论文地址点这里。
TL;DR
-
MemoryDB 通过底层依赖 AWS 内部系统 Multi-AZ Transaction Log 实现了 11 个 9 的持久性保证。
-
通过依赖 Transaction Log 的 Condition API 和租约机制来实现了一致性和可用性保证。
-
通过周期性调度 Off-box 节点来外部 Rewrite binlog 避免了内存 Fork 影响用户业务可用性。
-
通过 Binlog 的 checksum 校验机制来保证数据的正确性。
MemoryDB 是 AWS 推出的内存数据库,兼容 Redis API,与 ElastiCache 相比,可以提供 11 个 9 的可用性。本篇文章对 AWS 刚发布的 MemoryDB 论文进行讲解。
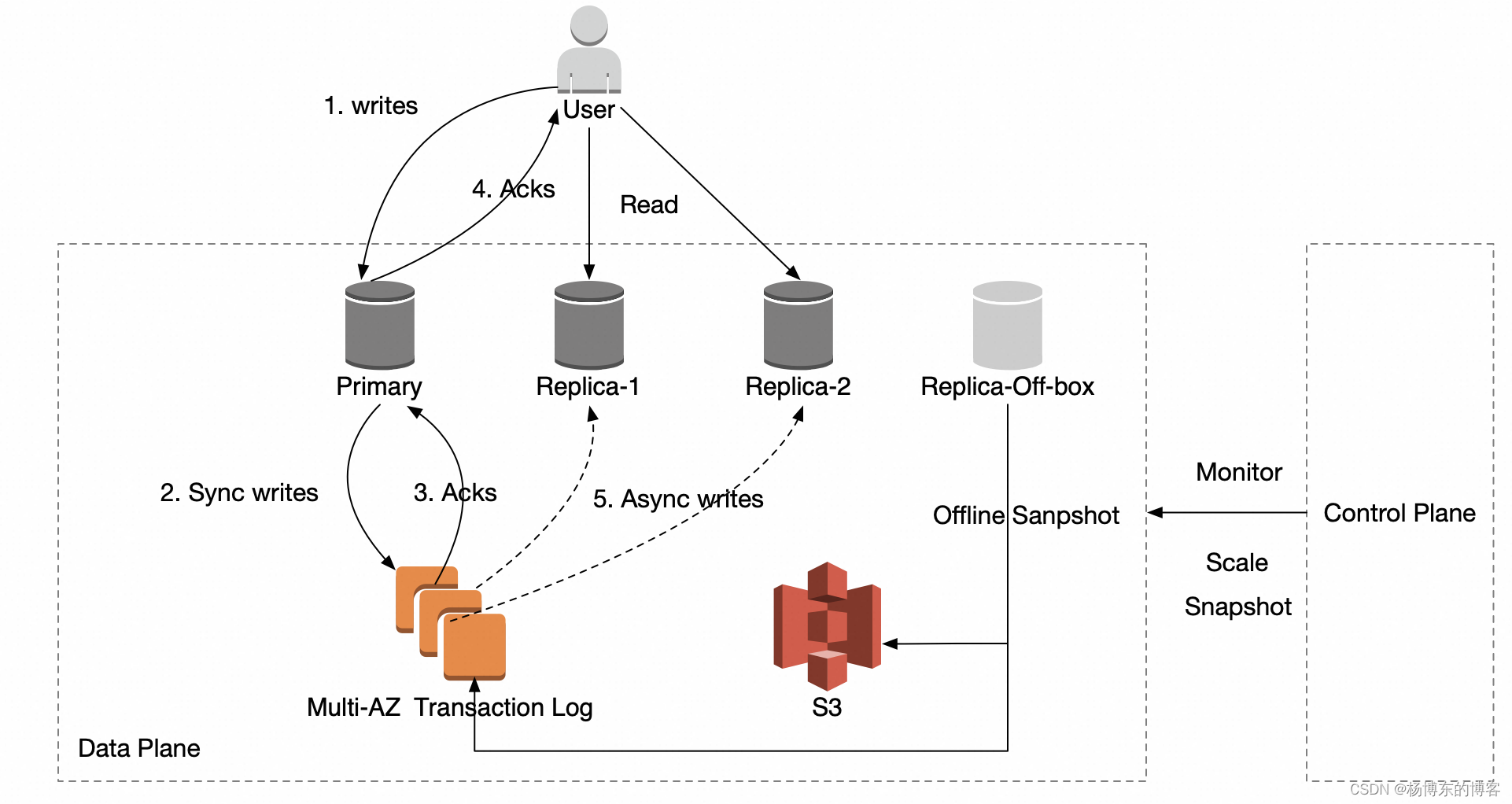
-
架构上支持一个 Primary + 多 Replica 结构。
-
写入流程
-
客户端写入到 Primary
-
Primary 修改内存结构,将回复暂存,并将 AOF 写穿到 Transaction Log
-
Transaction Log 写入成功之后,Primary 再回复客户端,如果写入失败,需要重试直到成功,否则一直无法回复客户端。
