LTS,比较理想化
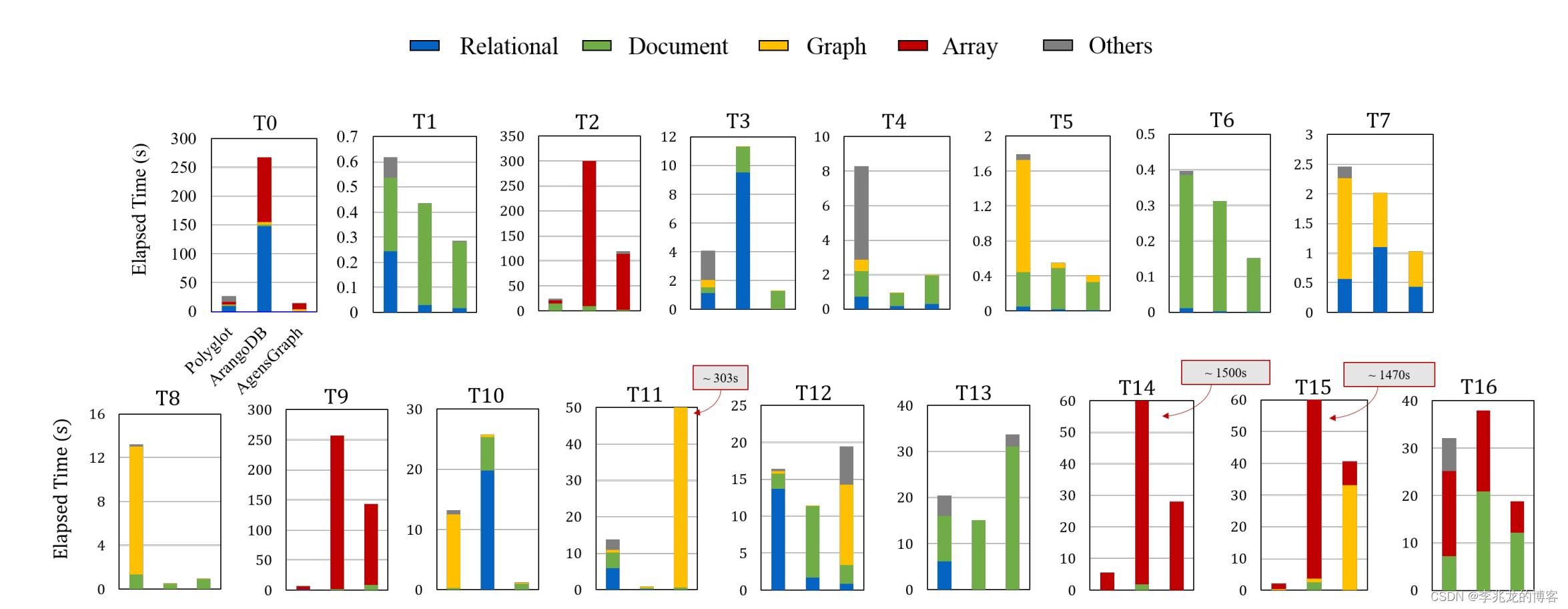
时延对比当然不是衡量数据库整体质量的正确方式,而且看论文中的描述也是先导入写再测试读的离线场景,与实际运营场景不一致,这点瑕疵我们暂时不谈。上图描述了Polyglot( MySQL, MongoDB, Neo4j, SciDB)与ArangoDB / AgensGraph 在17个任务下的查询时延对比。
从上述结果我们可以得到以下结果:
- 在需要密集array计算的场景下 Polyglot 优于 ArangoDB / AgensGraph [T2, T9, T14, T15]。原因是 SciDB 的原生存储引擎以块为单位存储数组,从而保留了数组单元的locality。AgensGraph 和 ArangoDB 分别以table和collection的形式存储数组,其中每一行或每一个文档代表一个数组。因此矩阵乘法等数组操作将不得不访问随机分散的行,从而导致过多的磁盘 I/O 操作。但是T16是一个例外,虽然需要array操作,但是polyglot 系统的性能不是最好的,因为 T16 需要随机迭代访问数组单元。这种访问模式对 polyglot 系统并不有利。
- ArangoDB 拥有原生graph/json引擎,在 [T4, T8, T11, T12, T13]优于其他两者。
- AgensGraph 拥有原生relational引擎,在 [T0, T1, T3, T5, T7, T10, T16]优于其他两者。虽然AgensGraph使用relational引擎支持图模型,并不是原生支持图引擎,但是在部分图操作中AgensGraph快于ArangoDB。
- 原则上 Polyglot 每一种模型都选择了对应数据模型的龙头产品,但是Polyglot并不是每一种负载都是最优的选择,原因是假如两张表存在于两个模态的数据库时,执行连接操作非常缓慢,需要频繁的调用一方的查询操作。
基于上述结果我们可以得到如下结论:
- 结论1:基于统一kv/宽表底座的多模型数据库是错误的方向,只有不同模型拥有不同的存储引擎才可以带来最大的综合性能优势
- 结论2:哪怕是最优秀的存储引擎也只是在Trade-off,没有一种设计可以保证所有情况下的最优,所以需要智能化调优,并在项目选型之初选择最适合业务场景的引擎。
- 结论3:完全独立的多个不同模型数据库对于联合分析的场景性能较差
从Lindorm看待多模的发展方向
早在2019年,李飞飞老师在[4]中讨论了未来数据库的发展趋势将会集中在以下几个方面:
- 云原生与分布式
- 大数据与数据库一体化
- 软硬件协同
- 多模型
- 智能化运维,自治性与智能性
- 安全可信
对于其中的多模型分析,李飞飞老师在当年将其发展归结为两个方面:
- southbound multi-model access:
底层存储支持不同的数据格式和数据源。存储的数据可以是结构化的,也可以是非结构化的,如图形、vector和文档存储。数据库提供统一的查询接口,如 SQL 或类似 SQL 的接口,以查询和访问各种类型的数据源和数据格式,形成数据湖服务。除此之外,许多云应用需要从异构来源收集大量数据,并进行联合分析。 - northbound multi-model access:北向多模型访问表示使用单一数据模型和格式(如大多数情况下的键值模型)将所有结构化、半结构化和非结构化数据存储在单一数据库中。在这种单一存储模型的基础上,数据库根据应用需要支持多种查询接口,如 SQL、SPARQL 和 GQL
当时看这篇[4]论文的这个论点没有明白,结合[3]的实验结论,有一种豁然开朗的感觉。
五年过去了,我们回过头看下2024年Lindorm的产品架构文档设计图[7]:

官方介绍稿中点出了Lindorm顶层设计上的几个重点:
- 存储计算分离
- 其中云原生分布式文件系统LindormDFS为统一的存储底座,向上构建各个垂直专用的多模数据引擎,包括宽表引擎、时序引擎、搜索引擎、流引擎等。
- 在多模引擎之上,Lindorm既提供统一的SQL访问,支持跨模型的联合查询;又提供多个开源标准接口(HBase/Cassandra、OpenTSDB/InfluxDB、Kafka、HDFS),满足存量业务无缝迁移的需求。
- 数据通道服务(LTS)负责引擎之间的数据流转和数据变更的实时捕获,以实现数据迁移、实时订阅、数湖转存、数仓回流、单元化多活、备份恢复等能力。
从现在的结果看,Lindorm的发展确实是按照着李飞飞老师的预期在走的。
总结
从目前的知识体系来看,Lindorm的顶层设计我认为没有明显的短板,这也许是Lindorm TSDB的设计可以入选vldb2023的原因。
但是也并不是毫无进步的余地,以本文得到的结论2看,数据库引擎自动化调优的方向还有极大的优化空间,尤其是是时序模态,因为目前主流的时序模态都允许按照时间粒度切分物理存储,这使得我们有机会去修改新存储的引擎结构。像kv,json这样的模态引擎基于物理数据的分裂合并去实现扩缩容就很难去修改引擎结构,只能做一些参数上的优化。
参考:
- Why Arrays as a Universal Data Mode
- 邻接矩阵的COO格式
- M2Bench: A Database Benchmark for Multi-Model Analytic Workloads vldb2023
- Cloud-Native Database Systems at Alibaba: Opportunities and Challenges vldb2019
- 从一到无穷大 #14 Online, realistic data, querying variable Time Series Database Benchmark
- 从历史见证未来,Distributed SQL?云原生数据库? 多模型数据库?
- Lindorm产品架构
- 从一到无穷大 #13 How does Lindorm TSDB solve the high cardinality problem?