-
之后同链接的读取可见。
-
-
读取流程
-
读取 primary,能保证读取到最新数据,且能保证读取到的数据一定是写入到 Transaction Log 中的。
-
读取 replica,不保证能读取到最新数据,replica 消费可能有延迟。
-
-
全量数据是 S3 中的最新 RDB 加上对应 offset 开始 Transaction Log。
-
Control Plane 是多租户的,主要负责以下几件事情:
-
集群生命周期管理。
-
周期性调度 Off-box 实例来重写 binlog,重写操作是 Load 之前的全量数据到内存,然后重新 dump 一份新的 RDB 到 S3
-
Failover 流程
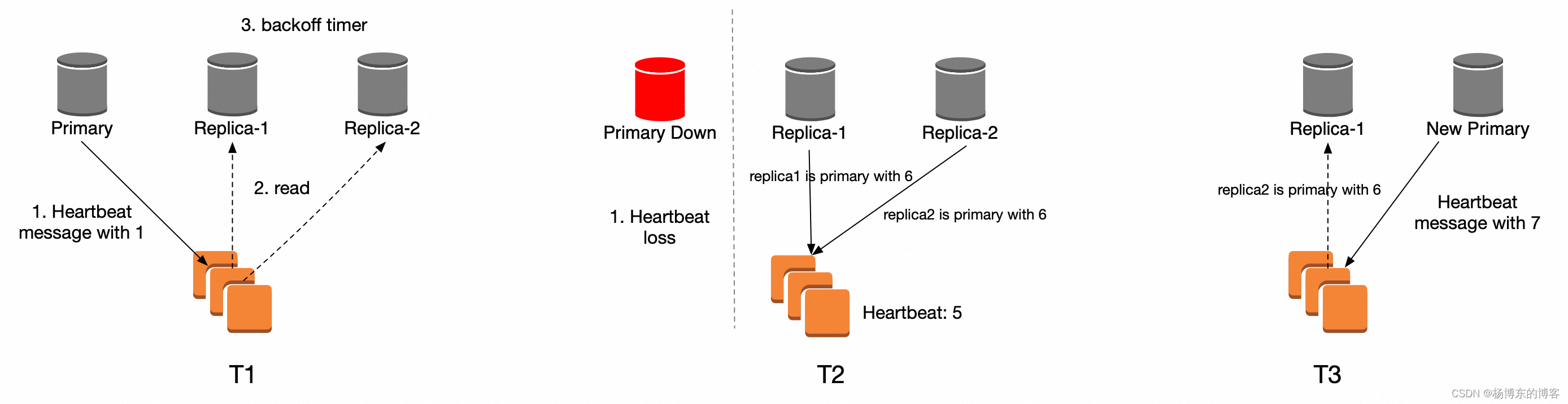
以上图一个 primary + 两个 replica 的集群为例,描述 Failover 过程:
-
T1,Primary 会周期性的写入 heartbeat 消息,注意,此时的 heartbeat 消息也提供了租约机制,replica 消费到租约消息之后,会进入 backoff timer(timer 强制大于 heartbeat 携带的时间长度),replica 在 backoff timer 中不会发起新的选举。
-
T2,Primary Down,heartbeat loss,假设此时 heartbeat 的 ID 是 5,replica-1 和 replica-2 结束 backoff timer 之后,未观察到续租消息,将会主动发起选举,他们会携带自己消费到的最新 heartbeat ID + 1 去选举。
-
replica1 writes “replica1 is primary” to the log with ID 6
-
replica2 writes “replica2 is primary” to the log with ID 6
-
-
T3,replica-2 成功,成为新的 Primary,replica-1 收到 replica-2 选举的 binlog,自己也会进入 backoff 时间,不再尝试选举。replica-2 会通过 gossip 消息向集群中同步自己竞选成功的消息。
脑裂问题
MemoryDB 本身不会脑裂,因为通过 Transaction Log 的唯一接口来选主,假设 T2 时刻,死去的 Primary 再次复活,尝试选举:
-
Case 1:Primary 此时还是拥有最新的 binlog,所有的备存在都没有消费完的可能,那么 primary 带着最新 ID + 1 去竞选就可能成功,一旦成功,剩余的 replica 发起的竞选就会失败。
-
Case 2:Primary 再次恢复时候,别的 replica 已经竞选成功了,那么它带着自己一个落后的 ID + 1 来竞选发现会失败,此时去消费 binlog,则会知道别人已经是 master 了,则进入 backoff timer,不再参与。
扩缩容流程
-
扩容 replica 节点数量
- 申请或者销毁新的 ECS,然后从 S3 获取 SNAPSHOT,并且继续消费最新的 binlog。
-
改变实例 ECS 类型
-
滚动升级的过程,先操作 replica,最后切换 primary,切换 primary 会造成重新选主。
-
如果用户指定的 ECS 类型太小产生了内存满的情况,则回滚。
-
-
扩容分片数量
-
申请新分片,通过 slot 迁移来传输数据。新节点先接收 slot snapshot,然后源端会 pasue write,并且将增量都发送过去。之后会进行数据握手检查。失败就终止流程,成功继续。
-
更新元数据表,用了 2pc 的方式,如果此时源或者新奔溃,可以拉起后恢复。
-
测试情况
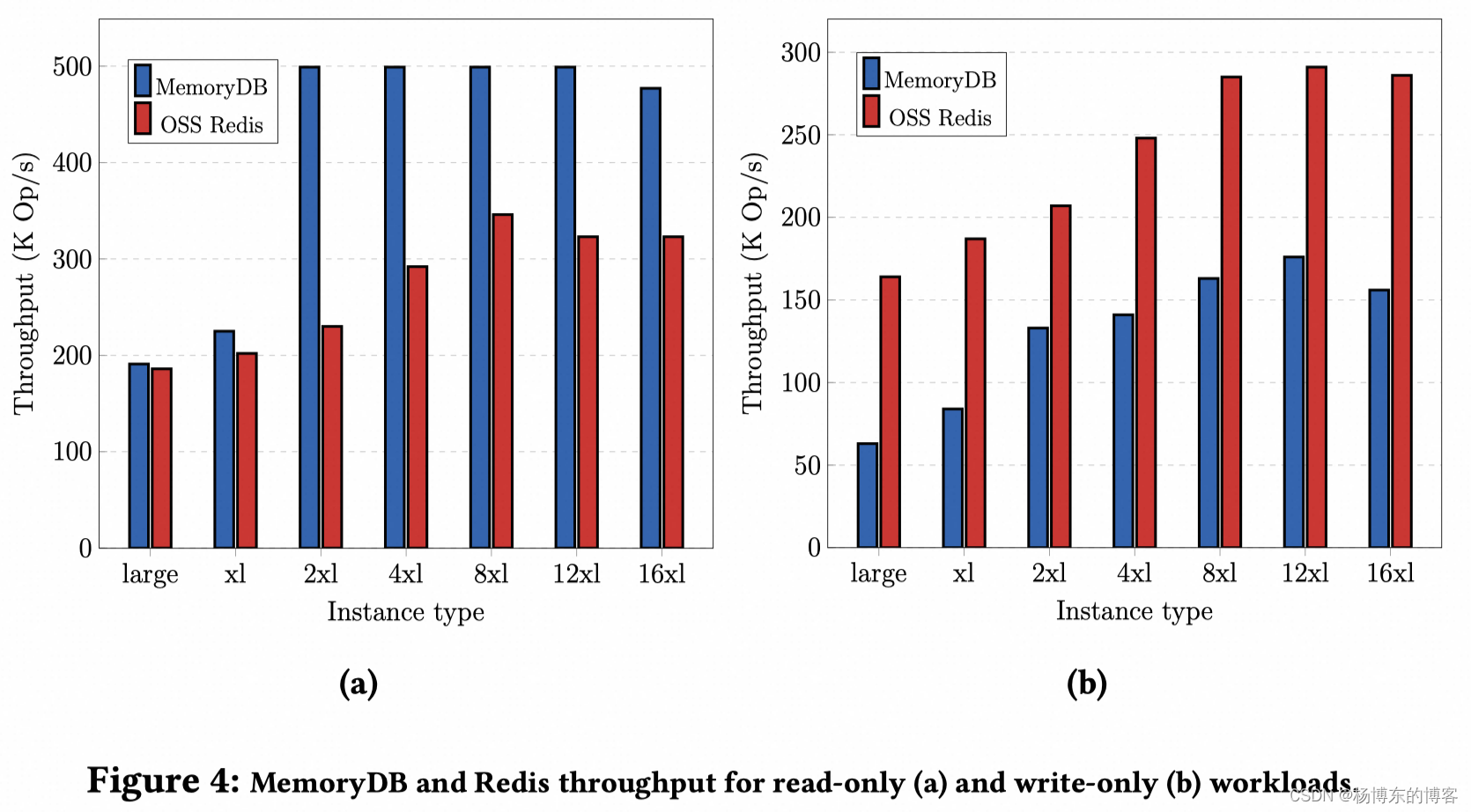
性能测试
Redis 版本:7.0.7
测试机器:10 ec2(和 MemoryDB 同 AZ)
key 数量:100w
key 大小:100bytes
开启多 IO:Redis 和 MemroyDB 相同数量。
-
纯读
-
QPS: MemoryDB 在 2X Large 之前比 Redis 高一点,之后会高比较多,原因是自己的 Multi IO 实现的比较好。
-
延迟:差不多。
-
-
纯写
-
QPS:MemoryDB 是 Redis 的一半左右。
-
延迟:MemroyDB 是 Redis 的五倍。
-
-
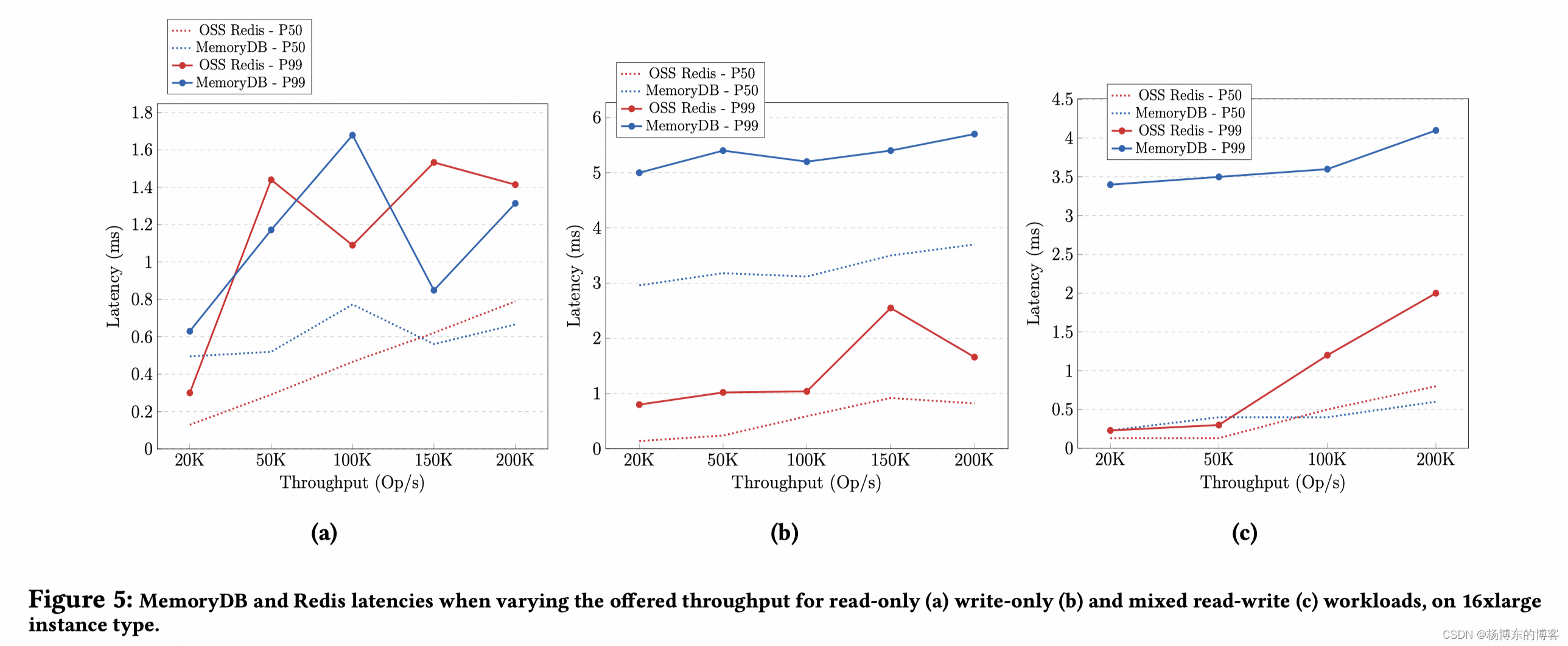
混合负载,80%读,20%写。
- 延迟:MemoryDB 是 Redis 三倍左右。
备份 RDB 的影响
机型:2 vCPU,16GB RAM,maxmemory 配置 12g,相当于 Reserved 25%内存。
key 数量:2000w,value 500 bytes,大约 10g 数据量。
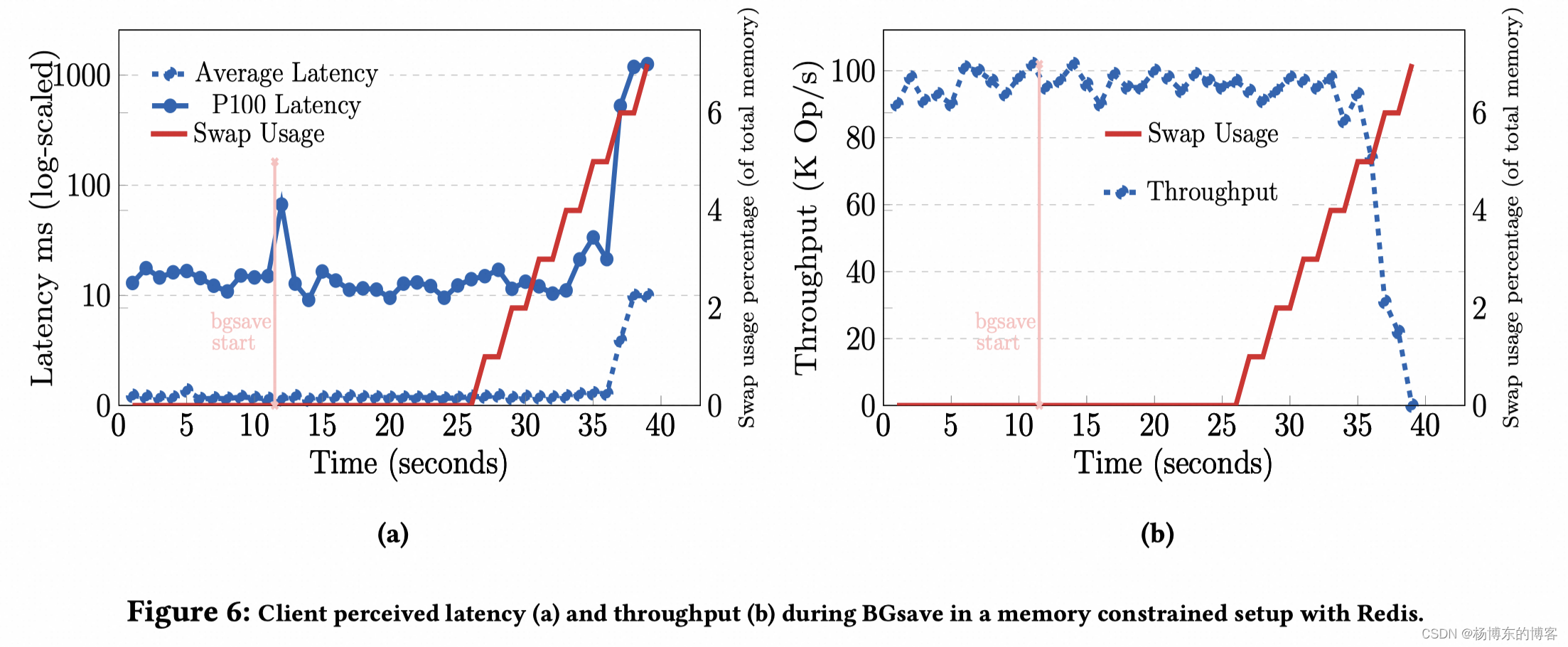
Redis 的表现,从开始 bgsave 之后,latency 会从 10 抖动到 70 左右,直到内存用完,开始交换 swap 之后,latency 会急剧恶化,到不可用的级别。
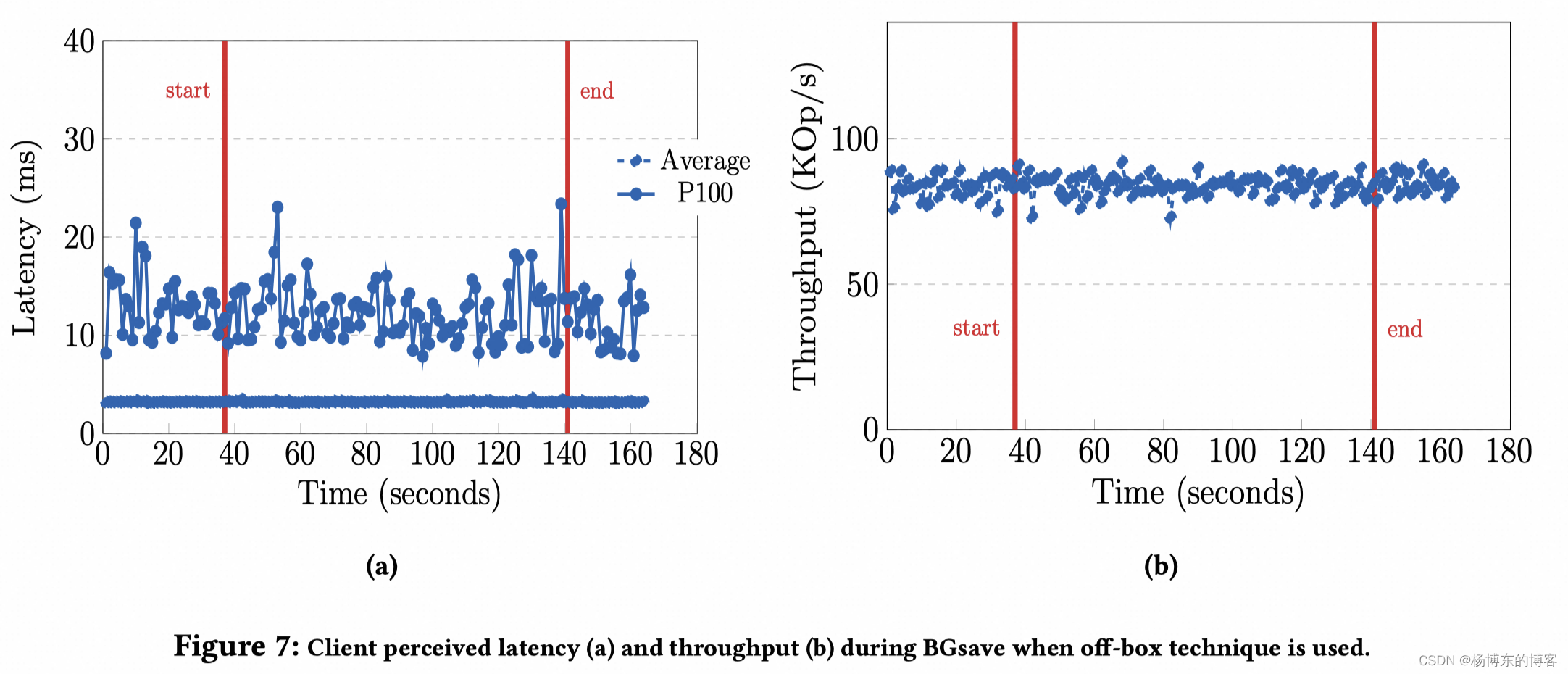
MemoryDB 利用 Off-box 节点来外部进行 SNAPSHOT 流程,延迟和吞吐不变。
一致性的其余考量
- 升级保护机制:当升级过程中,遇到不认识的 binlog 怎么办?
默认升级过程会先升级备,最后升级主,但是假设此时正有一个 replica 被加入,却用了旧版本,新的主升级完成之后发送的 binlog 这个备不会处理。因为 binlog 上面会表示这个流是来自于那个引擎版本的。这里不会主动 crash 或者默认加载,防止后续出问题。
- Snapshot 校验机制:
MemoryDB 维护整个事务日志的运行校验和,并定期将当前校验和值写入事务日志,off-box 节点启动之后,下载快照,首先通过加载快照数据对比其文件中记录的校验和,然后找到快照中记录的 binlog 位置,从 binlog 位置开始 load,并且继续计算校验和,并最终和 load 到的最新日志进行对比。
- 一致性验证(这部分想了解但提及较少):